标签:机制 备份 png 管理 一个 block 内存数据 信息 数据信息
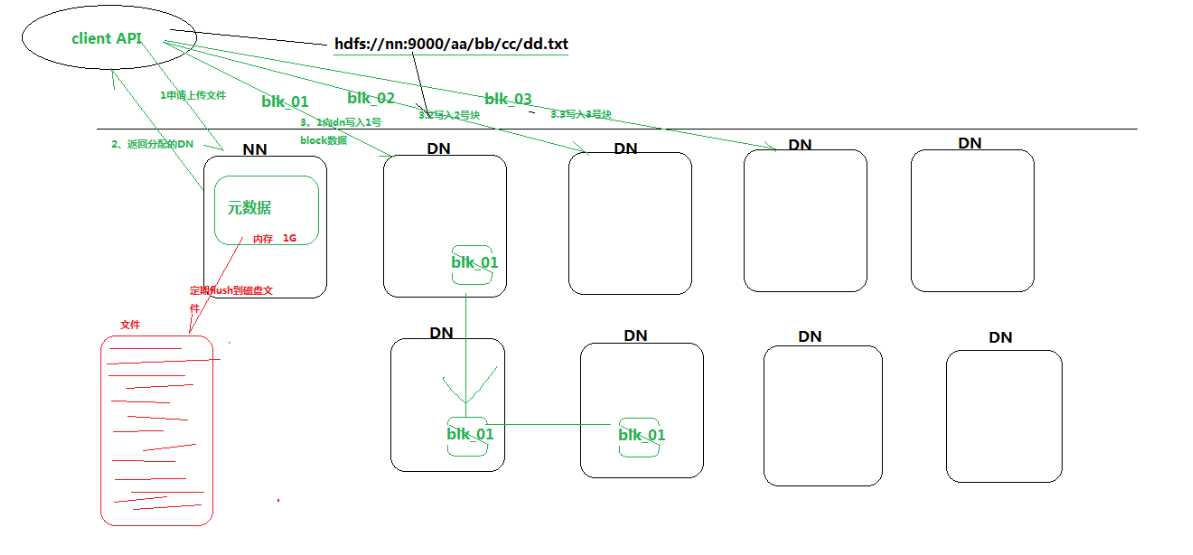
文件上传过程:
1.客户端想NameNode申请上传文件,
2.NameNode返回此次上传的分配DataNode情况给客户端
3.客户端开始依向dataName上传对应的block数据块。
4.上传完成之后通知namenode,namenode利用pipe管道机制进行文件的备份,也就是一个集群中文件有好几个副本。
5.如果备份失败会将失败信息返回给namenode然后重新分配备节点,并利用pipe管道备份文件
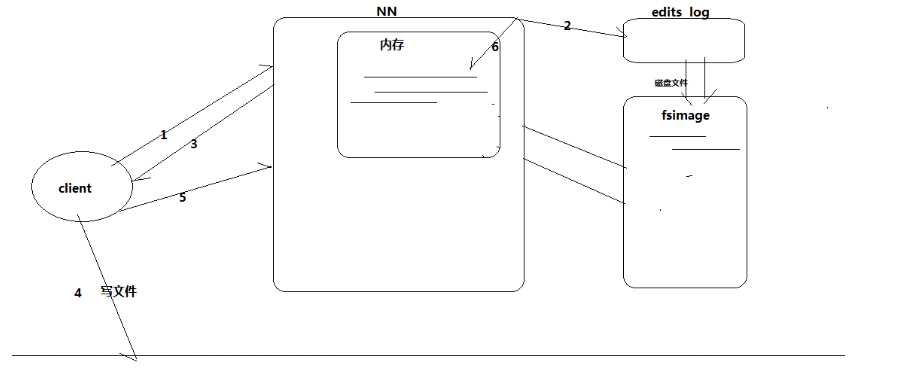
过程:
1.客户端上传文件时,首先向NameNode申请上传文件
2.NameNode首先往edit logs记录元数据操作日志(也就是记录block分配情况等数据)
3.NameNode将文件上传分配blk情况返回给客户端
4.客户端向dateNode上传文件
5.上传成功之后,客户端通知namenode文件上传完成
6.namenode将本次分配的日志信息读取到内存中(内存中记录最新的文件上传的元数据),
7.为了防止内存数据丢失,需要将元数据进行持久化操作。每当editlogs快要写满时将这一段时间的log写入到fsimage中
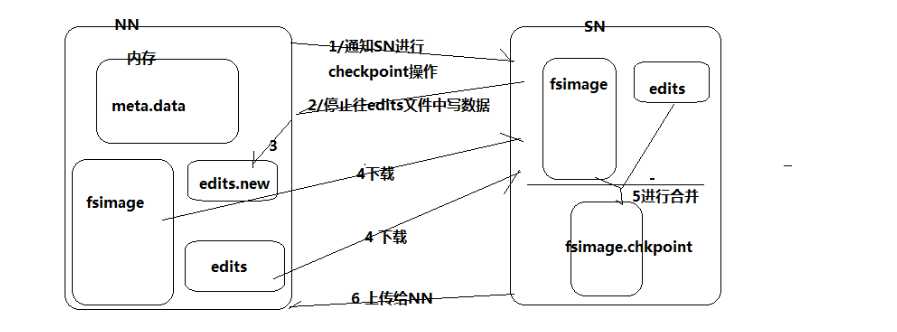
过程:(为了防止进行editlog和fsimage合并浪费内存,因此将合并文件的操作在secondnode中进行)
1.当editlogs快要满的时候namenode通知secondnode进程checkpoint操作(合并操作)
2.secondnode收到通知后通知namenode停止向editlogs写日志,
3.此时为了不影响客户端继续上传文件,namenode新创一个文件叫做edits.new记录代替editlogs记录日志操作
4.secondnode将fsimage和editlogs下载进行合并,由于hadoop集成了jetty插件,因此通过http协议下载文件
5.下载完成之后secondnode利用自己的CPU,将editlogs按照fsimage的格式进行计算之后合并到fsimage完成合并,并将文件重命名为fsimage.chkpoint
6.合并完成之后上传给namenode。namenode删除原来的fsimage和edits,并将edits.new重命名为editlogs,将fsimage.chkpoint重新命名为fsimage。就可以进行正常的hdfs机制
(1)上面的机制就保证断点之后fsimage有大部分的元数据信息,editlogs有最新的元数据信息,内存中也有最新的元数据信息,这样断电之后也不会丢失数据。同时客户端查询数据的时候也会从内存中读取而不会影响速度。
(2)NameNode的作用:
标签:机制 备份 png 管理 一个 block 内存数据 信息 数据信息
原文地址:https://www.cnblogs.com/qlqwjy/p/8831248.html