标签:兴趣 python版本 div AC 爬取 nbsp span rom rbd
1.选一个自己感兴趣的主题或网站。(所有同学不能雷同)
源地址:http://www.18ladys.com/
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。

图3-1 爬虫小程序的词云
4.对文本分析结果进行解释说明。
因为爬取的是各个中药的类别及名字,没有爬取更细节的数据,所以显示出来的多是一些中药名词
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
(1).写了两个文件,具体如下:
1).数据爬取并生成txt文件的py文件
2).利用python相关的包生成词云相关操作的py文件
(2).遇到的问题以及解决方案:
1).wordcloud包的安装配置出现很大的问题,本机系统装载了两个python版本导致装载出现很多额外的问题。
解决:在同学的帮助下安装了whl文件并删除了本机中的另一个python版本。
2).信息爬取过慢
解决:暂未解决。爬取的页面预计超过100p,所以有关方面可能需要依赖别的技术。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
(1).文档部分
1).用于数据爬取并生成txt文件的py文件:
import requests from bs4 import BeautifulSoup #获取—————————————————————————————————————————— def catchSoup(url): #url=‘http://www.18ladys.com/post/buchong/‘ res=requests.get(url) res.encoding=‘utf-8‘ soup=BeautifulSoup(res.text,‘html.parser‘) return soup #类型及其网页查找(首页查找)—————————————————————— def kindSearch(soup): herbKind=[] for new in soup.select(‘li‘): if(new.text!=‘首页‘): perKind=[] perKind.append(new.text) perKind.append(new.select(‘a‘)[0].attrs[‘href‘]) herbKind.append(perKind) return herbKind #药名查找(传入页面)—————————————————————————————————————————————————————— def nameSearch(soup): herbName=[] for new in soup.select(‘h3‘): pername=new.text.split(‘_‘)[0].rstrip(‘图片‘).lstrip(‘\xa0‘) pername=pername.rstrip(‘的功效与作用‘) herbName.append(pername) return herbName #分页及详细地址—————————————————————————————————————————————————————————— def perPage(soup): kindPage=[] add=[] for new in soup.select(‘.post.pagebar‘): for detail in new.select(‘a‘): d=[] d.append(detail.text) d.append(detail.attrs[‘href‘]) kindPage.append(d) kindPage.remove(kindPage[0]) kindPage.remove(kindPage[-1]) return kindPage #爬取某一类的所有药名:kind是一个数字,照着kindSearch的结果输入。———————————— def herbDetail(kind): soup=catchSoup(‘http://www.18ladys.com/post/buchong/‘)#从首页开始 kindName=kindSearch(soup)[kind][0] #这一类草药的类名 adds=kindSearch(soup)[kind][1] #这一类草药的第一页地址 totalRecord = [] #这一类草药的所有名字 print("正在爬取 "+str(kind)+‘.‘+kindName) totalRecord.append(nameSearch(catchSoup(adds)))#第一页的草药 for add in perPage(catchSoup(adds)): #第二页以及之后的草药 pageAdd=add[1] totalRecord.append(nameSearch(catchSoup(pageAdd))) #print(nameSearch(catchSoup(pageAdd))) print(totalRecord) return totalRecord #=========================================================== # 操作 #=========================================================== if __name__=="__main__": #获取类别名字及其网页地址— totalKind=kindSearch(catchSoup(‘http://www.18ladys.com/post/buchong/‘)) #首页 #获取某一类中药的各种药名 totalRecord=[] kind=0 detailContent = ‘‘ while(kind<20): totalRecord=herbDetail(kind) if(kind==0): detailContent+=‘目录:\n‘ for i in totalKind: detailContent+=str(totalKind.index(i)+1)+‘.‘+i[0]+‘ ‘ kind+=1 continue else: detailContent+=‘\n‘+str(totalKind[kind][0])+‘:\n‘ for i in totalRecord: detailContent+=str(totalRecord.index(i)+1)+‘.‘+i[0]+‘ ‘ kind+=1 f = open(‘herbDetail.txt‘, ‘a+‘,encoding=‘utf-8‘) f.write(detailContent) f.close()
2).程序运行截图:
3).导出文档:
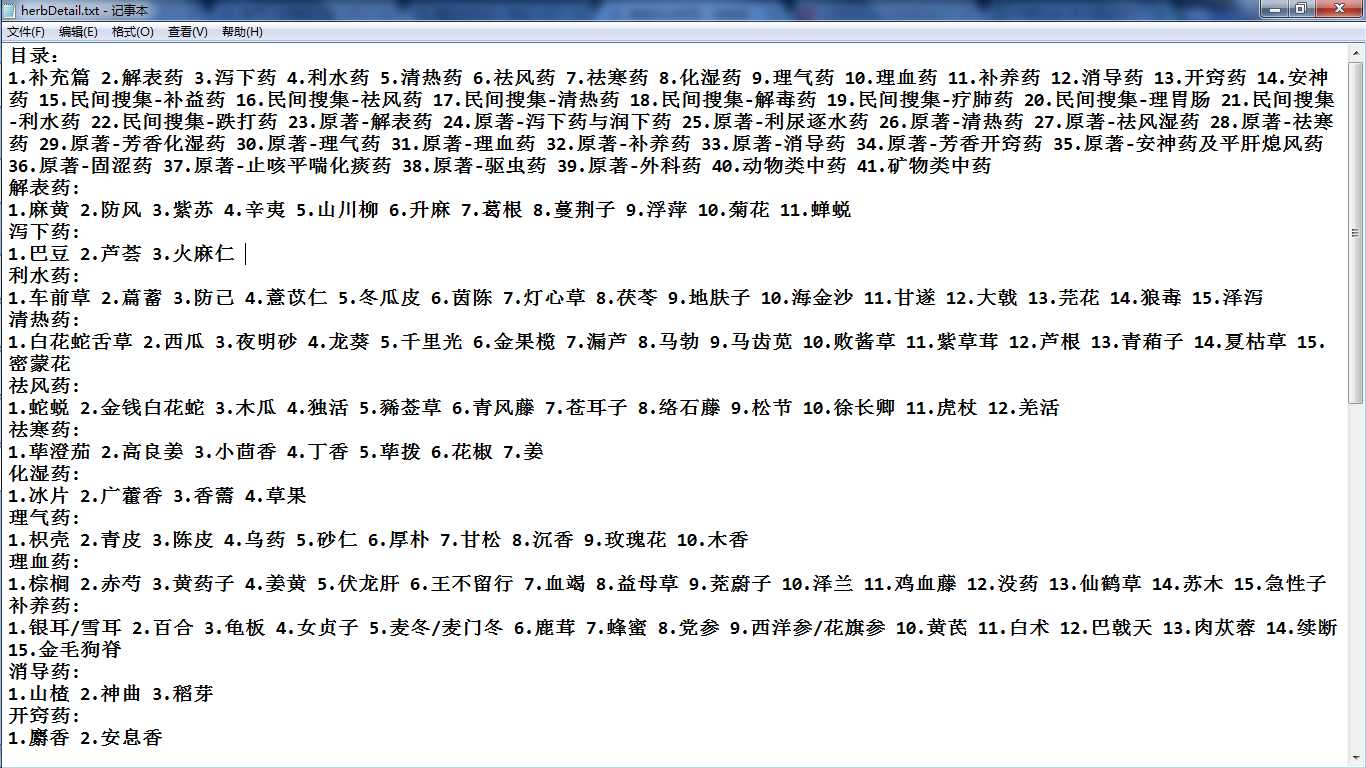
(2).词云生成部分
1).生成词云相关操作的py文件:
from wordcloud import WordCloud import jieba from os import path import matplotlib.pyplot as plt comment_text = open(‘D:\\herbDetail.txt‘,‘r‘,encoding=‘utf-8‘).read() cut_text = " ".join(jieba.cut(comment_text)) d = path.dirname(__file__) cloud = WordCloud( font_path="C:\\Windows\\Fonts\\simhei.ttf", background_color=‘white‘, max_words=2000, max_font_size=40 ) word_cloud = cloud.generate(cut_text) word_cloud.to_file("cloud4herb.jpg") #显示词云图片=================================== plt.imshow(word_cloud) plt.axis(‘off‘) plt.show()
2).生成的词云图片:
见上文 3.
标签:兴趣 python版本 div AC 爬取 nbsp span rom rbd
原文地址:https://www.cnblogs.com/CatalpaOvata132/p/8932846.html