标签:应该 计算机 通过 多线程 bsp lock 不同的 empty 意思
(二)和(三)不感兴趣的可以跳过,这里参考了《深入理解计算机系统》第一章和《Python核心编程》第四章
(一) 多线程编程
一个程序包含多个子任务,并且子任务之间相互独立,让这些子任务同时运行就是多线程编程。
(二) 进程
进程是操作系统对一个正在运行的程序的一种抽象(或者说进程指的就是运行中的程序)。无论是在单核还是多核系统中,一个CPU看上去都是在并发执行多个进程,实际上这是通过处理器在进程间的切换来实现的,这种切换称为上下文切换。(下面只讨论一个CPU单处理器的情况)
要运行一个新进程时:操作系统总是 1、保存当前进程的上下文。2、恢复新进程的上下文3、将控制权传递给新进程,然后新进程开始执行。
这里说明下上下文的概念:
操作系统保持跟踪进程运行所需的所有状态信息。这种状态,也就是上下文,包括许多信息,比如PC和寄存器文件的当前值,以及主存的内容。
举个例子(解释上下文的概念):你正在和张三谈话,这时一个电话打过来,可以说你暂停了和张三谈话的进程,然后切入新的进程(打电话),等电话打完后,你和张三从刚才停止的地方继续交流。
这时想想能在刚刚的基础上继续交流的前提是什么,我想应该是你还记得刚刚谈话的内容,刚刚说到了什么地方,然后才能在这个基础上继续交谈下去。(计算机也是这样,一个进程暂停的时候,会记住交谈的内容、谈到了什么地方(计算机记住的这些东西就称为上下文(就是当时进程运行时需要的所有状态信息))。计算机恢复一个进程的时候,就是先恢复进程的上下文(就像你要继续交流就要先想起刚刚的谈话一样),所以进程间的切换称为上下文切换)
(三) 线程
在进程执行的过程中,可能有多个分支或多个步骤,例如执行程序A,可能有三个步骤A1、A2、A3,执行A1、A2、A3的过程就是线程。
例如:用户向服务器发出请求-服务器接收请求-服务器处理请求-服务器返回资源。这时就可以有:
线程1:负责接收用户的请求,放到一个队列中。
线程2:处理请求,并提供输出
线程3:负责返回资源
所以,一个进程实际上是由多个称为线程的执行单元组成的,每个线程都运行在进程的上下文中。
关于进程和线程,可以将进程理解为1个完整的任务,线程就是一个个子任务。
子任务1+子任务2+子任务3…组成了一个进程。
(四) Python中多线程
有2个标准库可以实现多线程,_thread和threading,threading更加先进,有更好的线程支持,推荐使用threading,下面也只对threading进行说明。
threading模块对象
|
对象 |
说明 |
|
Thread |
表示一个执行线程的对象 |
|
Lock |
锁原语对象 |
|
Semaphore |
为线程间共享的有限资源创建一个计数器,计数器值为0时,线程阻塞 |
|
BoundedSemaphore |
和Semaphore类似,不过它不允许计数器的值超过初始值 |
Thread类
|
方法 |
说明 |
__init__(self,target=None, args=(),kwargs={})
|
实例化一个线程对象,这里只说明这3个参数的意思,target指函数名,args和kwargs都指要传给函数的参数(args传元组,kwargs传字典),只要指定一个就行了 例如:有一个函数def loop1(name,t),实例化线程的时候,下面2种方式都是可以的 t = threading.Thread(target=loop1,kwargs={‘name‘:‘线程1‘,‘t‘:5})
t = threading.Thread(target=loop1,args=(‘线程1‘,5)) |
start |
开始执行线程 |
run |
定义线程功能的方法(一般在继承threading.Thread的子类中重写该方法) |
join(timeout=None) |
等待直到线程终止 |
接下来:
第五节: 举个不使用多线程的例子。
第六、七节:说明使用threading.Tread创建多线程的2种方式
第八、九、十:分别说明为什么要做线程同步、线程同步方式(锁示例)、线程同步方式(信号量示例)
第十一:说明队列queue模块(该模块提供线程间通信机制,从而让线程间可以分享数据)
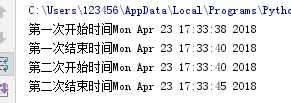
(五) 不使用多线程时的情况(接下来注意不使用多线程和使用多线程执行时间的区别)
1 import time2 def loop1(name,t): 3 print(name+‘开始时间‘ + time.ctime()) 4 time.sleep(t) 5 print(name+‘结束时间‘ + time.ctime()) 6 loop1(‘第一次‘,2) 7 loop1(‘第二次‘,5)
接下来对使用Tread创建多线程的2种方式进行说明:
1、创建Tread实例,传函数。(六)
2、继承threading.Thread创建子类,并创建子类的实例。(七)
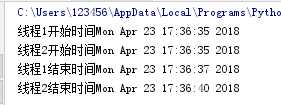
(六) 创建Tread实例(传函数),然后调用star启动线程
target指函数名,args指要传的参数
1 import threading 2 import time 3 def loop1(name,t): 4 print(name+‘开始时间‘ + time.ctime()) 5 time.sleep(t) 6 print(name+‘结束时间‘ + time.ctime()) 7 8 #创建新线程 9 t = threading.Thread(target=loop1,args=(‘线程1‘,2)) 10 t1 = threading.Thread(target=loop1,args=(‘线程2‘,5)) 11 #启动线程 12 t.start() 13 t1.start()
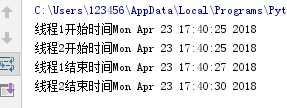
(七) 继承threading.Thread创建子类,实例化后调用star启动线程
1 import threading 2 import time 3 class test1(threading.Thread): 4 def __init__(self,name,t): 5 threading.Thread.__init__(self) 6 self.name = name 7 self.t = t 8 def run(self): 9 loop1(self.name,self.t) 10 def loop1(name,t): 11 print(name+‘开始时间‘ + time.ctime()) 12 time.sleep(t) 13 print(name+‘结束时间‘ + time.ctime()) 14 #创建新线程 15 t = test1(‘线程1‘,2) 16 t1 = test1(‘线程2‘,5) 17 #启动线程 18 t.start() 19 t1.start()
(八)线程同步(为什么需要同步)
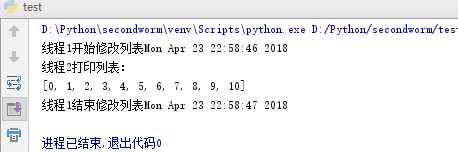
1 import threading 2 import time 3 class test1(threading.Thread): 4 def __init__(self,name,t): 5 threading.Thread.__init__(self) 6 self.name = name 7 self.t = t 8 def run(self): 9 print(‘线程1开始修改列表‘+time.ctime()) 10 #[i for i in range(100)]创建一个[0,1,2...99]的列表 11 loop1([i for i in range(100)]) 12 print(‘线程1结束修改列表‘+time.ctime()) 13 class test2(threading.Thread): 14 def __init__(self,name,t): 15 threading.Thread.__init__(self) 16 self.name = name 17 self.t = t 18 def run(self): 19 print(‘线程2打印列表:‘) 20 printList() 21 the_list = [] 22 def loop1(num): 23 for i in num: 24 the_list.append(i) 25 if i ==10: 26 time.sleep(1) 27 def printList(): 28 print(the_list) 29 #创建新线程 30 t = test1(‘线程1‘,2) 31 t1 = test2(‘线程2‘,5) 32 #启动线程 33 t.start() 34 t1.start()
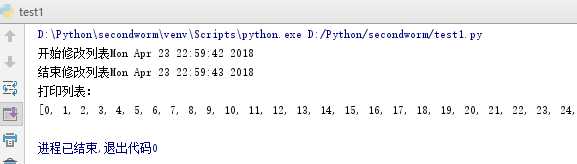
看上面这段代码,线程1调用loop1()函数修改列表the_list,线程2调用pringtList()打印the_list.如果不同步,那么可能出现loop1()函数修改到一半的时候,线程2就把the_list打印出来了,如下图所示。
(九)线程同步(锁示例)
接下来说明2种同步原语,锁和信号量。
通过acquire()获取锁,release()释放锁。
1 import threading 2 import time 3 class test1(threading.Thread): 4 def __init__(self,name,t): 5 threading.Thread.__init__(self) 6 self.name = name 7 self.t = t 8 def run(self): 9 #获取锁,用于线程同步 10 threadLock.acquire() 11 print(‘开始修改列表‘+time.ctime()) 12 #[i for i in range(100)]创建一个[0,1,2...99]的列表 13 loop1([i for i in range(100)]) 14 print(‘结束修改列表‘+time.ctime()) 15 #释放锁,开始下一个线程 16 threadLock.release() 17 class test2(threading.Thread): 18 def __init__(self,name,t): 19 threading.Thread.__init__(self) 20 self.name = name 21 self.t = t 22 def run(self): 23 # 获取锁,用于线程同步 24 threadLock.acquire() 25 print(‘打印列表:‘) 26 printList() 27 # 释放锁,开始下一个线程 28 threadLock.release() 29 30 threadLock = threading.Lock() 31 the_list = [] 32 33 def loop1(num): 34 for i in num: 35 the_list.append(i) 36 if i ==10: 37 time.sleep(1) 38 def printList(): 39 print(the_list) 40 #创建新线程 41 t = test1(‘线程1‘,2) 42 t1 = test2(‘线程2‘,5) 43 #启动线程 44 t.start() 45 t1.start()
用锁同步就不会存在上面的情况了,输出如下图所示:
也可以使用with,将上面test1的代码修改成下面的,执行with里面的代码时,会先调用acquire(),执行结束后,调用release()自动释放锁。
1 def run(self): 2 with threadLock: 3 print(‘开始修改列表‘ + time.ctime()) 4 # [i for i in range(100)]创建一个[0,1,2...99]的列表 5 loop1([i for i in range(100)]) 6 print(‘结束修改列表‘ + time.ctime())
(十)线程同步(信号量示例)
对操作系统PV操作有了解的,应该很容易理解。不知道也没关系,举个例子,有2台打印机,有4个线程要调用这2台打印机进行打印。
1、有2台打印机,这时可用资源 =2,代码中设置一个计数器(值为2)
2、线程1 、线程2分别调用不同的打印机进行打印(占用资源2,计数器值=2-2),此时线程3和4因为没有资源,处于阻塞状态。
3、线程1打印完后,释放资源(计数器值=0+1)
4、此时线程3或线程4,调用打印机进行打印(计数器值=1-1)
5、。。。等所有线程打印完后,计数器值就恢复初始值(2),表示2台打印机都处于空闲状态。
简单的说,这种方式就是
1、设置一个计数器,指定初始值
2、线程开始的时候调用acquire() (占用资源,计数器的值-1)
3、线程结束的时候调用release() (释放资源,计数器值+1)
(计数器的值为0时,线程是处于阻塞状态的)
可以在IDE上运行下面的代码,看下输出。
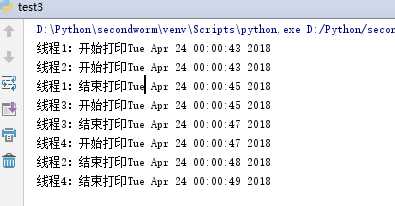
1 import threading 2 import time 3 #添加计数器(设置打印机数量为2) 4 #BoundedSemaphore还有一个作用:计数器的值永远不会超过初始值 5 printerNum = threading.BoundedSemaphore(2) 6 class test1(threading.Thread): 7 def __init__(self, name, t): 8 threading.Thread.__init__(self) 9 self.name = name 10 self.t = t 11 def run(self): 12 # 计数器获取锁,计数器值-1 13 printerNum.acquire() 14 print(self.name+‘:开始执行‘ + time.ctime()) 15 loop1(self.t) 16 print(self.name+‘:结束执行‘ + time.ctime()) 17 # 计数器释放锁,计数器值+1 18 printerNum.release() 19 def loop1(t): 20 time.sleep(t) 21 threadName = [‘线程1‘,‘线程2‘,‘线程3‘,‘线程4‘] 22 threadList = [] 23 #创建新线程 24 for tname in threadName: 25 thread = test1(tname,2) 26 if tname == ‘线程2‘: 27 thread = test1(tname, 5) 28 #将线程添加到列表 29 threadList.append(thread) 30 #启动线程 31 for t in threadList: 32 t.start() 33 #等待所有线程完成 34 for t in threadList: 35 t.join() 36 print(‘线程执行完成‘)
(十一)队列queue
三种类型:FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
|
方法 |
说明 |
|
qsize() |
返回队列大小 |
|
empty() |
如果队列为空,返回True,反之False |
|
full() |
如果队列满了,返回True,反之False |
|
put(item, block=True,timeout=None) |
将item放进队列中。block和timeout的作用和下面的get一样,不过这边的判断条件是队列有空间 |
|
put_nowait(item) |
和put(item,False)相同 |
|
get(block=True,timeout=None) |
block和timeout使用默认值:队列中没有元素时,阻塞到有可用元素为止 block:设置为Fasle,表示没元素时不等待,报Empty异常。 timeout:设置一个超时时间,超时队列还没元素,报Empty异常 (block为Fasle时,timeout是不生效的) |
|
get_nowait() |
和get(False)相同 |
|
task_done() |
表示队列中某个元素已经执行完毕,该方法会被下面的join()调用 |
|
join() |
所有元素执行完毕并调用上面的task_done()信号之前,保持阻塞 |
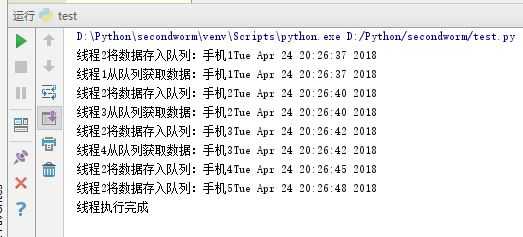
1 import threading 2 import time 3 import queue 4 from random import randint 5 #从队列取数据 6 class test1(threading.Thread): 7 def __init__(self, name, workQueue): 8 threading.Thread.__init__(self) 9 self.name = name 10 self.workQueue = workQueue 11 def run(self): 12 loop1(self.name,self.workQueue) 13 #往队列写数据 14 class test2(threading.Thread): 15 def __init__(self, name, nameList): 16 threading.Thread.__init__(self) 17 self.name = name 18 self.nameList = nameList 19 def run(self): 20 loop2(self.name,self.nameList) 21 def loop1(name,workQueue): 22 #从队列获取数据 23 data = workQueue.get() 24 print(name + "从队列获取数据:" + data + time.ctime()) 25 time.sleep(randint(2, 5)) 26 def loop2(name,nameList): 27 #将数据存入队列 28 for n in nameList: 29 workQueue.put(n) 30 print(name + "将数据存入队列:" + n+time.ctime()) 31 time.sleep(randint(2, 3)) 32 threadName = [‘线程1‘,‘线程2‘,‘线程3‘,‘线程4‘] 33 nameList = [‘手机1‘,‘手机2‘,‘手机3‘,‘手机4‘,‘手机5‘] 34 #创建一个先入先出的队列,最大值为10 35 workQueue = queue.Queue(10) 36 threadList = [] 37 #创建新线程 38 for tname in threadName: 39 thread = test1(tname,workQueue) 40 if tname == ‘线程2‘: 41 thread = test2(tname, nameList) 42 #将线程添加到列表 43 threadList.append(thread) 44 #启动线程 45 for t in threadList: 46 t.start() 47 #等待所有线程完成 48 for t in threadList: 49 t.join() 50 print(‘线程执行完成‘)
标签:应该 计算机 通过 多线程 bsp lock 不同的 empty 意思
原文地址:https://www.cnblogs.com/simple-free/p/8920654.html