标签:字体 lse coding 素材 web 分享 重复 accept agent
大数据时代,数据对我们来说就是一笔宝贵的财富,以机器翻译来说,第一步呢需要收集目前大量的中英文翻译的原句子,而这些句子我们应该去哪里得到呢?最简单、最直接、最有效、最现成的办法就是去爬取。由于之前没有做过类似的东西,所以打算使用强悍的python辅助我。
首先选定了要爬取的网站 http://news.iyuba.com/ ,一个非常炫酷的双语网站。
首先我们发现,这一页并没有我们直接需要的中英文的素材,而是点击了导航栏上了各大分类,再进入具体的分类页后,再次点击具体的内容,才会有中英文互译的文章,我们的爬取思路如下:
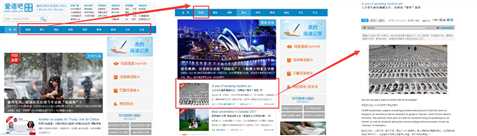
思路:首页先得到进入各个分类的页面的url,其次在分类页面爬取出当前页面所有文章的url,最后进入文章获得中英文素材。
首先我们需要查看一下网页的源代码,将导航栏处的源代码找到,提取看它是否有什么特征。我们的做法是点击右键,查看源代码:
经过仔细的查找,我们找到了其中的对应关系:
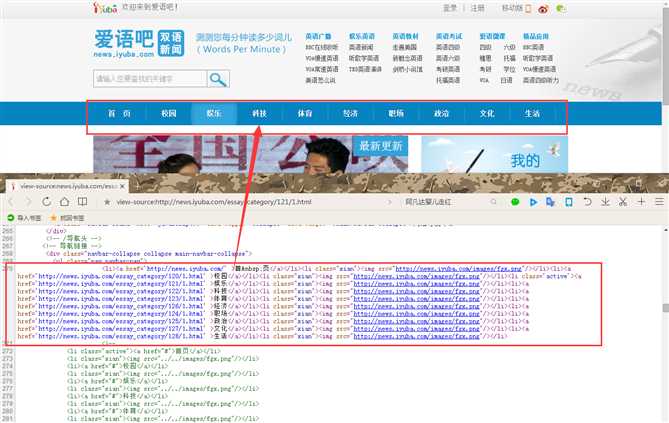
那么接下来要做的就是解析html了。
经过查阅资料,python解析html有现成的BeautifulSoup库比较强大,所以第一步安装这个强大的库,这里我的python版本是2.7,进入python的安装目录后,使用pip进行安装:
学习了一些简单的api用法之后,直接开始上手实践:
#print soup.title 找到title的标签,例如<title>标题内容</title> #print soup.title.string 将title标签中的内容输出,例如“标题内容” #print soup.p 输出所有p标签的第一个,如果想找所有的,使用find_all(‘p‘) #print soup.find(id="search_button") 找到id是指定id的标签 #print soup.get_text().encode(‘utf-8‘) 得到所有内容
第一步实现的代码如下:

#-*- coding:utf-8 -*-
import urllib2
from bs4 import BeautifulSoup
import re
# 要爬取的总url
weburl=‘http://news.iyuba.com/‘
class Climbing():
# 设置代理开关
enable_proxy = True
# 总url
url = ‘‘
# 初始化
def __init__(self, url):
self.url = url
proxy_handler = urllib2.ProxyHandler({"http" : ‘web-proxy.oa.com:8080‘})
null_proxy_handler = urllib2.ProxyHandler({})
if self.enable_proxy:
opener = urllib2.build_opener(proxy_handler)
else:
opener = urllib2.build_opener(null_proxy_handler)
urllib2.install_opener(opener)
# 根据url,得到请求返回内容的soup对象
def __getResponseSoup(self, url):
request = urllib2.Request(url)
#request.add_header(‘User-Agent‘, "Mozilla/5.0")
#request.add_header(‘Accept-Language‘, ‘zh-ch,zh;q=0.5‘)
response = urllib2.urlopen(request)
resault = response.read()
soup = BeautifulSoup(resault, "html.parser")
return soup
# 首页中抓去到各个分类的url
def getCategoryUrl(self):
soup = self.__getResponseSoup(self.url)
allinfo = soup.find_all(‘ul‘, attrs={"class": "nav navbar-nav"})[0].find_all(‘a‘)
for info in allinfo:
chinese = info.get_text().encode(‘utf-8‘)
href = info.get(‘href‘)
if href == self.url:
continue
print chinese, href
c = Climbing(weburl)
c.getCategoryUrl()
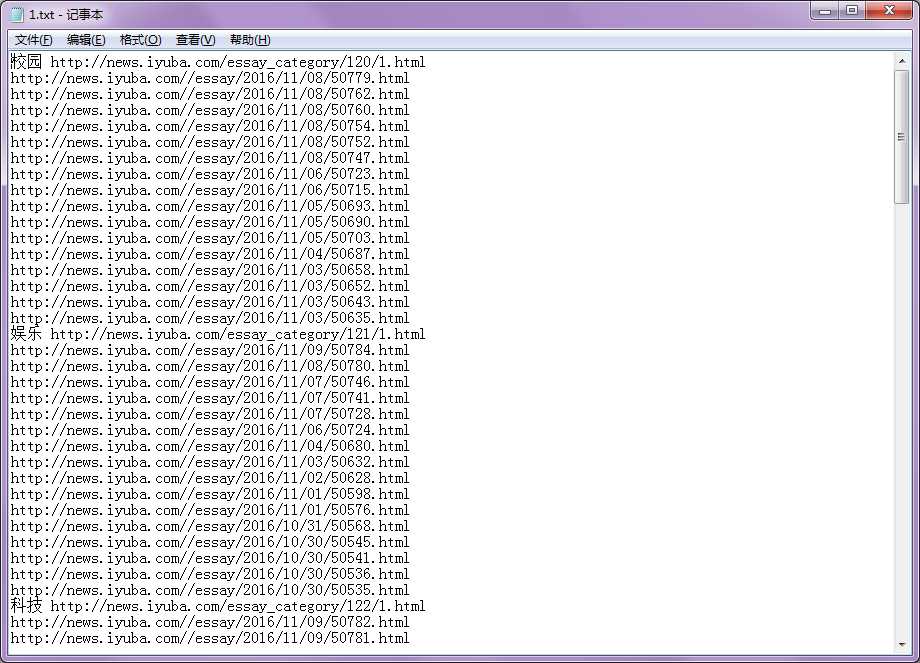
运行之后,输出的内容为:
校园 http://news.iyuba.com/essay_category/120/1.html
娱乐 http://news.iyuba.com/essay_category/121/1.html
科技 http://news.iyuba.com/essay_category/122/1.html
体育 http://news.iyuba.com/essay_category/123/1.html
经济 http://news.iyuba.com/essay_category/126/1.html
职场 http://news.iyuba.com/essay_category/124/1.html
政治 http://news.iyuba.com/essay_category/125/1.html
文化 http://news.iyuba.com/essay_category/127/1.html
生活 http://news.iyuba.com/essay_category/128/1.html
可以看到各个分类的ur已经被我们轻松的拿下了,接下来我们再爬取各个分类url下的文章的url,使用到的代码如下:
# 继续解析分类url,得到具体文章的url
def getDetailUrl(self, Category, url):
print Category,url
soup = self.__getResponseSoup(url)
otherurl = soup.find_all(‘a‘, attrs={"target": "_blank"})
for info in otherurl:
tmp = info.find(re.compile("^b"))
if tmp:
detailurl = self.url + info.get(‘href‘)
print detailurl
运行之后,得到的结果是:
得到具体的文章的url之后,接下来就是最后一步,抓取出每个url内容中的中英文,使用同样类似的方法,代码如下:
# 根据具体的url去拿翻译的数据
def getTranslateContent(self, url):
print ‘*************** ‘+url
soup = self.__getResponseSoup(url)
all = soup.find_all(‘p‘, attrs={"ondblclick": "javascript:doExplain();"})
for words in all:
print words.get_text().encode(‘utf-8‘)
all = soup.find_all(‘p‘, attrs={"class": "p2"})
for words in all:
print words.get_text().encode(‘utf-8‘)
输出的结果是:

其实这样的爬取根本不够,因为每个分类我只是抓取了第一页的文章链接,而我需要的是把整个站点的所有内容全部抓取下来,因此每个需要都需要翻页去抓取,翻页的个数不确定,因此只能设置一个阈值,然后去试,直到出现了404页面。当然整个翻译的过程中还需要去重一些url,即使用这样的方式还是会存在一些重复的url,从log里就可以看出来:
最后附上最终的代码吧:
 reptile.py Torepeat.py Log.py
reptile.py Torepeat.py Log.py最终这些代码,一共帮我爬取了6908篇文章,7w+中英文翻译内容:
当然在这过程中也踩了不少坑,这里列举几个:
问题一:在notepad++中打开抓取的韩文内容显示乱码,但是windows记事本可以显示,最终查明是notepad++使用的字体中没有韩文的库。
问题二:抓取某些网站时候,抓取下来乱码,这里需要指定BeautifulSoup(resault, "html.parser", from_encoding=‘UTF-8‘)的第三个参数与指定网页的编码格式一样即可
问题三:在构造url的时候,有时候带着中文上去,Url会帮你把转化为( ‘你好‘转为‘%E4%BD%A0%E5%A5%BD‘),有时候需要手动把中文转为这样的格式,在python中使用urllib.quote(keyword)来进行,相反%字符转中文使用unquote。
问题四:有些网址,浏览器里url可以访问,但是使用python会返回 ,原因是需要设置ua,这里需要在代码处添加:
,原因是需要设置ua,这里需要在代码处添加:
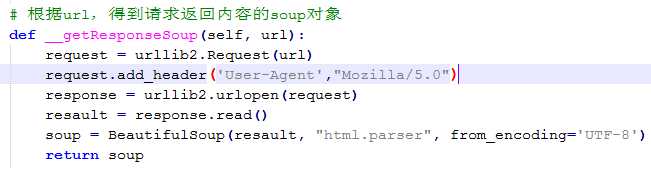
问题五:有些网页源码当中如下格式
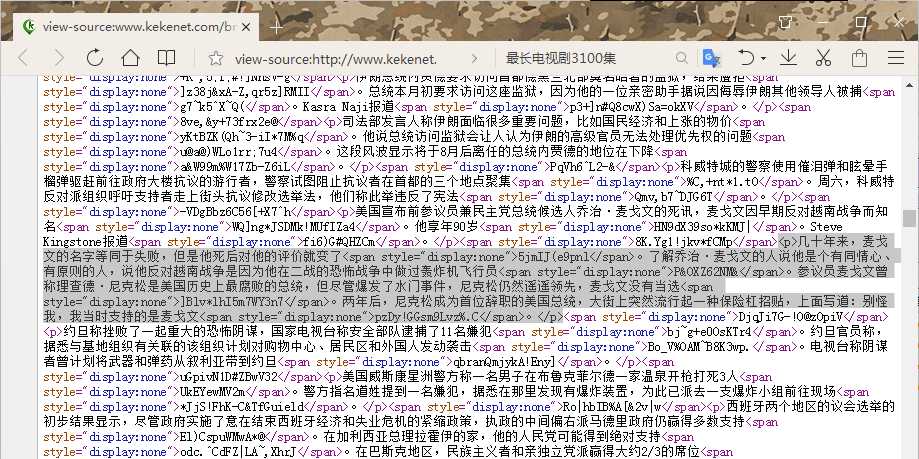
需要剔除的话,可以使用下面的命令:
标签:字体 lse coding 素材 web 分享 重复 accept agent
原文地址:https://www.cnblogs.com/ht22ht22/p/8870097.html