标签:std now() heap sort heapsort style 概念 OWIN 破坏 quic
排序(Sorting),特别是高效的排序一直是计算机工作学习和研究的重要课题之一,排序有内部排序和外部排序之分,若整个排序过程不需要访问外存便能完成,则称此类排序为内部排序,反之则为外部排序。本篇将对常用排序算法进行总结。
在进行排序总结之前先介绍测试中常用到的生成随机数方法和计算执行时间的方法。
C++中没有自带的random函数,要实现随机数的生成就需要使用rand()和srand()。不过由于rand()的内部实现是线性同余法左的,所以生成的并不是真正的随机数,而是在一定范围内可看为随机的伪随机数。
单纯的rand()会返回一个0到RAND_MAX之间的随机数值,而RAND_MAX的值与int位数有关,最小为32767。不过rand()是一次性的,因为系统默认的随机种子数是1,只要随机种子树不变,其生成的随机数序列不会改变。
对于rand()的范围,我们是可以进行人为设定的,只需要在宏定义中定义一个random(int x)函数,就可以生成范围为0至x的随机数值。当然,也可以定义为random(a,b),使其生成范围为a至b的随机数值。具体定义方法在通式部分。
srand()可用来设置rand()产生随机数时的随机数种子。通过设置不同的种子,我们可以获取不同的随机数序列。可以利用srand((unsigned int)(time(NULL))的方法,利用系统时钟,产生不同的随机数种子。不过要调用time(),需要加入头文件< ctime >。
产生一定范围随机数的通用表示公式是:
为了得到us级的时间计数,Windows提供了如下高精度的性能函数:
BOOL QueryPerformanceFrequency(LARGE_INTEGER *pliFrequency);
BOOL QueryPerformanceCounter(LARGE_INTEGER *pliCount);
class CStopwatch { private: // 64位有符号整数可以用INT64 _int64 LARGE_INTEGER表示 LARGE_INTEGER m_nPerfFrequency; LARGE_INTEGER m_nPerFrefStart; public: CStopwatch(){QueryPerformanceFrequency(&m_nPerfFrequency); Start();} void Start(){QueryPerformanceCounter(&m_nPerFrefStart);} INT64 Now() const { LARGE_INTEGER nPerfNow; QueryPerformanceCounter(&nPerfNow); return ((nPerfNow.QuadPart - m_nPerFrefStart.QuadPart) * 1000) / m_nPerfFrequency.QuadPart; } INT64 NowInMicro() const { LARGE_INTEGER nPerfNow; QueryPerformanceCounter(&nPerfNow); return ((nPerfNow.QuadPart - m_nPerFrefStart.QuadPart) * 1000000) / m_nPerfFrequency.QuadPart; } };
插入排序(Insertion Sort)的主要思想是不断地将待排序的元素插入到有序序列中,是有序序列不断地扩大,直至所有元素都被插入到有序序列中。例如我们平常玩扑克牌时的抓牌操作就是一个插入操作的例子,每抓一张牌后我们便将其插入到合适的位置,直到抓完牌位置,这时我们手上的牌就成了一个有序序列。
// 插入排序 template <typename T> void InsertSort(T *array, int nLen) { int i,j,k; for (i = 1; i < nLen; i ++) { for (j = i - 1; j >=0; j--) { if (array[i] > array[j]) { break; } } T temp = array[i]; for (k = i-1; k >j; k --) { array[k + 1] = array[k]; } array[j+1] = temp; } }
总结:直接插入排序最好情况时间复杂度为O(n),最坏情况下(逆序表)时间复杂度为O(n2),因此它只适合于数据量较少的情况使用。
冒泡排序(Bubble Sort)是一种简单的交换排序方法,其基本思想是:两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为止。
// 冒泡排序 template<typename T> void BubbleSort(T* array, int nLen) { if (array == NULL || nLen <=0 ) { return; } for (int i = 1; i < nLen; i ++) { for (int j = 0; j < nLen - i; j ++) { if (array[j+1] < array[j]) { T temp = array[j+1]; array[j] = array[j+1]; array[j+1] = temp; } } } }
总结:冒泡排序在运行时间方面,待排序的记录越接近有序,算法的执行效率就越高,反之,执行效率则越低,它的平均时间复杂度为O(n2)。
选择排序的基本思想是:第一趟从所有的n个记录中选择最小的记录放在第一位,第二趟从n-1个记录中选择最小的记录放到第二位。以此类推,经过n-1趟排序之后,整个待排序序列就成为有序序列了。
// 选择排序 template<typename T> void SelectSort(T *array, int nLen) { if (array == NULL || nLen <= 0) { return; } int i,j,k; for (i = 0; i < nLen - 1; i ++) { k = i; for (j = i + 1; j < nLen; j ++) { if (array[j] < array[k]) { k = j; } } if (k != i) { T temp = array[k]; array[k] = array[i]; array[i] = temp; } } }
总结:选择排序外循环n-1趟,内循环执行n-i趟,因此,简单选择排序的平均时间复杂度为O(n2),和直接插入排序、冒泡排序一样均超过了1秒钟。
快速排序的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的。
快速排序的核心步骤为:
①获取中轴元素
②i从左至右扫描,如果小于基准元素,则i自增,否则记下a[i]
③j从右至左扫描,如果大于基准元素,则i自减,否则记下a[j]
④交换a[i]和a[j]
⑤重复这一步骤直至i和j交错,然后和基准元素比较,然后交换。
template<typename T> void QuickSort_1(T *array, int start, int end) { if (array == NULL || start >= end) { return; } int i = start; int j = end; T temp = array[start]; while (i < j) { while ((i < j) && array[j] >= temp) { j --; } array[i] = array[j]; while ((i < j) && array[i] <= temp) { i ++; } array[j] = array[i]; } array[i] = temp; QuickSort_1(array, start, i - 1); QuickSort_1(array, i + 1, end); } // 快速排序 template<typename T> void QuickSort(T *array, int nLen) { if (array == NULL || nLen <= 0) { return; } QuickSort_1(array, 0, nLen - 1); }
总结:快速排序的平均时间复杂度为O(nlog2n),在平均时间下,快速排序时目前被认为最好的内部排序方法。但是,如果待排序记录的初始状态有序,则快速排序则会退化为冒泡排序,其时间复杂度为O(n2)。换句话说,待排序记录越无序,基准两侧记录数量越接近,排序速度越快;相反,待排序记录越有序,则排序速度越慢。
对于快速排序的改进一般集中在以下几个方面:
①当划分到较小的子序列时,通常可以使用插入排序替代快速排序;
②使用三平均分区法代替第一个元素作为基准值所出现的某些分区严重不均的极端情况;
③使用并行化处理排序;
堆排序(Heap Sort)是由J.Williams在1964年提出的,它是在选择排序的基础上发展起来的,比选择排序的效率要高,因此也可以说堆排序是选择排序的升级版。堆排序除了是一种排序方法外,还涉及到方法之外的一些概念:堆和完全二叉树。这里主要说说什么是堆?
如果将堆看成一棵完全二叉树,则这棵完全二叉树中的每个非叶子节点的值均不大于(或不小于)其左、右孩子节点的值。由此可知,若一棵完全二叉树是堆,则根节点一定是这棵树的所有节点的最小元素或最大元素。非叶子节点的值大于其左、右孩子节点的值的堆称为大根堆,反之则称为下小根堆,如下图所示。
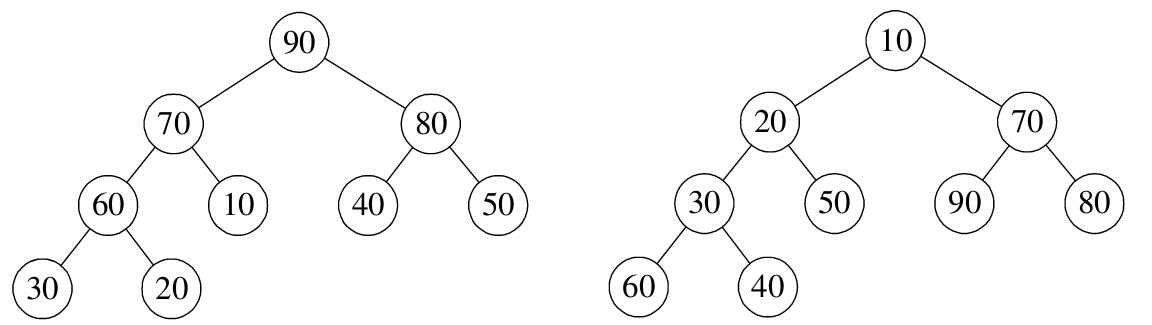
如果按照层序遍历的方式给结点从1开始编号,则结点之间满足如下关系:
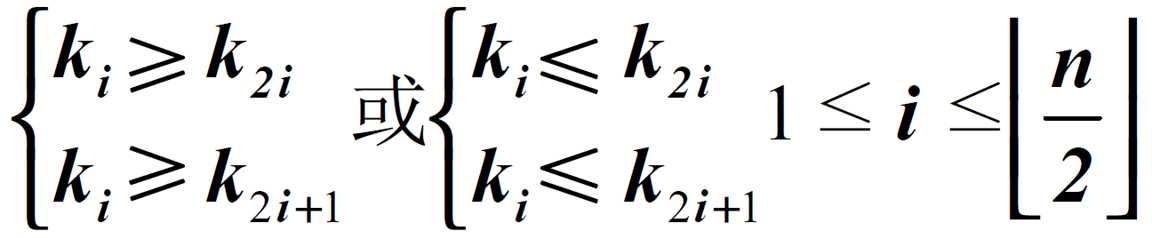
(1)基本思想
堆排序的基本思想是:首先将待排序的记录序列构造为一个堆,此时选择堆中所有记录的最小记录或最大记录,然后将它从堆中移出,并将剩余的记录再调整成堆,这样就又找到了次大(或次小)的记录。以此类推,直到堆中只有一个记录为止,每个记录出堆的顺序就是一个有序序列。
(2)处理步骤
堆排序的处理步骤如下:
①设堆中元素个数为n,先取i=n/2-1,将以i节点为根的子树调整成堆,然后令i=i-1。再将以i节点为根的子树调整成堆,如此反复,直到i=0为止,即完成初始堆的创建过程;
②首先输出堆顶元素,将堆中最后一个元素上移到原堆顶位置,这样可能会破坏原有堆的特性,这时需要重复步骤①的操作来恢复堆;
③重复执行步骤②,直到输出全部元素为止。按输出元素的前后次序排列起来,就是一个有序序列,从而也就完成了对排序操作。
假设待排序序列为(3,6,5,9,7,1,8,2,4),那么根据此序列创建大根堆的过程如下:
①将(3,6,5,9,7,1,8,2,4)按照二叉树的顺序存储结构转换为如下图所示的完全二叉树;
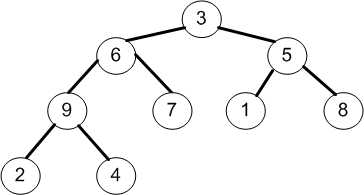
②首先,因为n=9,所以i=n/2-1=3,即调整以节点9为根的子树,由于节点9均大于它的孩子节点2和4,所以不需要交换;最后,i=i-1=2。
③当i=2时,即调整以节点5为根的子树,由于节点5小于它的右孩子8,所以5需要与8交换;最后,i=i-1=1。
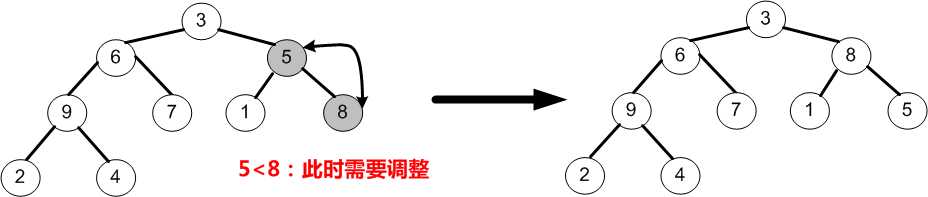
④当i=1时,即调整以节点6为根的子树,由于节点6均小于它的左、右孩子9和7,故节点6需要与较大的左孩子9交换;最后i=i-1=0。
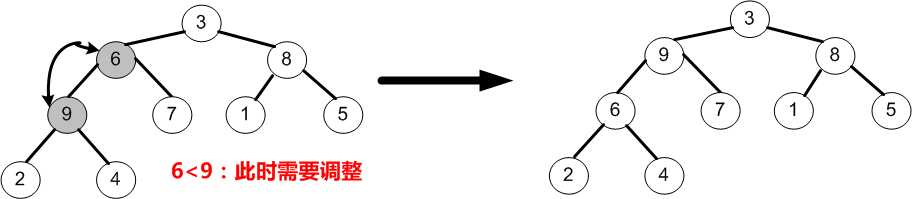
⑤当i=0时,即调整以3为根的子树,由于节点3均小于它的左、右孩子9和8,故节点3需要与较大的左孩子9交换;交换之后又因为节点3小于它的左、右孩子节点6和7,于是需要与较大的右孩子7交换。
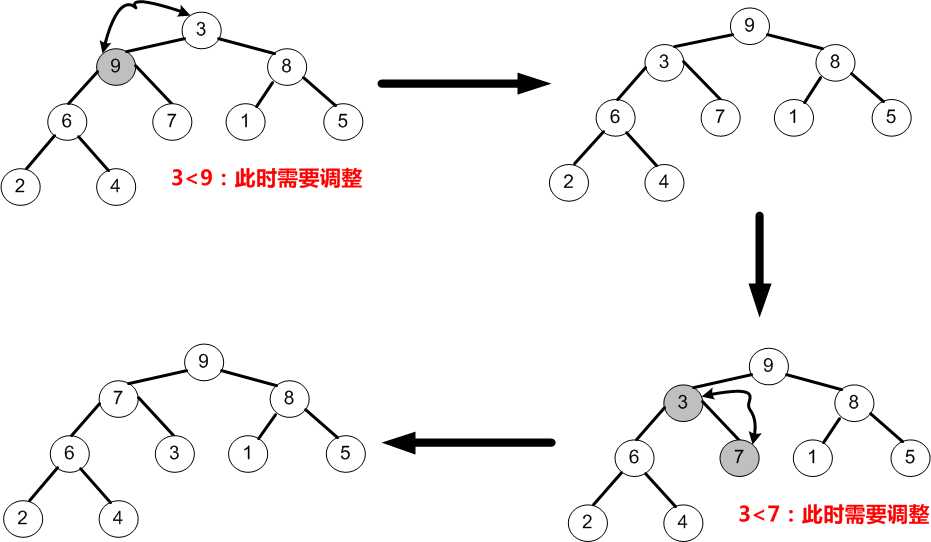
⑥如上图所示,至此就完成了初始堆的创建,待排序序列变为(9,7,8,6,3,1,5,2,4)。
// 堆排序 template<typename T> void maxHeapDown(T* array, int start, int end) { int current = start; // 当前节点位置 int left = 2 * current + 1; // 左孩子节点 T temp= array[current]; for (;left <= end; current = left,left = 2 * left + 1) { if (left < end && array[left] < array[left+1]) { left ++; } if (temp >= array[left]) { break; } else { array[current] = array[left]; array[left] = temp; } } } template<typename T> void HeapSort(T *array, int nLen) { int i; T temp; // 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆 for (i = nLen/2-1; i >=0; i --) { maxHeapDown(array, i, nLen-1); } // 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素 for (i = nLen - 1; i > 0; i--) { temp = array[0]; array[0] = array[i]; array[i] = temp; maxHeapDown(array, 0, i - 1); } }
总结:堆排序的执行时间主要由建立初始堆和反复调整堆这两个部分的时间开销组成,由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlog2n)。这在性能上显然要远远好过于冒泡、简单选择、直接插入的O(n2)的时间复杂度了。另外,由于初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况。
(1)对比条件:对10000个随机整数进行排序
(2)测试结果:


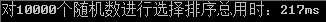

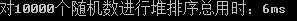
(3)全部代码

#include "stdio.h" #include<ctime> #include <stdlib.h> #include <iostream> using namespace std; #include <Windows.h> #define random(a,b) (rand()%(b-a+1)+a) class CStopwatch { private: // 64位有符号整数可以用INT64 _int64 LARGE_INTEGER表示 LARGE_INTEGER m_nPerfFrequency; LARGE_INTEGER m_nPerFrefStart; public: CStopwatch(){QueryPerformanceFrequency(&m_nPerfFrequency); Start();} void Start(){QueryPerformanceCounter(&m_nPerFrefStart);} INT64 Now() const { LARGE_INTEGER nPerfNow; QueryPerformanceCounter(&nPerfNow); return ((nPerfNow.QuadPart - m_nPerFrefStart.QuadPart) * 1000) / m_nPerfFrequency.QuadPart; } INT64 NowInMicro() const { LARGE_INTEGER nPerfNow; QueryPerformanceCounter(&nPerfNow); return ((nPerfNow.QuadPart - m_nPerFrefStart.QuadPart) * 1000000) / m_nPerfFrequency.QuadPart; } }; // 插入排序 template <typename T> void InsertSort(T *array, int nLen) { int i,j,k; for (i = 1; i < nLen; i ++) { for (j = i - 1; j >=0; j--) { if (array[i] > array[j]) { break; } } T temp = array[i]; for (k = i-1; k >j; k --) { array[k + 1] = array[k]; } array[j+1] = temp; } } template<typename T> void QuickSort_1(T *array, int start, int end) { if (array == NULL || start >= end) { return; } int i = start; int j = end; T temp = array[start]; while (i < j) { while ((i < j) && array[j] >= temp) { j --; } array[i] = array[j]; while ((i < j) && array[i] <= temp) { i ++; } array[j] = array[i]; } array[i] = temp; QuickSort_1(array, start, i - 1); QuickSort_1(array, i + 1, end); } // 快速排序 template<typename T> void QuickSort(T *array, int nLen) { if (array == NULL || nLen <= 0) { return; } QuickSort_1(array, 0, nLen - 1); } // 冒泡排序 template<typename T> void BubbleSort(T* array, int nLen) { if (array == NULL || nLen <=0 ) { return; } for (int i = 1; i < nLen; i ++) { for (int j = 0; j < nLen - i; j ++) { if (array[j+1] < array[j]) { T temp = array[j+1]; array[j] = array[j+1]; array[j+1] = temp; } } } } // 选择排序 template<typename T> void SelectSort(T *array, int nLen) { if (array == NULL || nLen <= 0) { return; } int i,j,k; for (i = 0; i < nLen - 1; i ++) { k = i; for (j = i + 1; j < nLen; j ++) { if (array[j] < array[k]) { k = j; } } if (k != i) { T temp = array[k]; array[k] = array[i]; array[i] = temp; } } } // 堆排序 template<typename T> void maxHeapDown(T* array, int start, int end) { int current = start; // 当前节点位置 int left = 2 * current + 1; // 左孩子节点 T temp= array[current]; for (;left <= end; current = left,left = 2 * left + 1) { if (left < end && array[left] < array[left+1]) { left ++; } if (temp >= array[left]) { break; } else { array[current] = array[left]; array[left] = temp; } } } template<typename T> void HeapSort(T *array, int nLen) { int i; T temp; // 从(n/2-1) --> 0逐次遍历。遍历之后,得到的数组实际上是一个(最大)二叉堆 for (i = nLen/2-1; i >=0; i --) { maxHeapDown(array, i, nLen-1); } // 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素 for (i = nLen - 1; i > 0; i--) { temp = array[0]; array[0] = array[i]; array[i] = temp; maxHeapDown(array, 0, i - 1); } } void main() { srand((unsigned)time(NULL)); //cout << "随机得到的原数组:"; int *arr = new int[10000]; for(int i=0;i<10000;i++) { arr[i] = random(1,10000); //cout << arr[i] << " "; } //cout << endl; //cout << "经过排序后得到的数组:"; CStopwatch watch; //InsertSort(arr, 10000); //BubbleSort(arr, 10000); //SelectSort(arr, 10000); //QuickSort(arr, 10000); HeapSort(arr, 10000); INT64 delay = watch.Now(); /*for (int i = 0; i < 1000; i ++) { cout << arr[i] << " "; }*/ //cout << endl; cout << "对10000个随机数进行堆排序总用时:" << delay << "ms" << endl; delete[] arr; return; }
注:参考博客:
(1)http://www.cnblogs.com/edisonchou/p/4713551.html
(2)http://www.cnblogs.com/skywang12345/p/3603935.html
标签:std now() heap sort heapsort style 概念 OWIN 破坏 quic
原文地址:https://www.cnblogs.com/xiaobingqianrui/p/8950372.html
