标签:设置 异步 eureka 依赖项 yam ssl sample 不用 start
这篇文章我们针对上篇链路跟踪的遗留问题进行改造升级
默认情况下zipkin将收集到的数据存放在内存中(In-Memeroy),但是不可避免带来了几个问题:
通常做法是与mysql或者ElasticSearch结合使用,那么我们先把收集到的数据先存到Mysql数据库中
gradle配置:

dependencies { compile(‘org.springframework.cloud:spring-cloud-starter-eureka‘) compile(‘org.springframework.cloud:spring-cloud-starter-config‘) // compile(‘io.zipkin.java:zipkin-server‘) compile ‘org.springframework.cloud:spring-cloud-starter-sleuth‘ compile(‘io.zipkin.java:zipkin-autoconfigure-ui‘) runtime(‘mysql:mysql-connector-java‘) compile(‘org.springframework.boot:spring-boot-starter-jdbc‘) compile(‘org.springframework.cloud:spring-cloud-sleuth-zipkin-stream‘) compile(‘org.springframework.cloud:spring-cloud-stream‘) compile(‘org.springframework.cloud:spring-cloud-stream-binder-kafka‘) }
这里将原先的 io.zipkin.java:zipkin-server 替换为 spring-cloud-sleuth-zipkin-stream 该依赖项包含了对mysql存储的支持,同时添加spring-boot-starter-jdbc与mysql的依赖,顺便把kafka的支持也加进来
注意:此处脚本最好在数据库中执行一下,当然我们也可以在下面的配置文件中做初始化的相关配置
spring: datasource: username: root password: root url: jdbc:mysql://localhost:3306/myschool?characterEncoding=utf-8&useSSL=false initialize: true continue-on-error: true kafka: bootstrap-servers: localhost:9092 server: port: 9000 zipkin: storage: type: mysql
注意zipkin.storage.type 指定为mysql
package com.hzgj.lyrk.zipkin.server; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer; @EnableZipkinStreamServer @SpringBootApplication public class ZipkinServerApplication { public static void main(String[] args) { SpringApplication.run(ZipkinServerApplication.class, args); } }
这里注意将@EnableZipkinServer改成@EnableZipkinStreamServer
这步改造主要用以提高性能与稳定性,服务将收集到的span无脑的往消息中间件上丢就可以了,不用管zipkin的地址在哪里。
gradle:
compile(‘org.springframework.cloud:spring-cloud-starter-eureka-server‘) // compile(‘org.springframework.cloud:spring-cloud-sleuth-zipkin‘) compile ‘org.springframework.cloud:spring-cloud-starter-sleuth‘ compile ‘org.springframework.cloud:spring-cloud-sleuth-stream‘ compile(‘org.springframework.cloud:spring-cloud-starter-config‘) compile(‘org.springframework.cloud:spring-cloud-stream‘) compile(‘org.springframework.cloud:spring-cloud-stream-binder-kafka‘) compile(‘org.springframework.kafka:spring-kafka‘) compile(‘org.springframework.cloud:spring-cloud-starter-bus-kafka‘)
这里把原先的spring-cloud-sleuth-zipkin改成spring-cloud-sleuth-stream,不用猜里面一定是基于spring-cloud-stream实现的
server: port: 8100 logging: level: org.springframework.cloud.sleuth: DEBUG spring: sleuth: sampler: percentage: 1.0
注意:这里设置低采样率会导致span的丢弃。我们同时设置sleuth的日志输出为debug
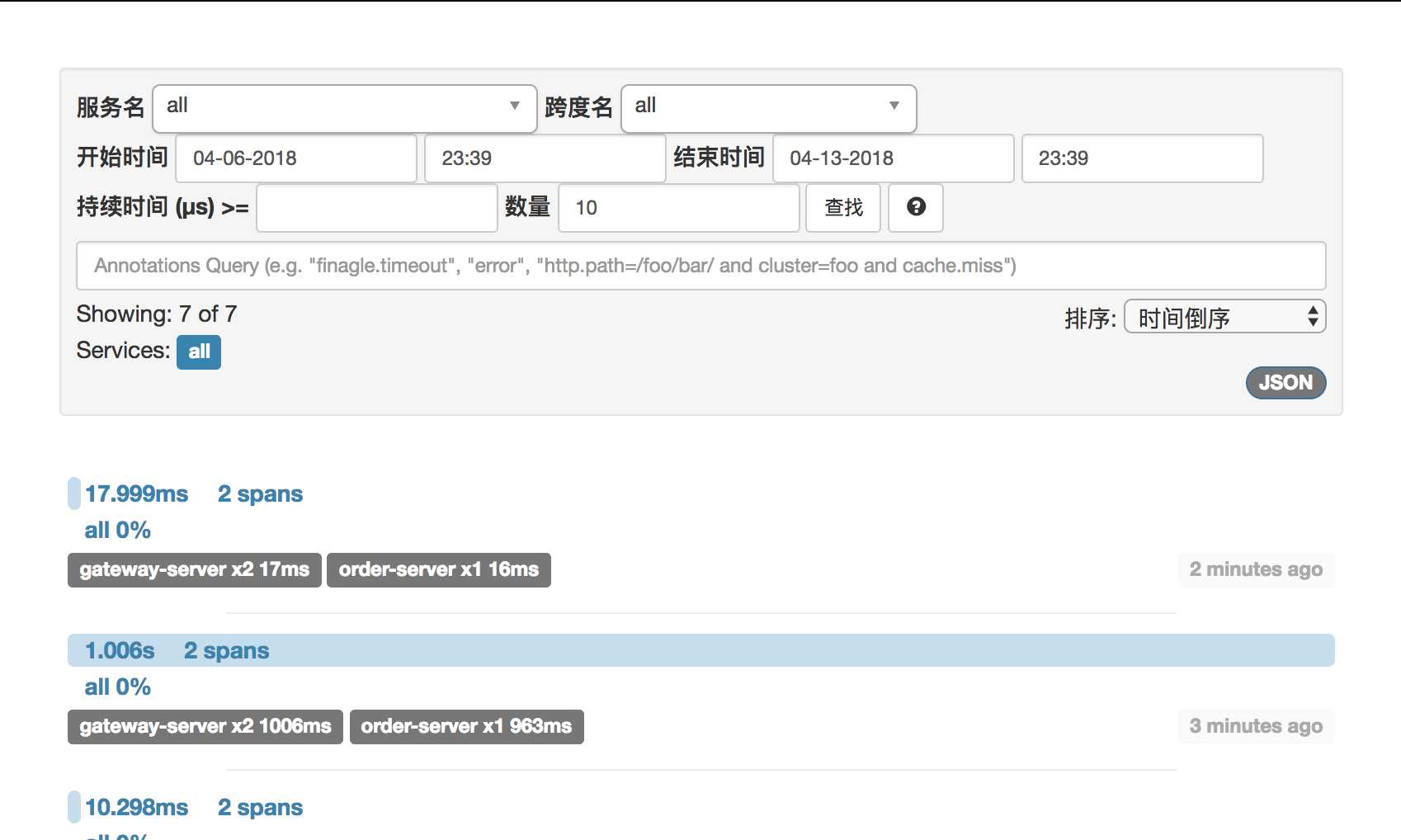
数据库里的相关数据:

SpringCloud学习之sleuth&zipkin【二】
标签:设置 异步 eureka 依赖项 yam ssl sample 不用 start
原文地址:https://www.cnblogs.com/niechen/p/8824813.html
