标签:管理 结构化 数据结构类型 bsp 有序 str 成本 raw 长度
Key * 查看所有键,(慎用,会把所有键都遍历一次并列出)
Dbsize 查看键总数,不会遍历所有键,只是从内置函数中读取一个数
Exists [key] 检查键是否存在
Del [key] 删除键
Expire [key] [seconds] 设置键过期时间
Type [key] 键的数据结构类型
Type命令实际返回的就是当前键的数据结构类型:string字符串,hash哈希,list列表,set集合,zset有序集合,但这些只是redis对外的数据结构,
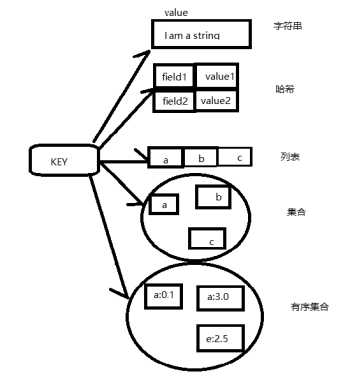
实际上每种数据结构都有自己底层的内部编码实现,而且试多种实现,这样redis会在合适的场景选择合适的内部编码
String raw,int,embstr
Hash hashtable,ziplist
Key List linkedlist,ziplist
Set hashtable,intset
Zset skiplist,ziplist
可以通过object encoding命令查询内部编码。这样的设计可以适应不同业务场景
Redis使用了单线程架构和I/O多路复用模型来实现高性能的内存数据库服务。
客户端与服务端的模型可以简化为:发送命令,执行命令,返回结果三步。
其中第二步因为redis是单线程来处理命令的,所以一条命令从客户端到达服务端不会立刻被执行,所有命令都会进入一个队列中,然后逐个被执行。这样可以避免并发的问题。
为什么单线程还能这么快?
第一,纯内存访问,redis将所有数据放在内存中,内存的响应时长大约在100纳秒,这是redis达到每秒万级别访问的重要基础。
第二,非阻塞I/O,Redis使用epoll作为io多路复用技术的实现,再加上redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为事件,不在网络io上浪费过多的时间
单线程避免了线程切换和竟态产生的消耗。
是最基础的数据类型,其它几种数据类型也是在字符串的基础上构建的;实际上字符串类型的值还可以是:字符串,数字,二进制,但值不能超过512MB
设置值
Set key value [ex seconds] [px milliseconds] [nx|xx]
Ex seconds:设置秒级过期时间
px milliseconds:设置毫秒级过期时间
Nx 键必须不存在,才可以设置成功,用于添加
Xx:与nx相反,键必须存在,才可以设置成功,用于更新
获取值
Get key
批量设置值:
Mset key value [key value key value]
批量获取
Mget key [key key key]
计数
Incr key
命令用于对值进行自增操作,返回结果又3种:
值不是整数,返回错误
值是整数,返回自增后结果
键不存在,按照值为0自增,返回结果为1
相关的还提供了decr自减,incrby自增指定数字,decrby自减指定数字,incrbyfloat自增浮点型
追加命令
Append key value
向value的尾部追加值
字符串长度:
strlen key
设置并返回原值
Getset key value
设置指定位置的字符
Setrange key offeset value
获取部分字符串
Getrange key start end
字符串类型有三种内部编码:
Int:8个字节的长整形
Embstr:小于等于39个字节的字符串
Raw:大于39个字节的字符串
Redis会根据当前值的类型和长度决定使用那种内部编码
缓存功能;
使用redis作为系统的缓存层关系型数据库作为数据层。Reids具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
UserInfo getUserInfo(long id){
1,检查redis种是否存在用户信息
2,从redis种获取session信息
3,如果没有则序列化到redis
}
计数
许多应用都会使用redis实现计数功能
共享session
一个分布式web服务将用户的session信息保存再各个服务器中,这会造成一个问题:出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同的服务器上,用户刷新一次会造成重复登陆的现象。为了解决这个问题,可以使用redis将用户的session进行集中管理,每次用户更新或者查询登陆信息都直接从reids种获取信息
限数
很多应用出于安全考虑,会再每次进行登陆时,让用户输入验证码,但为了短信接口不被频繁访问会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次。
哈希类型是指键值本身又是一个键值结构。
Key - value={
{field,value} {field,value} {field,value}...}
设置值 hset key field value
获取值 hget key field
删除field: hdel field [field...]
计算个数:hlen key
批量操作:
Hmget key field
Hmset key value[field value,field value]
是否存在:hexists key field
获取所有的field:hkeys key
获取所有的value:hvals key
获取所有的field-value:hgetall key
计算value的字符串长度:hstrleng key value
Ziplist压缩列表:当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个),同时所有值都小于hash-max-ziplist-value配置(默认配置64字节)时,redis会使用ziplist作为内部实现
Hashtable哈希表:当不满足压缩列表时自动升级为哈希表,hashtable的读写时间复杂度O(1)
可以将关系型数据库表记录的数据(user表)通过userID缓存到redis中。
比如将整个用户的关联信息通过json缓存到field中
需要注意两点哈希类型是稀疏的,而关系型数据库是完全结构化的。
关系型数据库可以做复杂的关系查询,而reids去模拟关系型复杂查询开发难度高维护成本高
标签:管理 结构化 数据结构类型 bsp 有序 str 成本 raw 长度
原文地址:https://www.cnblogs.com/cuijl/p/8946164.html