标签:tco 64位 sig SQ execution read 复用 keepalive turn
平时的业务中,如果要使用多线程,那么我们会在业务开始前创建线程,业务结束后,销毁线程。但是对于业务来说,线程的创建和销毁是与业务本身无关的,只关心线程所执行的任务。因此希望把尽可能多的cpu用在执行任务上面,而不是用在与业务无关的线程创建和销毁上面。而线程池则解决了这个问题,线程池的作用就是将线程进行复用。
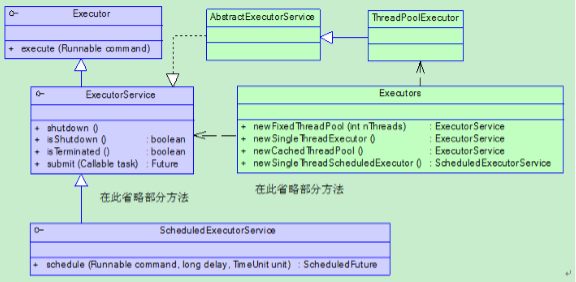
JDK中的相关类图如上图所示。
其中要提到的几个特别的类。
Callable类和Runable类相似,但是区别在于Callable有返回值。
ThreadPoolExecutor是线程池的一个重要实现。
而Executors是一个工厂类。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}从方法上来看,显然 FixedThreadPool,SingleThreadExecutor,CachedThreadPool都是ThreadPoolExecutor的不同实例,只是参数不同。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}下面来简述下 ThreadPoolExecutor构造函数中参数的含义。
这样在来看上面所说的FixedThreadPool,它的线程的核心数目和最大容纳数目都是一样的,以至于在工作期间,并不会创建和销毁线程。当任务数量很大,线程池中的线程无法满足时,任务将被保存到LinkedBlockingQueue中,而LinkedBlockingQueue的大小是Integer.MAX_VALUE。这就意味着,任务不断地添加,会使内存消耗越来越大。
而CachedThreadPool则不同,它的核心线程数量是0,最大容纳数目是Integer.MAX_VALUE,它的阻塞队列是SynchronousQueue,这是一个特别的队列,它的大小是0。由于核心线程数量是0,所以必然要将任务添加到SynchronousQueue中,这个队列只有一个线程在从中添加数据,同时另一个线程在从中获取数据时,才能成功。独自往这个队列中添加数据会返回失败。当返回失败时,则线程池开始扩展线程,这就是为什么CachedThreadPool的线程数目是不固定的。当60s该线程仍未被使用时,线程则被销毁。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolDemo {
public static class MyTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + "Thread ID:"
+ Thread.currentThread().getId());
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask myTask = new MyTask();
ExecutorService es = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
es.submit(myTask);
}
}
}由于使用的newFixedThreadPool(5),但是启动了10个线程,所以每次执行5个,并且 可以很明显的看到线程的复用,ThreadId是重复的,也就是前5个任务和后5个任务都是同一批线程去执行的。
这里用的是
es.submit(myTask);还有一种提交方式:
es.execute(myTask);区别在于submit会返回一个Future对象,这个将在以后介绍。
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ThreadPoolDemo {
public static void main(String[] args) {
ScheduledExecutorService ses = Executors.newScheduledThreadPool(10);
//如果前面的任务还未完成,则调度不会启动。
ses.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println(System.currentTimeMillis()/1000);
} catch (Exception e) {
// TODO: handle exception
}
}
}, 0, 2, TimeUnit.SECONDS);//启动0秒后执行,然后周期2秒执行一次
}
}输出:
1454832514
1454832517
1454832520
1454832523
1454832526
...由于任务执行需要1秒,任务调度必须等待前一个任务完成。也就是这里的每隔2秒的意思是,前一个任务完成后2秒再开启新的一个任务。
线程池中有一些回调的api来给我们提供扩展的操作。
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>()){
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行");
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("执行完成");
}
@Override
protected void terminated() {
System.out.println("线程池退出");
}
};我们可以通过实现ThreadPoolExecutor的子类去覆盖ThreadPoolExecutor的beforeExecute,afterExecute,terminated方法来实现在线程执行前后,线程池退出时的日志管理或其他操作。
有时候,任务非常繁重,导致系统负载太大。在上面说过,当任务量越来越大时,任务都将放到FixedThreadPool的阻塞队列中,导致内存消耗太大,最终导致内存溢出。这样的情况是应该要避免的。因此当我们发现线程数量要超过最大线程数量时,我们应该放弃一些任务。丢弃时,我们应该把任务记下来,而不是直接丢掉。
ThreadPoolExecutor中还有另一个构造函数。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}threadFactory我们在后面再介绍。
而handler就是拒绝策略的实现,它会告诉我们,如果任务不能执行了,该怎么做。

共有以上4种策略。
AbortPolicy:如果不能接受任务了,则抛出异常。
CallerRunsPolicy:如果不能接受任务了,则让调用的线程去完成。
DiscardOldestPolicy:如果不能接受任务了,则丢弃最老的一个任务,由一个队列来维护。
DiscardPolicy:如果不能接受任务了,则丢弃任务。
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r,
ThreadPoolExecutor executor) {
System.out.println(r.toString() + "is discard");
}
});当然我们也可以自己实现RejectedExecutionHandler接口来自己定义拒绝策略。
刚刚已经看到了,在ThreadPoolExecutor的构造函数中可以指定threadFactory。
线程池中的线程都是由线程工厂创建出来,我们可以自定义线程工厂。
默认的线程工厂:
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}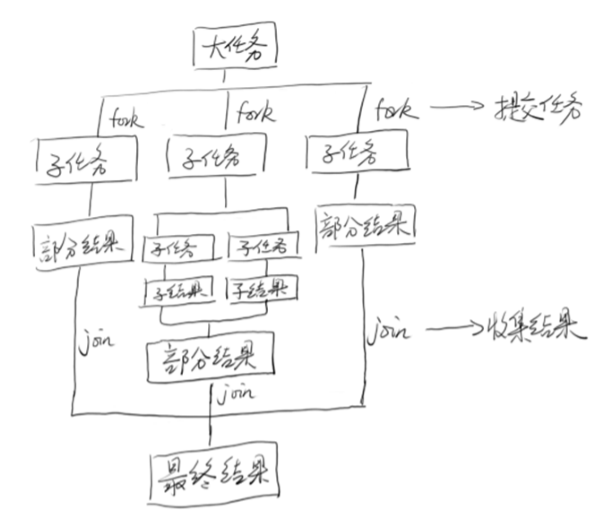
就是分而治之的思想。
fork/join类似MapReduce算法,两者区别是:Fork/Join 只有在必要时如任务非常大的情况下才分割成一个个小任务,而 MapReduce总是在开始执行第一步进行分割。看来,Fork/Join更适合一个JVM内线程级别,而MapReduce适合分布式系统。
RecursiveAction:无返回值
RecursiveTask:有返回值
import java.util.ArrayList;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask<Long>{
private static final int THRESHOLD = 10000;
private long start;
private long end;
public CountTask(long start, long end) {
super();
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
boolean canCompute = (end - start) < THRESHOLD;
if(canCompute)
{
for (long i = start; i <= end; i++) {
sum = sum + i;
}
}else
{
//分成100个小任务
long step = (start + end)/100;
ArrayList<CountTask> subTasks = new ArrayList<CountTask>();
long pos = start;
for (int i = 0; i < 100; i++) {
long lastOne = pos + step;
if(lastOne > end )
{
lastOne = end;
}
CountTask subTask = new CountTask(pos, lastOne);
pos += step + 1;
subTasks.add(subTask);
subTask.fork();//把子任务推向线程池
}
for (CountTask t : subTasks) {
sum += t.join();//等待所有子任务结束
}
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(0, 200000L);
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
long res = result.get();
System.out.println("sum = " + res);
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
}上述例子描述了一个累加和的任务。将累加任务分成100个任务,每个任务只执行一段数字的累加和,最后join后,把每个任务计算出的和再累加起来。
每一个线程都会有一个工作队列
static final class WorkQueue在工作队列中,会有一系列对线程进行管理的字段
volatile int eventCount; // encoded inactivation count; < 0 if inactive
int nextWait; // encoded record of next event waiter
int nsteals; // number of steals
int hint; // steal index hint
short poolIndex; // index of this queue in pool
final short mode; // 0: lifo, > 0: fifo, < 0: shared
volatile int qlock; // 1: locked, -1: terminate; else 0
volatile int base; // index of next slot for poll
int top; // index of next slot for push
ForkJoinTask<?>[] array; // the elements (initially unallocated)
final ForkJoinPool pool; // the containing pool (may be null)
final ForkJoinWorkerThread owner; // owning thread or null if shared
volatile Thread parker; // == owner during call to park; else null
volatile ForkJoinTask<?> currentJoin; // task being joined in awaitJoin
ForkJoinTask<?> currentSteal; // current non-local task being executed这里要注意的是,JDK7和JDK8在ForkJoin的实现上有了很大的差别。我们这里介绍的是JDK8中的。 在线程池中,有时不是所有的线程都在执行的,部分线程会被挂起,那些挂起的线程会被存放到一个栈中。内部通过一个链表表示。
nextWait会指向下一个等待的线程。
poolIndex线程在线程池中的下标索引。
eventCount 在初始化时,eventCount与poolIndex有关。总共32位,第一位表示是否被激活,15位表示被挂起的次数eventCount,剩下的表示poolIndex。用一个字段来表示多个意思。
工作队列WorkQueue用ForkJoinTask<?>[] array来表示。而top,base来表示队列的两端,数据在这两者之间。
在ForkJoinPool中维护着ctl(64位long型)
volatile long ctl;
* Field ctl is a long packed with:
* AC: Number of active running workers minus target parallelism (16 bits)
* TC: Number of total workers minus target parallelism (16 bits)
* ST: true if pool is terminating (1 bit)
* EC: the wait count of top waiting thread (15 bits)
* ID: poolIndex of top of Treiber stack of waiters (16 bits)AC表示活跃的线程数减去并行度(大概就是CPU个数)
TC表示总的线程数减去并行度
ST表示线程池本身是否是激活的
EC表示顶端等待线程的挂起数
ID表示顶端等待线程的poolIndex
很明显ST+EC+ID就是我们刚刚所说的 eventCount 。
那么为什么明明5个变量,非要合成一个变量呢。其实用5个变量占用容量也差不多。
用一个变量代码的可读性上会差很多。
那么为什么用一个变量呢?其实这点才是最巧妙的地方,因为这5个变量是一个整体,在多线程中,如果用5个变量,那么当修改其中一个变量时,如何保证5个变量的整体性。那么用一个变量则就解决了这个问题。如果用锁解决,则会降低性能。
用一个变量则保证了数据的一致性和原子性。
在ForkJoin中队ctl的更改都是使用CAS操作,在前面系列的文章中已经介绍过,CAS是无锁的操作,性能很好。
由于CAS操作也只能针对一个变量,所以这种设计是最优的。
接下来要介绍下整个线程池的工作流程。
每个线程都会调用runWorker
final void runWorker(WorkQueue w) {
w.growArray(); // allocate queue
for (int r = w.hint; scan(w, r) == 0; ) {
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // xorshift
}
}scan()函数是扫描是否有任务要做。
r是一个相对随机的数字。
private final int scan(WorkQueue w, int r) {
WorkQueue[] ws; int m;
long c = ctl; // for consistency check
if ((ws = workQueues) != null && (m = ws.length - 1) >= 0 && w != null) {
for (int j = m + m + 1, ec = w.eventCount;;) {
WorkQueue q; int b, e; ForkJoinTask<?>[] a; ForkJoinTask<?> t;
if ((q = ws[(r - j) & m]) != null &&
(b = q.base) - q.top < 0 && (a = q.array) != null) {
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
if ((t = ((ForkJoinTask<?>)
U.getObjectVolatile(a, i))) != null) {
if (ec < 0)
helpRelease(c, ws, w, q, b);
else if (q.base == b &&
U.compareAndSwapObject(a, i, t, null)) {
U.putOrderedInt(q, QBASE, b + 1);
if ((b + 1) - q.top < 0)
signalWork(ws, q);
w.runTask(t);
}
}
break;
}
else if (--j < 0) {
if ((ec | (e = (int)c)) < 0) // inactive or terminating
return awaitWork(w, c, ec);
else if (ctl == c) { // try to inactivate and enqueue
long nc = (long)ec | ((c - AC_UNIT) & (AC_MASK|TC_MASK));
w.nextWait = e;
w.eventCount = ec | INT_SIGN;
if (!U.compareAndSwapLong(this, CTL, c, nc))
w.eventCount = ec; // back out
}
break;
}
}
}
return 0;
}我们接下来看看scan方法,scan的一个参数是WorkQueue,上面已经说过,每个线程都会拥有一个WorkQueue,那么多个线程的WorkQueue就会保存在workQueues里面,r是一个随机数,通过r来找到某一个 WorkQueue,在WorkQueue里面有所要做的任务。
然后通过WorkQueue的base,取得base的偏移量。
b = q.base
..
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
..然后通过偏移量得到最后一个的任务,运行这个任务
t = ((ForkJoinTask<?>)U.getObjectVolatile(a, i))
..
w.runTask(t);
..通过这个大概的分析理解了过程,我们发现,当前线程调用scan方法后,不会执行当前的WorkQueue中的任务,而是通过一个随机数r,来得到其他 WorkQueue的任务。这就是ForkJoinPool的主要的一个机理。
当前线程不会只着眼于自己的任务,而是优先完成其他任务。这样做来,防止了饥饿现象的发生。这样就预防了某些线程因为卡死或者其他原因而无法及时完成任务,或者某个线程的任务量很大,其他线程却没事可做。
然后来看看runTask方法
final void runTask(ForkJoinTask<?> task) {
if ((currentSteal = task) != null) {
ForkJoinWorkerThread thread;
task.doExec();
ForkJoinTask<?>[] a = array;
int md = mode;
++nsteals;
currentSteal = null;
if (md != 0)
pollAndExecAll();
else if (a != null) {
int s, m = a.length - 1;
ForkJoinTask<?> t;
while ((s = top - 1) - base >= 0 &&
(t = (ForkJoinTask<?>)U.getAndSetObject
(a, ((m & s) << ASHIFT) + ABASE, null)) != null) {
top = s;
t.doExec();
}
}
if ((thread = owner) != null) // no need to do in finally clause
thread.afterTopLevelExec();
}
}有一个有趣的命名:currentSteal,偷得的任务,的确是刚刚解释的那样。
task.doExec();将会完成这个任务。
完成了别人的任务以后,将会完成自己的任务。
通过得到top来获得自己任务第一个任务
while ((s = top - 1) - base >= 0 && (t = (ForkJoinTask<?>)U.getAndSetObject(a, ((m & s) << ASHIFT) + ABASE, null)) != null)
{
top = s;
t.doExec();
}接下来,通过一个图来总结下刚刚线程池的流程
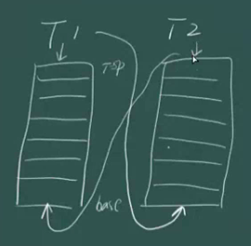
比如有T1,T2两个线程,T1会通过T2的base来获得T2的最后一个任务(当然实际上是通过一个随机数r来取得某个线程最后一个任务),T1也会通过自己的top来执行自己的第一个任务。反之,T2也会如此。
拿其他线程的任务都是从base开始拿的,自己拿自己的任务是从top开始拿的。这样可以减少冲突
如果没有找到其他任务
else if (--j < 0) {
if ((ec | (e = (int)c)) < 0) // inactive or terminating
return awaitWork(w, c, ec);
else if (ctl == c) { // try to inactivate and enqueue
long nc = (long)ec | ((c - AC_UNIT) & (AC_MASK|TC_MASK));
w.nextWait = e;
w.eventCount = ec | INT_SIGN;
if (!U.compareAndSwapLong(this, CTL, c, nc))
w.eventCount = ec; // back out
}
break;
}那么首先会通过一系列运行来改变ctl的值,获得了nc,然后用CAS将新的值赋值。然后就调用awaitWork()将线程进入等待状态(调用的 前面系列文章中提到的unsafe的park方法)。
这里要说明的是改变ctl值这里,首先是将ctl中的AC-1,AC是占ctl的前16位,所以不能直接-1,而是通过AC_UNIT(0x1000000000000)来达到使ctl的前16位-1的效果。
前面说过eventCount中有保存poolIndex,通过poolIndex以及WorkQueue中的nextWait,就能遍历所有的等待线程。
系列:
1. http://www.jdon.com/45364
标签:tco 64位 sig SQ execution read 复用 keepalive turn
原文地址:https://www.cnblogs.com/silentdoer/p/8943745.html