标签:headers get 生成 提取 tail header 字段 img 没有
requests、Beautiful Soup、MongoDB
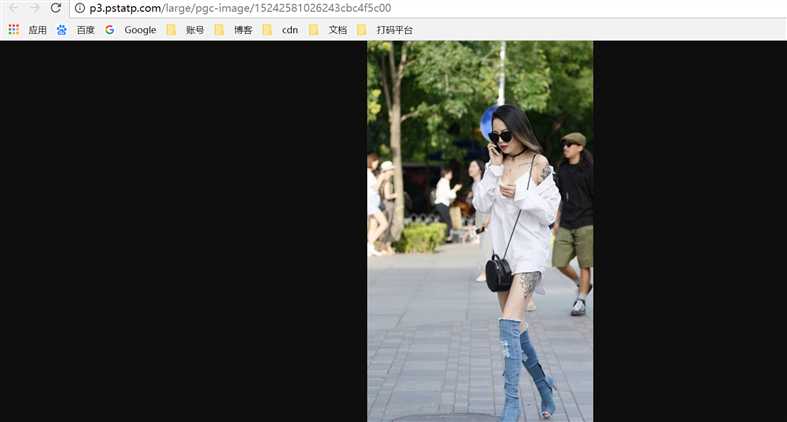
在抓取之前首先分析抓取的逻辑,打开今日头条的首页https://www.toutiao.com/如图
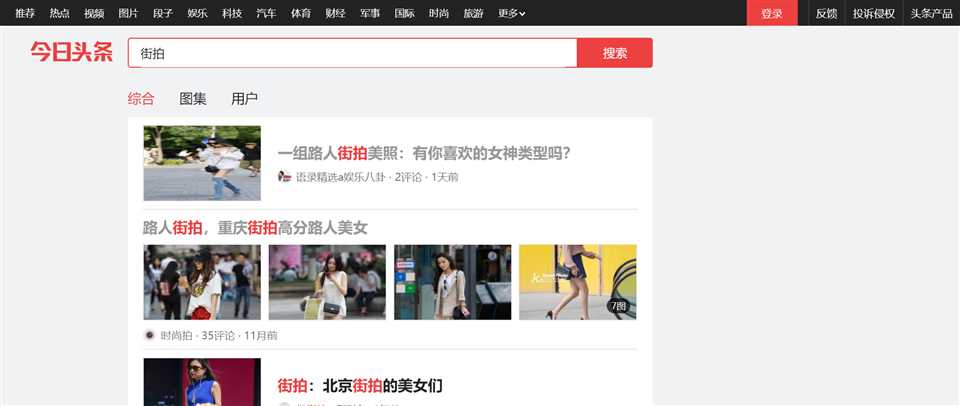
右上角有一个搜索入口,这里尝试抓取街拍美图,所有输入“街拍”二字,搜索一下,结果如下图所示:
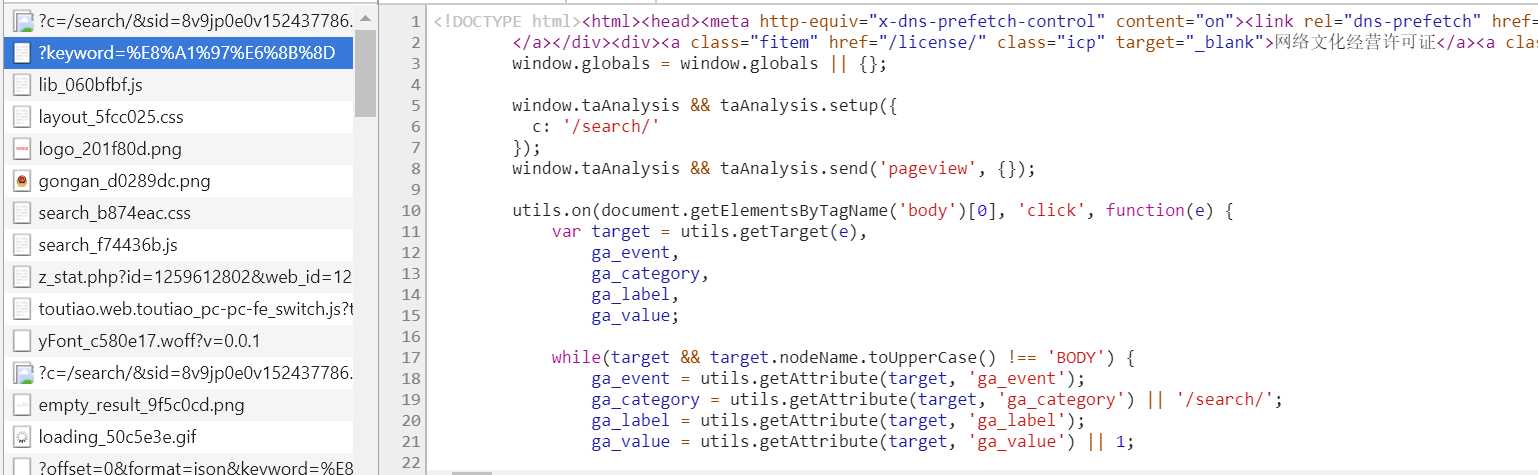
这时打开发者工具,查看所有网络请求,首先打开第一个网络请求,这个请求的URL就是当前的链接:https://www.toutiao.com/search/?keyword=街拍,

刷新一下界面,查看响应结果,如下没有找到页面上的内容
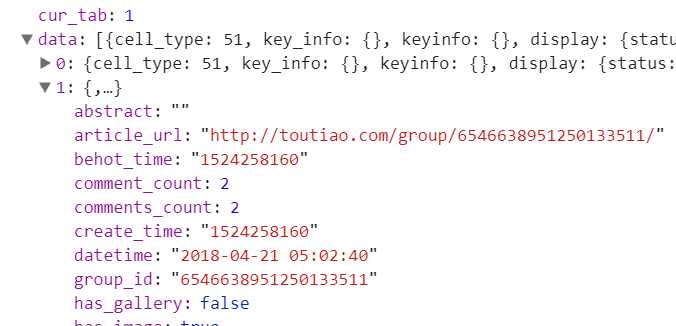
切换到XHR查看,找到了我们需要的信息
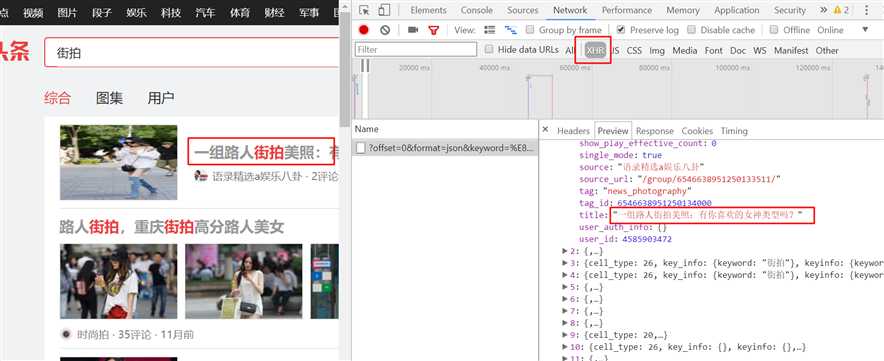
article_url就是内容详细的链接
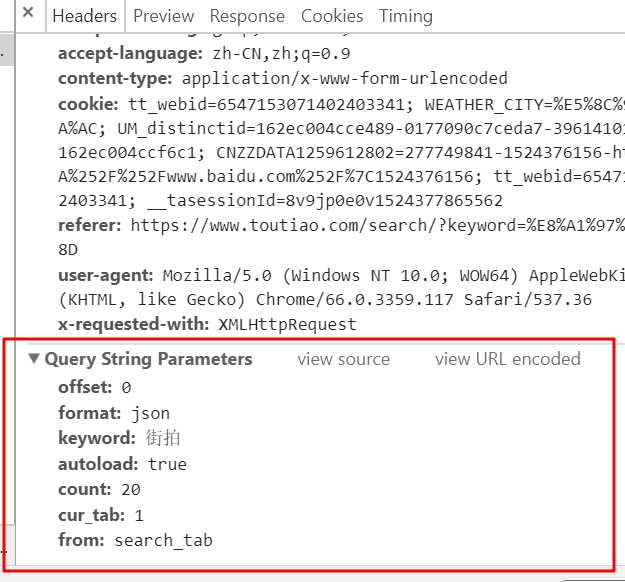
再看一下Headers,这是我们需要构造的请求参数
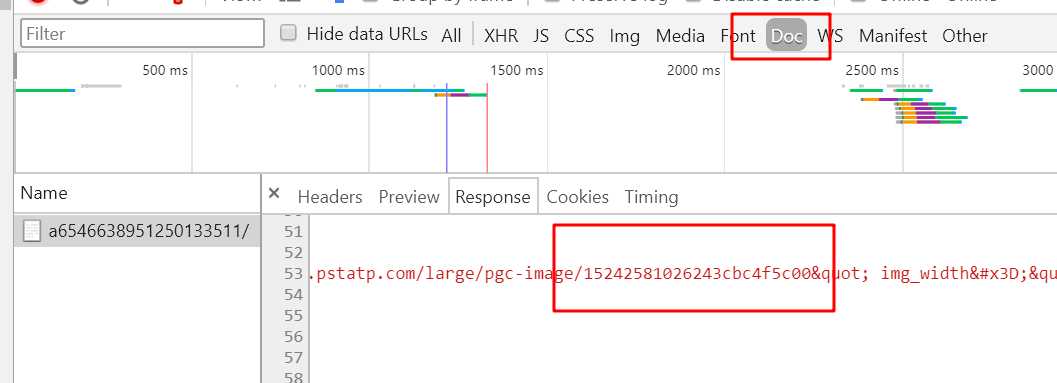
进入内容详细页查看响应信息,找到了每个图片链接的页面是在Doc:
刚才分析了Ajax请求的逻辑,下面就用程序来实现美图下载吧。
首先,实现方法get_page()来加载单个ajax请求的结果。其中唯一变化的参数就是offset,所以我们将它当作参数传递,实现如下:
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
‘offset‘: offset,
‘format‘: ‘json‘,
‘keyword‘: ‘街拍‘,
‘autoload‘: ‘true‘,
‘count‘: ‘20‘,
‘cur_tab‘: ‘1‘
}
url = ‘https://www.toutiao.com/search_content/?‘ + urlencode(params)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们用urlencode()方法构造请求的GRT参数,然后用requests请求这个链接,如果返回状态码为200,则调用response的json()方法将结果转为JSON格式,然后返回。
接下来,再实现一个解析方法,:提取每条数据 的image_detail字段中的每一张图片链接,将图片链接和图片所属的标题一并返回,此时可以构造一个生成器,实现代码如下:
标签:headers get 生成 提取 tail header 字段 img 没有
原文地址:https://www.cnblogs.com/0bug/p/8907262.html