标签:世界 image 过程 循环 编写 选择 实现 位置 优化算法
基础排序算法综述
参考资料
- 慕课网 liuyubobobo 老师《算法与数据结构》课程以及对应的 GitHub 代码仓库
- 慕课网 liuyubobobo 老师《看得见的算法》课程以及对应的 GitHub 代码仓库
内容概要
这一节,我们只介绍两种基本排序算法,以前,我去找工作,学习算法就只知道这两种排序算法,只是为了应付面试,真的是太年轻,太单纯了,熟不知,在算法的世界,有很多知识等待我们去学习,去挖掘。
选择排序
选择排序简介
- 选择排序是一个非常容易理解,并且简单的排序算法,通过选择排序算法的学习,打开我们学习算法大门;
- 选择排序的时间复杂度为 $O(n^2)$ ,虽然并不是时间复杂度最低的算法,但是它有一个特点,就是在一般情况下,或者说,平均来看,选择排序在排序的过程中交换元素的次数最少,这一点可以通过和其它排序算法的比较来理解,因为每一轮外层循环只交换一次元素的位置;
- 下面是一张展示了“选择排序”算法执行过程的可视化 gif 图,算法不是我写的,来自参考资料2。
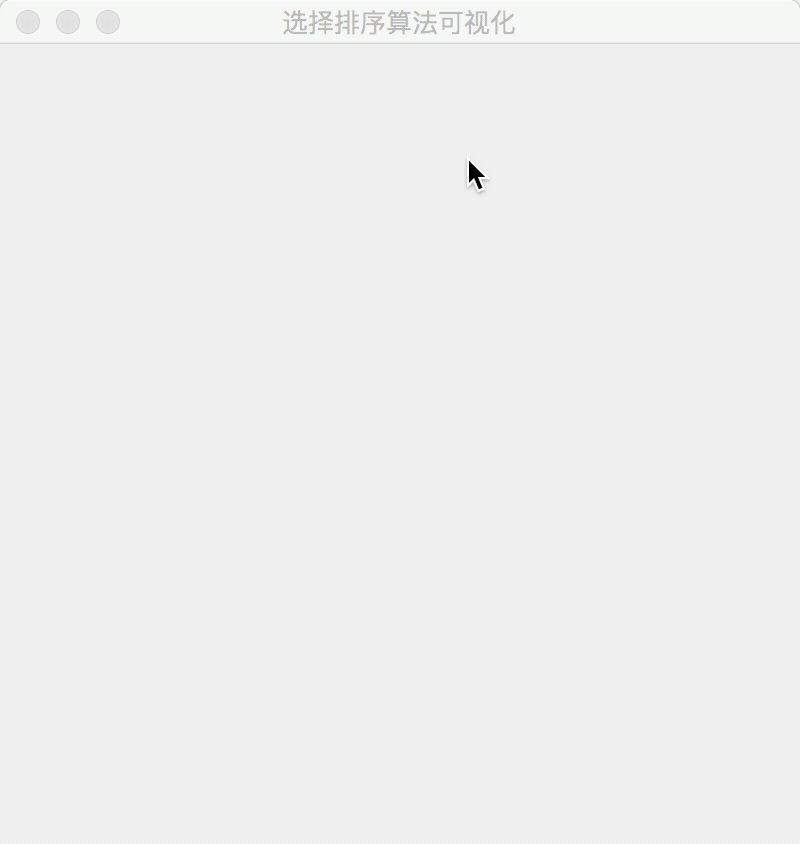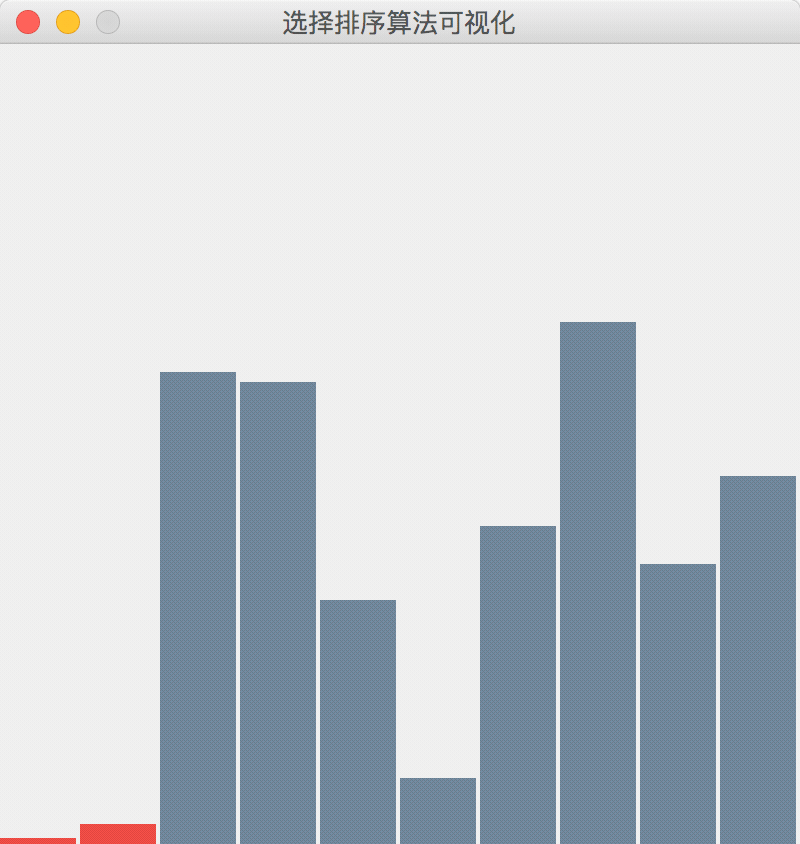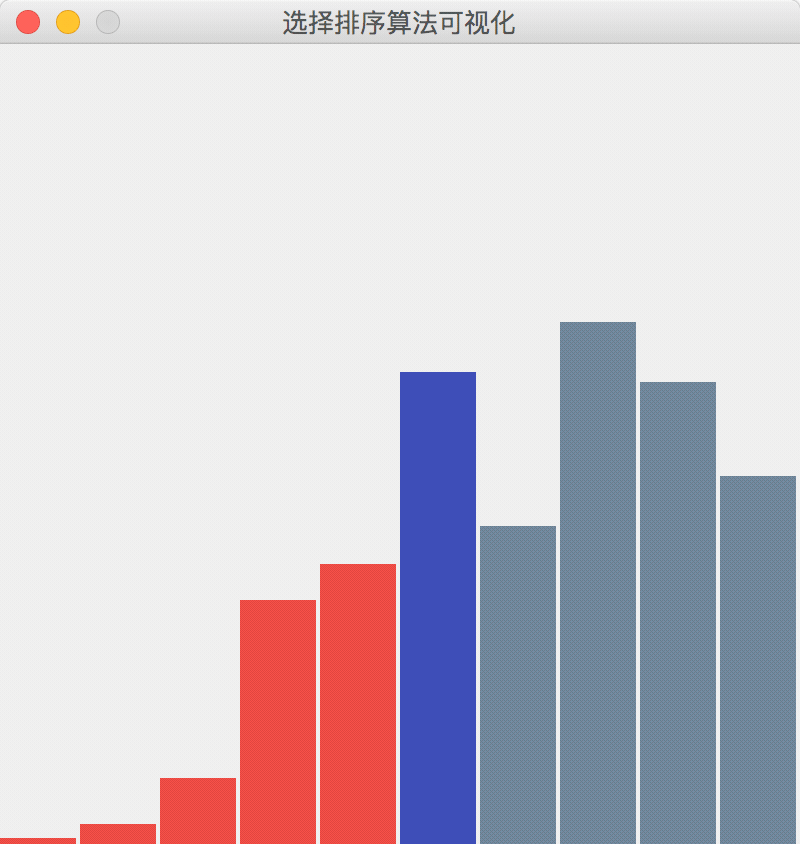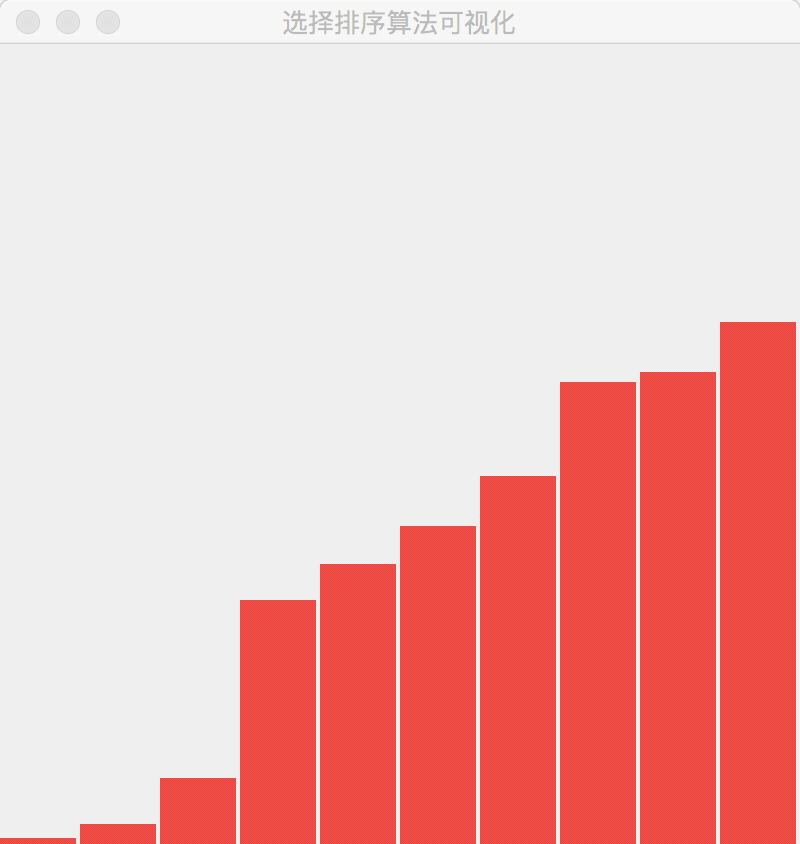
选择排序算法执行过程的简单描述
- 在每一轮外层循环中选择剩余元素之中的最小者,选择排序的外层循环在开始的时候总是先假设第 1 个元素是最小的元素,当然这肯定是不对的,于是选择最小元素的索引的修订过程就在内层循环中完成,内层循环完成以后,与外层循环中的第 1 个元素交换位置。
下面是一个展示了选择排序算法的具体例子: 在理解了选择排序算法的前提下,可以尝试自己写出选择排序,通过 Debug 的方式来验证自己写的选择排序方法是否正确。
在理解了选择排序算法的前提下,可以尝试自己写出选择排序,通过 Debug 的方式来验证自己写的选择排序方法是否正确。
选择排序的特点:
选择排序有两个很鲜明的特点:
- 运行时间和数组本身所具有的特点无关:即下面列出的三种数组,对于选择排序来说,都要进行相同次数的比较和相同交换元素位置的次数;
(1)已经排好序的数组;
(2)元素的值全部相等的数组或者元素的值近乎相等的数组;
(3)一个随机生成的一般意义上的数组;
- 执行排序过程中,元素交换的总次数是最少的。
代码实现(Java )
https://gist.github.com/liweiwei1419/40a3ef067d3feb3510904b0b234419
代码实现(Python)
https://gist.github.com/liweiwei1419/2ad3fa550924b66489bb501cf6fdff4a
插入排序
插入排序算法的基本执行流程概述
- 使用两层循环来完成排序的工作,这一点和选择排序是一致的;
- 在一般情况下,插入排序的时间复杂度也是 $O(n^2)$ ;
- 可以通过一个动画来简单了解插入排序的执行流程;
- 插入排序算法的关键步骤是:内层循环从后向前,挨个挨个进行元素的比较,如果遇到比自己大的元素,就交换位置,直到遇到小于或者等于当前元素,看起来就像是每一轮都将一个元素插入一个已经排好顺序的数组一样,我想这应该是为什么它叫插入排序的原因吧;
- 插入排序算法的执行流程的一部分比较像我们玩扑克牌,给放在手上的扑克牌排序那样。
- 下面是一张展示了“插入排序”算法执行过程的可视化 gif 图,算法不是我写的,来自参考资料2。
代码实现(Java)
https://gist.github.com/liweiwei1419/9231657e0b8506f8e6d3f2702dc9e8ec
下面这张图展示了对上面算法核心过程的分析:
 关键之处:
关键之处:
- 第 1 轮只有 1 个元素,所以元素就是排好序的,所以应该从第 2 个元素(索引为 1 的元素开始循环),直到数组的最后一个元素(这就是边界值设置为 < length)的原因;
- 内层循环以刚开始的那个元素作为标定点,依次与前面一个元素进行比较,如果遇到比自己大的元素,就与它交换,直到遇到等于自己或者比自己小的元素,内层循环终止。
- 下面是一种等价的写法:

说明:在 for 循环里面,出现 if 条件判断的分支是 break 的时候,可以把条件判断的部分放到 for 循环的循环体判断语句中。
下面,我们对“选择排序”和“插入排序”做一个比较。
选择排序与插入排序算法的比较
- 选择排序在每一轮外层循环都要选出一个最小的元素排在数组的前面,而插入排序的内层循环只要遇到了不大于自己的元素,内层循环就终止,这是插入排序算法的一个特点:内层循环可以提前终止,反观选择排序,每一次选择最小的元素都要老老实实地把剩下的所有的元素都看一遍。
- 那是不是插入排序一定比选择排序更好呢,也不一定,我们队算法的分析一定要建立在应用场景之上,插入排序虽然在内层循环中比较的次数会减少,但是它在比较元素的过程中,也在不停地交换元素的位置,如果我们交换元素的位置这件事情是很耗时的,那么就不应该使用“插入排序”。
插入排序算法的优化
- 优化的思路:从交换元素的代码中,我们可以看出,交换一次元素,我们做了两件事:(1)引入一个临时变量;(2)三次赋值操作。为此,我们很自然地想到,可以在一次内层循环中,只引入一个临时变量,然后通过逐个向后赋值的方式达到同样的效果。
- 这样与原来的插入排序相比,少了一系列交换元素的位置的操作,而是使用了一个临时变量先把这个元素存起来,然后依次与它前面元素比较,如果前面的元素大,就将前面的元素后移,然后再将这个临时存储起来的元素与再一个前面的元素比较,如果再一个前面的元素等于这个临时存储起来的元素,或者比这个临时存储起来的元素小,那么之前被存储起来的元素就应该放在这个位置,说起来很拗口,由于我的表达能力有限,可能还会让人误解,还是直接看代码比较清楚。
- 简而言之,我们使用了一个临时变量,将之前“多次交换变量”的过程转变为“多次赋值”的过程。
下面我们给出两种一模一样的针对插入排序的优化方案,供大家仔细比对:
代码1:

注意:最后不要忘记把一开始存起来的临时变量赋值到合适的地方。
代码2:

注意:最后不要忘记把一开始存起来的临时变量赋值到合适的地方。
上面的两张图的代码其实是一样的,如果不是很好理解的话,可以复习一下,for 循环的执行流程。

编写插入排序算法优化版的注意事项
由于我是刚刚接触算法的小萌新,在编写算法的过程中,会遇到不少问题。在编写“多次赋值”的插入排序优化算法的过程中,我就遇到了下面这个问题。
因为有许多赋值的操作,如果算法编写不正确,很可能出现的一种结果是:最后得到的数组是排序正确的,但是由于边界值,临界点的选择不对,导致数组的元素被更改。
然而,我就犯过这样的错误,由于编写不正确,运行出来的数组的确是排好序的,但是与原始数组根本不是一个数组。因此,在编写完算法以后,一定要自己看一下,或者我们还可以编写一个测试用例,写两个方法,一个是自己实现的排序算法,另一个是用语言提供的内置排序算法都排一下序,然后挨个比较元素是否相等。
因此,我们在检验自己的算法是否正确的同时,不应该只是检测经过我们编写的算法以后得到的数组是否有序,还应该检查我们得到的数组的元素是否与原数组中的元素一致。
总而言之:编写“多次赋值”的插入排序优化算法有更改数组元素值的“风险”,编写完成以后,一定要检验一下,自己编写的算法,是不是把原始待排序数组的元素值给更改了。
总结
小小的排序算法,都还有很多知识可以挖掘,囿于篇幅和个人目前的能力和时间,先只介绍这么多。还有一些简单的排序算法例如冒泡排序和 shell 排序等待以后有专门的篇幅来总结它们。
基础排序算法综述
标签:世界 image 过程 循环 编写 选择 实现 位置 优化算法
原文地址:https://www.cnblogs.com/liweiwei1419/p/8932942.html