标签:content 服务器 big ace draft 帮助 end editor 重绘
在web2.0之前,写jsp的时候虽然有es和JSTL,但是还是坚持jsp。后面在外包公司为了快速交货,还是用了php Smart技术。
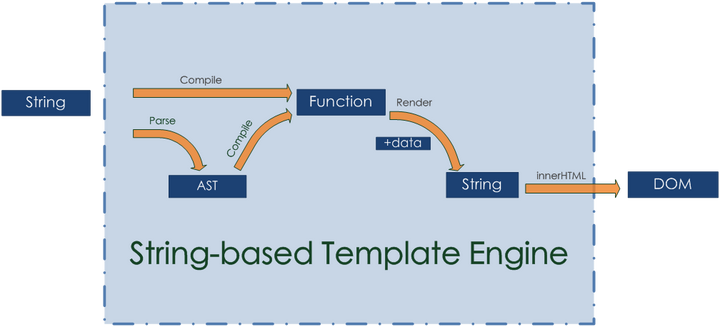
String-based模板技术(基于字符串的parse和compile过程)
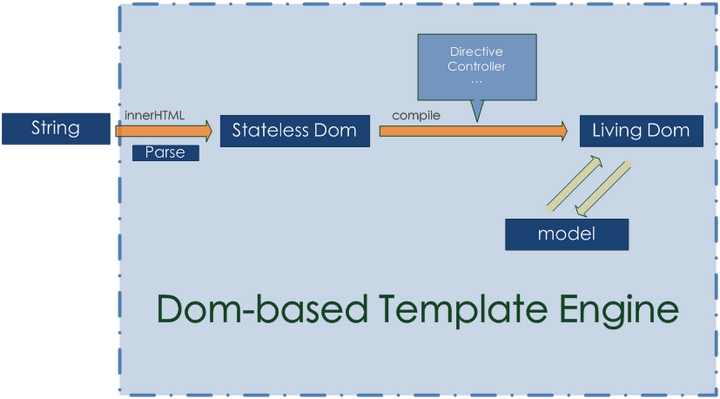
DOM-based模板技术(基于Dom的link或compile过程)
Living template (基于字符串的parse 和 基于dom的compile过程)
String-based templating
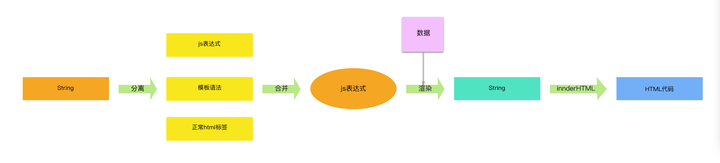
这是一种基于字符串的模板技术,以字符串和数据为输入,通过用正则表达式将占位符替换为所需数据的方式,构建出完整的 HTML 字符串。
字符串模板引擎主要依赖一下这几个dom API:createElement,appendChild,innerHTML。
在这些api中,innerHTML有最佳的可读性与实用性,成为事实上的主要标准,虽然其他API可能在性能上更胜一筹,但原生js的字符串生成方案中,最常用的还是innerHTML。
基于字符串的模板引擎最大的功劳就是把你从大量的夹带逻辑的字符串拼接中解放出来了,由于它的完全基于字符串的特性,它拥有一些无可替代的优势。
It is essentially a way to address the need to populate an HTML view with data in a better way than having to write a big, ugly string concatenation expression.
-
快速的初始化时间: 很多angular的簇拥者在奚落String-based templating似乎遗漏了这一点。
-
同构性: 完全的dom-independent,即可作为用服务器端和浏览器端(客官先不要急着搬phantomjs哈).
-
更强大的语法支持:因为它们都是不是自建DSL就是基于JavaScript语法,Parser的灵活性与受限于HTML的Dom-based模板技术不可同日而语
由于基于字符串的模板方法依赖于innerHTML的渲染,所以会带来以下问题。
,我知道像你这样优秀的程序员不会写出这样的代码,但当html片段不完全由你来控制时(比如从远程服务器中),这会成为一个可能引爆的炸弹。
-
性能问题:使用innerHTML 替换 DOM效率较低,即使仅替换 DOM 的一个属性或文本内容,也必须通过innerHTML 替换整个 DOM,从而导致浏览器的重排和重绘。
-
开发效率问题:由于是通过正则表达式匹配后在特定函数中拼接字符串,所以容易造成重复计算,而且完全移除现有的 DOM,再重新渲染一遍,挂载在 DOM 上的事件和状态都将不复存
-
有可能会创建出意料之外的节点:由于html的parser非常的“友好”, 以至于它接受并不规范的写法,从而创建出意料之外的结构,而开发者得不到错误提示。
DOM-based模板技术
这是一种基于 DOM 节点的模板技术,通过innerHTML获取初始 DOM 结构,再通过 DOM API层级从原始 DOM 属性中提取事件、指令、表达式和过滤器等信息,编译成 LivingDOM,从而完成数据 Model和 View 的双向绑定。 AngularJS就是 DOM-based模板技术的代表。
Dom-based的模板技术事实上并没有完整的parse的过程(先抛开表达式不说),如果你需要从一段字符串创建出一个view,你必然通过innerHTML来获得初始Dom结构. 然后引擎会利用Dom API(attributes,getAttribute,firstChild… etc)层级的从这个原始Dom的属性中提取指令、事件等信息,继而完成数据与View的绑定,使其”活动化”。
所以Dom-based的模板技术更像是一个数据与dom之间的“链接”和*“改写”*过程。
注意,dom-based的模板技术不一定要使用innerHTML,比如所有模板都是写在入口页面中时, 但是此时parse过程仍然是浏览器所为。
DOM-based模板技术比String-based模板技术更加灵活,功能也更加强大,达到了一定意义上的数据驱动。
由于 DOM-based模板技术通过innerHTML 获取 DOM 编译节点,信息承载于属性中,造成了不必要的冗余,同时也会影响阅读,提升开发难度。一种解决办法就是通过读取属性后再进行删除处理,诸如removeAttribute的方式移除它们,其实这个不一定必要,而且其实并无解决它们Dom强依赖的特性,还会影响性能,降低用户体验。
-
初始节点获取问题:通过innerHTML获取初始节点,没有独立的语法解析器或词法解析器,与 HTML是强依赖关系。初次进入 DOM 的内容是模板,渲染需要时间,所以会造成内容闪动——FOUC(Flash of unstyled content)这个无需多说了,只怪它初次进入dom的内容并不是最终想要的内容。
-
没有独立的Parser,必须通过innerHTML(或首屏)获取初始节点,即它的语法是强依赖与HTML,这也导致它有潜在的安全问题
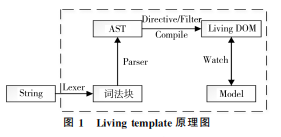
Livingtemplate技术
Livingtemplate技术与String-based、DOM-based模板技术的最大区别是不依赖innerHTML来渲染和提取所需信息。其主要思想是:首先,结合数据绑定技术,使用成熟的词法解析和语法解析
技术,将输入的字符串解析成抽象语法树AST,而不是仅仅通过简单的正则表达式匹配特定语法,再进行字符串拼接;其次,通过对 AST进行编译,创建具有数据动态绑定功能的 Living DOM,从而避免使用innerHTML,解决了浏览器的元素闪动问题,提高了应用的安全性,其原理如图1所示。
从图1可知,输入的字符串通过词法解析器Lexer,生成对应的词法块。词法块通过语法解析器 Parser,构建抽 象 语 法 树 AST。然 后 将 AST编译成具有动态数据绑定功能的LivingDOM,从而实现 View 和 Model的双向绑定。
与Dom-based 模板技术利用Dom节点承载信息所不同的是,它的中间产物AST 承载了所有Compile过程中需要的信息(语句, 指令, 属性…等等).
我们可以发现Living templating几乎同时拥有String-based和Dom-based模板技术的优点
利用一个如字符串模板的自定义DSL来描述结构来达到了语法上的灵活性,并在Parse后承载信息(AST)。而在Compile阶段,利用AST和Dom API来完成View的组装,在组装过程中,我们同样可以引入Dom-based模板技术的诸如Directive等优良的种子。
living template’s 近亲 —— React
React当然也可以称之为一种模板解决方案,它同样也巧妙规避了innerHTML,不过却使用的是截然不同的策略:react使用一种virtual dom的技术,它也同样基于脏检查,不过与众不同的是,它的脏检查发生在view层面,即发生在virtual dom上,从而可以以较小的开销来实现局部更新。
-
轻量级, 在Dom中进行读写操作是低效的.
-
可重用的.
-
可序列化, 你可以在本地或服务器端预处理这个过程。
-
安全, 因为安全不需要innerHTML帮我们生成初始Dom
此文还需进一步整理,以及自定义模板引擎思考方向与工程实践内容补充。这方面需要下的功夫还是需要蛮多的,敬请期待。
转载请注明来源《再谈前端HTML模板技术》以及参考文档引用链接。本文如有侵权及不妥之处,敬请通知本人修改,此文还是初稿状态。谢谢
再谈前端HTML模板技术
标签:content 服务器 big ace draft 帮助 end editor 重绘
原文地址:https://www.cnblogs.com/zhoulujun/p/8893300.html