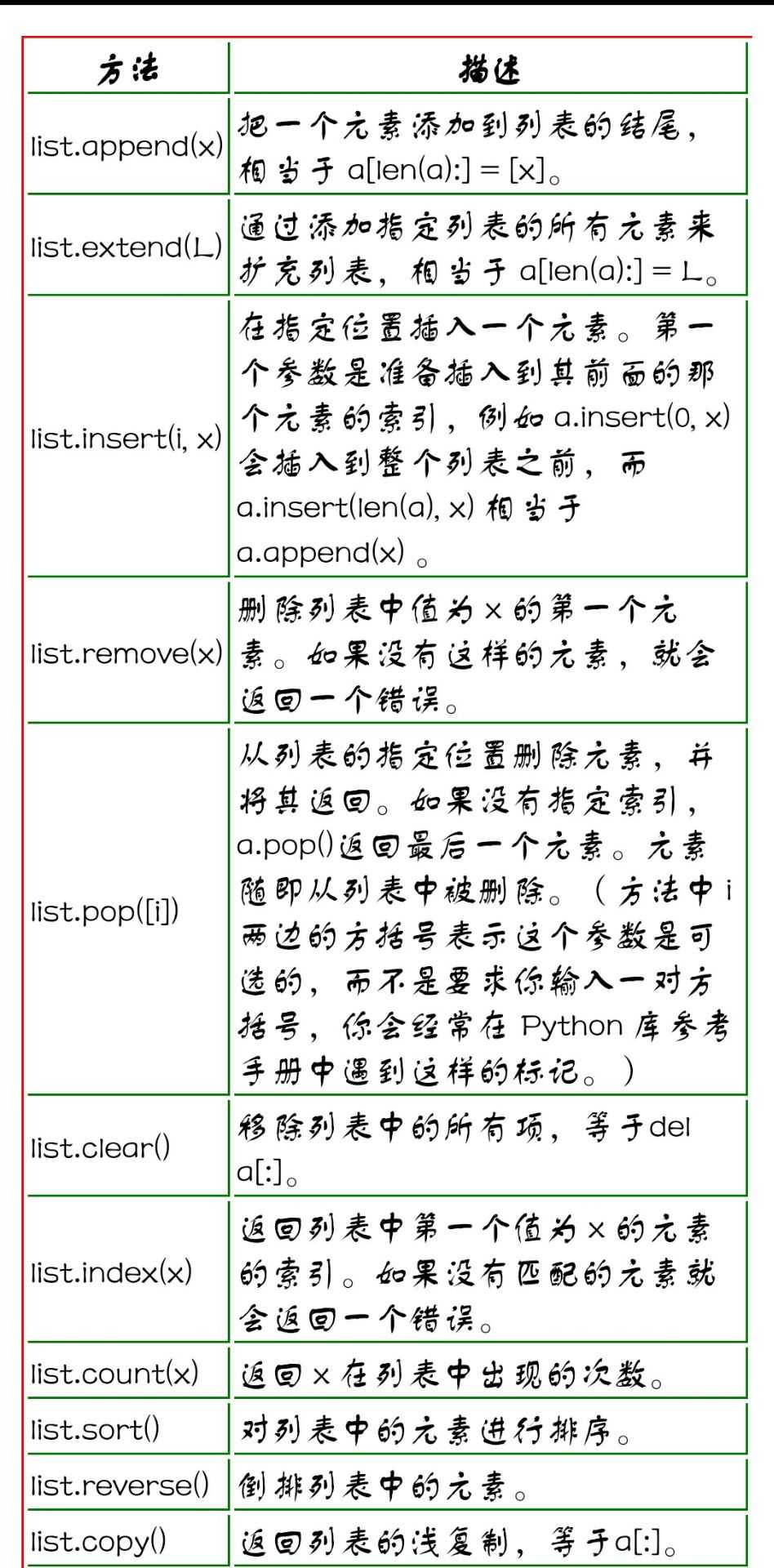
列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
这里我们将列表中每个数值乘三,获得一个新的列表:
>>> vec = [2, 4, 6]
>>> [3*x for x in vec]
[6, 12, 18]
现在我们玩一点小花样:
>>> [[x, x**2] for x in vec]
[[2, 4], [4, 16], [6, 36]]
这里我们对序列里每一个元素逐个调用某方法:
>>> freshfruit = [‘ banana‘, ‘ loganberry ‘, ‘passion fruit ‘]
>>> [weapon.strip() for weapon in freshfruit]
[‘banana‘, ‘loganberry‘, ‘passion fruit‘]
我们可以用 if 子句作为过滤器:
>>> [3*x for x in vec if x > 3]
[12, 18]
>>> [3*x for x in vec if x < 2]
[]
以下是一些关于循环和其它技巧的演示:
>>> vec1 = [2, 4, 6]
>>> vec2 = [4, 3, -9]
>>> [x*y for x in vec1 for y in vec2]
[8, 6, -18, 16, 12, -36, 24, 18, -54]
>>> [x+y for x in vec1 for y in vec2]
[6, 5, -7, 8, 7, -5, 10, 9, -3]
>>> [vec1[i]*vec2[i] for i in range(len(vec1))]
[8, 12, -54]
列表推导式可以使用复杂表达式或嵌套函数:
>>> [str(round(355/113, i)) for i in range(1, 6)]
[‘3.1‘, ‘3.14‘, ‘3.142‘, ‘3.1416‘, ‘3.14159‘]
嵌套列表解析
Python的列表还可以嵌套。以下实例展示了3X4的矩阵列表:
>>> matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
... ]
以下实例将3X4的矩阵列表转换为4X3列表:
>>> [[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
以下实例也可以使用以下方法来实现:
>>> transposed = []
>>> for i in range(4):
... transposed.append([row[i] for row in matrix])
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
另外一种实现方法:
>>> transposed = []
>>> for i in range(4):
... # the following 3 lines implement the nested listcomp
... transposed_row = []
... for row in matrix: ... transposed_row.append(row[i])
... transposed.append(transposed_row)
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
del 语句
使用 del 语句可以从一个列表中依索引而不是值来删除一个元素。这与使用 pop() 返回一个值不同。可以用 del 语句从列表中删除一个切割,或清空整个列表(我们以前介绍的方法是给该切割赋一个空列表)。例如:
>>> a = [-1, 1, 66.25, 333, 333, 1234.5]
>>> del a[0]
>>> a
[1, 66.25, 333, 333, 1234.5]
>>> del a[2:4]
>>> a
[1, 66.25, 1234.5]
>>> del a[:]
>>> a
[]
也可以用 del 删除实体变量:
>>> del a
元组和序列
元组由若干逗号分隔的值组成,例如:
>>> t = 12345, 54321, ‘hello!‘
>>> t[0]
12345
>>> t
(12345, 54321, ‘hello!‘)
>>> # Tuples may be nested:
... u = t, (1, 2, 3, 4, 5)
>>> u
((12345, 54321, ‘hello!‘), (1, 2, 3, 4, 5))
如你所见,元组在输出时总是有括号的,以便于正确表达嵌套结构。在输入时可能有或没有括号, 不过括号通常是必须的(如果元组是更大的表达式的一部分)。
集合
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。
可以用大括号({})创建集合。注意:如果要创建一个空集合,你必须用 set() 而不是 {} ;后者创建一个空的字典。
以下是一个简单的演示:
>>> basket = {‘apple‘, ‘orange‘, ‘apple‘, ‘pear‘, ‘orange‘, ‘banana‘}
>>> print(basket) # show that duplicates have been removed
{‘orange‘, ‘banana‘, ‘pear‘, ‘apple‘}
>>> ‘orange‘ in basket # fast membership testing
True
>>> ‘crabgrass‘ in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set(‘abracadabra‘)
>>> b = set(‘alacazam‘)
>>> a # unique letters in a
{‘a‘, ‘r‘, ‘b‘, ‘c‘, ‘d‘}
>>> a - b # letters in a but not in b
{‘r‘, ‘d‘, ‘b‘}
>>> a | b # letters in either a or b
{‘a‘, ‘c‘, ‘r‘, ‘d‘, ‘b‘, ‘m‘, ‘z‘, ‘l‘}
>>> a & b # letters in both a and b
{‘a‘, ‘c‘}
>>> a ^ b # letters in a or b but not both
{‘r‘, ‘d‘, ‘b‘, ‘m‘, ‘z‘, ‘l‘}
>>> basket = {‘apple‘, ‘orange‘, ‘apple‘, ‘pear‘, ‘orange‘, ‘banana‘}
>>> print(basket) # show that duplicates have been removed
{‘orange‘, ‘banana‘, ‘pear‘, ‘apple‘}
>>> ‘orange‘ in basket # fast membership testing
True
>>> ‘crabgrass‘ in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set(‘abracadabra‘)
>>> b = set(‘alacazam‘)
>>> a # unique letters in a
{‘a‘, ‘r‘, ‘b‘, ‘c‘, ‘d‘}
>>> a - b # letters in a but not in b
{‘r‘, ‘d‘, ‘b‘}
>>> a | b # letters in either a or b
{‘a‘, ‘c‘, ‘r‘, ‘d‘, ‘b‘, ‘m‘, ‘z‘, ‘l‘}
>>> a & b # letters in both a and b
{‘a‘, ‘c‘}
>>> a ^ b # letters in a or b but not both
{‘r‘, ‘d‘, ‘b‘, ‘m‘, ‘z‘, ‘l‘}
字典
另一个非常有用的 Python 内建数据类型是字典。
序列是以连续的整数为索引,与此不同的是,字典以关键字为索引,关键字可以是任意不可变类型,通常用字符串或数值。
理解字典的最佳方式是把它看做无序的键=>值对集合。在同一个字典之内,关键字必须是互不相同。
一对大括号创建一个空的字典:{}。
这是一个字典运用的简单例子:
>>> tel = {‘jack‘: 4098, ‘sape‘: 4139}
>>> tel[‘guido‘] = 4127
>>> tel
{‘sape‘: 4139, ‘guido‘: 4127, ‘jack‘: 4098}
>>> tel[‘jack‘]
4098
>>> del tel[‘sape‘]
>>> tel[‘irv‘] = 4127
>>> tel
{‘guido‘: 4127, ‘irv‘: 4127, ‘jack‘: 4098}
>>> list(tel.keys())
[‘irv‘, ‘guido‘, ‘jack‘]
>>> sorted(tel.keys())
[‘guido‘, ‘irv‘, ‘jack‘]
>>> ‘guido‘ in tel
True
>>> ‘jack‘ not in tel
False
构造函数 dict() 直接从键值对元组列表中构建字典。如果有固定的模式,列表推导式指定特定的键值对:
>>> dict([(‘sape‘, 4139), (‘guido‘, 4127), (‘jack‘, 4098)])
{‘sape‘: 4139, ‘jack‘: 4098, ‘guido‘: 4127}
此外,字典推导可以用来创建任意键和值的表达式词典:
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
如果关键字只是简单的字符串,使用关键字参数指定键值对有时候更方便:
>>> dict(sape=4139, guido=4127, jack=4098)
{‘sape‘: 4139, ‘jack‘: 4098, ‘guido‘: 4127}
遍历技巧
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
>>> knights = {‘gallahad‘: ‘the pure‘, ‘robin‘: ‘the brave‘}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
>>> for i, v in enumerate([‘tic‘, ‘tac‘, ‘toe‘]):
... print(i, v)
...
0 tic
1 tac
2 toe
同时遍历两个或更多的序列,可以使用 zip() 组合:
>>> questions = [‘name‘, ‘quest‘, ‘favorite color‘]
>>> answers = [‘lancelot‘, ‘the holy grail‘, ‘blue‘]
>>> for q, a in zip(questions, answers):
... print(‘What is your {0}? It is {1}.‘.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
要反向遍历一个序列,首先指定这个序列,然后调用 reversesd() 函数:
>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
9
7
5
3
1
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
>>> basket = [‘apple‘, ‘orange‘, ‘apple‘, ‘pear‘, ‘orange‘, ‘banana‘]
>>> for f in sorted(set(basket)):
... print(f)
...
apple
banana
orange
pear