标签:sig png 衡量 free 计算 for 机器 范围 evel
本文主要针对Linux Kernel 2.6.28内核版本,描述了进程的概念以及调用过程。
Linux Kernel源码查阅地址:https://elixir.bootlin.com/linux/v4.6/source/include/linux/types.h
进程的一种官方定义:
进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动,也是操作系统进行资源分配和调度的一个独立单位。
简而言之,进程是操作系统为正在运行的程序所建立的一个管理实例。
而一个进程包括五个实体部:
在Linux 内核中,有一种结构体用来描述与关联进程:task_struct ,该数据结构在 /include/linux/sched.h 中被定义,它的代码量足有400行之多。
进程ID的定义保存在 include/linux/pid.h 中:
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};在此我们对其中最重要的PID进行详解。
Linux中会给进程分配一个唯一的进程ID,即PID。他是进程在系统中的唯一代号,但一个进程ID并非永久被一个进程所拥有,不同时刻运行进程所获得的PID不尽相同,使用 fork 或 clone 系统调用时产生的进程均会由内核分配一个新的唯一的PID值。
pid_t pid;如上述代码所示,PID在 task_struct 中的定义为 pid_t ,而它究其根本其实就是 int 型,故PID的实质就是一个数字。
在 include/linux/threads.h 中,系统对PID数值的最大值作出了限制。
#define PID_MAX_DEFAULT (CONFIG_BASE_SMALL ? 0x1000 : 0x8000)由此可见,一般情况下Linux系统中的进程最大数为32768个。
那么PID又从何而来? kernel/pidc 中给出了这个问题的答案:
static int alloc_pidmap(struct pid_namespace *pid_ns)
{
int i, offset, max_scan, pid, last = pid_ns->last_pid;
struct pidmap *map;
pid = last + 1;
if (pid >= pid_max)
pid = RESERVED_PIDS;
offset = pid & BITS_PER_PAGE_MASK;
map = &pid_ns->pidmap[pid/BITS_PER_PAGE];
max_scan = (pid_max + BITS_PER_PAGE - 1)/BITS_PER_PAGE - !offset;
for (i = 0; i <= max_scan; ++i) {
if (unlikely(!map->page)) {
void *page = kzalloc(PAGE_SIZE, GFP_KERNEL);
/*
* Free the page if someone raced with us
* installing it:
*/
spin_lock_irq(&pidmap_lock);
if (map->page)
kfree(page);
else
map->page = page;
spin_unlock_irq(&pidmap_lock);
if (unlikely(!map->page))
break;
}
if (likely(atomic_read(&map->nr_free))) {
do {
if (!test_and_set_bit(offset, map->page)) {
atomic_dec(&map->nr_free);
pid_ns->last_pid = pid;
return pid;
}
offset = find_next_offset(map, offset);
pid = mk_pid(pid_ns, map, offset);
/*
* find_next_offset() found a bit, the pid from it
* is in-bounds, and if we fell back to the last
* bitmap block and the final block was the same
* as the starting point, pid is before last_pid.
*/
} while (offset < BITS_PER_PAGE && pid < pid_max &&
(i != max_scan || pid < last ||
!((last+1) & BITS_PER_PAGE_MASK)));
}
if (map < &pid_ns->pidmap[(pid_max-1)/BITS_PER_PAGE]) {
++map;
offset = 0;
} else {
map = &pid_ns->pidmap[0];
offset = RESERVED_PIDS;
if (unlikely(last == offset))
break;
}
pid = mk_pid(pid_ns, map, offset);
}
return -1;
}alloc_pidmap 函数用以分配PID,而同样的, kernel/pid.h 中同样定义的回收PID的方法:
static void free_pidmap(struct upid *upid)
{
int nr = upid->nr;
struct pidmap *map = upid->ns->pidmap + nr / BITS_PER_PAGE;
int offset = nr & BITS_PER_PAGE_MASK;
clear_bit(offset, map->page);
atomic_inc(&map->nr_free);
}在Linux中,主要有6种进程状态:
| 代号 | 名称 | 描述 |
|---|---|---|
| R | TASK_RUNNING | 可执行状态 |
| S | TASK_INTERRUPTIBLE | 可中断的睡眠状态 |
| D | TASK_UNINTERRUPTIBLE | 不可中断的睡眠状态 |
| T | TASK_STOPPED or TASK_TRACED | 暂停状态或跟踪状态 |
| Z | TASK_DEAD - EXIT_ZOMBIE | 退出状态,进程成为僵尸进程 |
| X | TASK_DEAD - EXIT_DEAD | 退出状态,进程即将被销毁 |
它们在 include/linux/sched.h 中被定义:
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_STOPPED 4
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32task_struct 等少数特殊资源,故此时这种欲去还留的状态被称为僵尸(ZOMBIE)。以下这张图对系统中进程状态的转换作了简要概述:
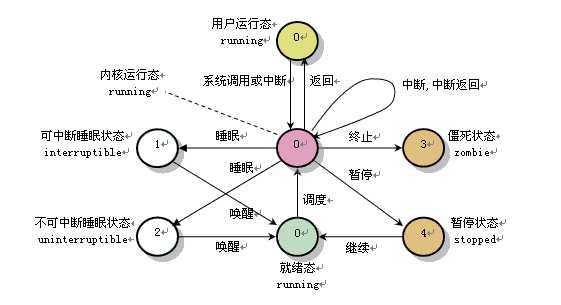
尽管系统中存在6种不同的进程状态,但进程状态的转换实质上只有TASK_RUNNING与非TASK_RUNNING之间的相互转变。
例如当一个TASK_INTERRUPTIBLE状态进程收到结束指令时,并非直接转变为TASK_DEAD状态,而是先被唤醒进入TASK_RUNNING状态,再由TASK_RUNNING状态进入TASK_DEAD状态。而当一个进程正处于TASK_RUNNING状态时,它仅有两种选择:响应信号进入TASK_STOPED或TASK_DEAD状态,否则即为执行系统调用进入TASK_INTERRUPTIBLE状态。
随着内核版本的更迭,O(1)调度器在Linux Kernel 2.6.23版本之后被CFS(完全公平调度器)所取代。
CFS使用 vruntime 以衡量进程的优先程度。它的计算公式如下
vruntime = 进程被分配的运行时间 * NICE_0_LOAD / 进程权重
其中 NICE_0_LOAD 代表nice为0的进程的权重,其值为1024,而进程权重则与nice值一一对应,借由全局数组 prio_to_weight 转换。
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};但进程运行时间又从何得知呢?
它的计算公式为 进程实际运行时间 = 调度周期 * 进程权重 / 所有进程权重之和
其中调度周期是将所有处于TASK_RUNNING状态的进程都调度一遍的时间。
如若将进程运行理想化,即将进程实际运行时间当做系统分配给它的运行时间,再联系上两式可得
vruntime = (调度周期 * 进程权重 / 所有进程权重之和)* 1024 / 进程权重 = 调度周期 * 1024 / 所有进程总权重
借由上式我们可以发现:即使不同进程的权重不尽相同,但理想情况下 vruntime 理当相同,故如若一个进程的 vruntime 值较小,也就说明它没有得到它应得的运行时间,此时操作系统理应优先选择它运行。
以上即是CFS的主要思想。
vruntime 与进程权重等保存在 sched_entity 数据结构中,它是一个调度实体,在 include/linux/sched.h 中被定义:
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 last_wakeup;
u64 avg_overlap;
#ifdef CONFIG_SCHEDSTATS
u64 wait_start;
u64 wait_max;
u64 wait_count;
u64 wait_sum;
u64 sleep_start;
u64 sleep_max;
s64 sum_sleep_runtime;
u64 block_start;
u64 block_max;
u64 exec_max;
u64 slice_max;
u64 nr_migrations;
u64 nr_migrations_cold;
u64 nr_failed_migrations_affine;
u64 nr_failed_migrations_running;
u64 nr_failed_migrations_hot;
u64 nr_forced_migrations;
u64 nr_forced2_migrations;
u64 nr_wakeups;
u64 nr_wakeups_sync;
u64 nr_wakeups_migrate;
u64 nr_wakeups_local;
u64 nr_wakeups_remote;
u64 nr_wakeups_affine;
u64 nr_wakeups_affine_attempts;
u64 nr_wakeups_passive;
u64 nr_wakeups_idle;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
};不同的sched_entity 由一个以时间为顺序的红黑树组织在一起:

vurtime 值最小的进程储存在树的左侧,如此便可以迅速选中 vruntime 值最小的进程。
长久以来,操作系统都试图对公平下定义,是否交互式进程就一定具有绝对话语权?CFS给出了他的答案,它不再企图区分交互式进程,而是对所有进程都一视同仁,就如它的名字一样,Completely Fair。它的出现令赫赫有名的O(1)调度器也仅是昙花一现,Linux发展至今已跨越诸多版本,而CFS始终没有被取代,它用自己独特的优越性宣示着自己的主权。
第一次作业:Linux 2.6.28进程模型与CFS调度器分析
标签:sig png 衡量 free 计算 for 机器 范围 evel
原文地址:https://www.cnblogs.com/xeathens/p/8955052.html