标签:连续 com 表示 bsp 代码 nbsp 特殊字符 操作 很多
try: ‘‘‘可能会出现异常的代码‘‘‘ except ValueError: ‘‘‘‘打印一些提示或者处理的内容‘‘‘ except NameError: ‘‘‘...‘‘‘ except Exception: ‘‘‘万能异常不能乱用‘‘‘
try:
‘‘‘可能会出现异常的代码‘‘‘
except ValueError:
‘‘‘‘打印一些提示或者处理的内容‘‘‘
except NameError:
‘‘‘...‘‘‘
except Exception:
‘‘‘万能异常不能乱用‘‘‘
else:
‘‘‘以上所有的except都不执行‘‘‘
try:
‘‘‘可能会出现异常的代码‘‘‘
except ValueError:
‘‘‘打印一些提示或者处理的内容‘‘‘
else:
‘‘‘try中的代码正常执行了‘‘‘
finally:
‘‘‘无论错误是否发生,都会执行这段代码,用来做一些首尾工作‘‘‘
number = input(‘please input your phone number:‘)
if number.isdigit() and number.startswith(‘13‘) or number.startswith(‘14‘) or number.startswith(‘15‘) or number.startswith(‘16‘) or number.startswith(‘17‘) or number.startswith(‘18‘) or number.startswith(‘19‘):
print(‘通过检查‘)
else:
print(‘格式错误‘)
上面的代码太冗长了,使用正则
number = input(‘please input your phone number:‘)
ret = re.match(‘(13|14|15|16|17|18|19)[0-9]{9}‘,number)
if ret:print(‘通过初检查‘)
实例一:
匹配出手机号码,就可以使用正则了。
with open(‘a‘,encoding=‘utf-8‘)as f1:
li = []
for i in f1:
i = i.strip()
ret = re.findall(‘1[3-9]\d{9}‘,i)
li.extend(ret) #extend 合并
print(li)
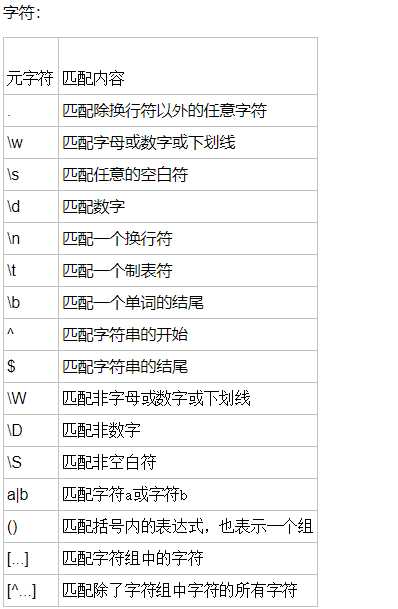
正则表达式
在线测试工具 http://tool.chinaz.com/regex/
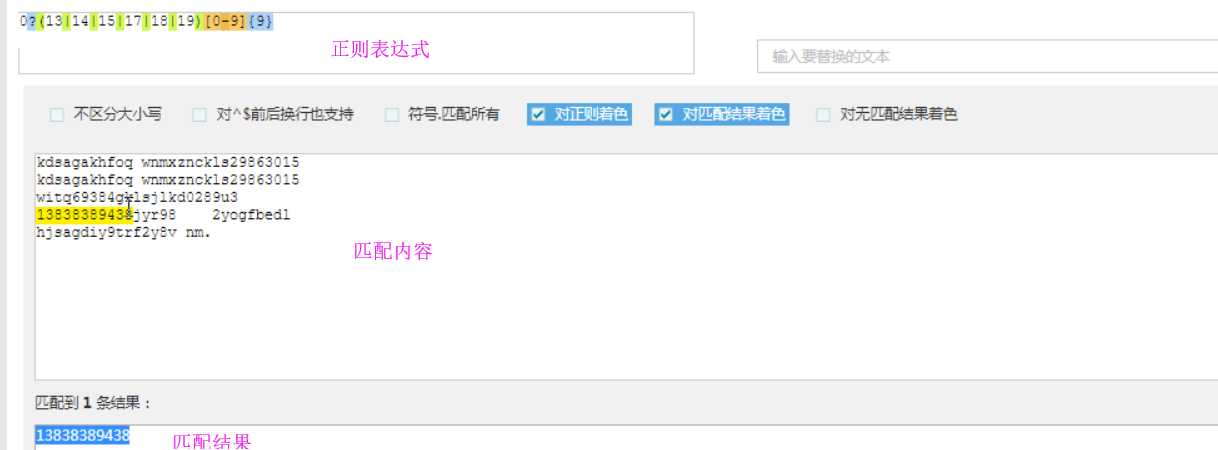

那么在之后我们更多要考虑的是在同一个位置上可以出现的字符的范围。
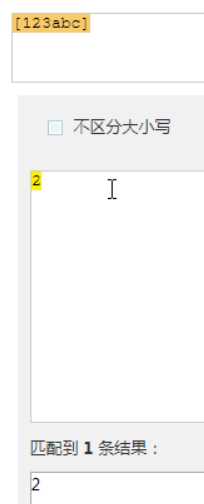
字符组 : [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字、字母、标点等等。
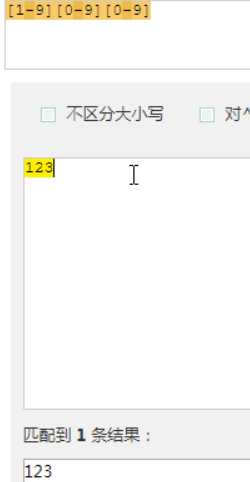
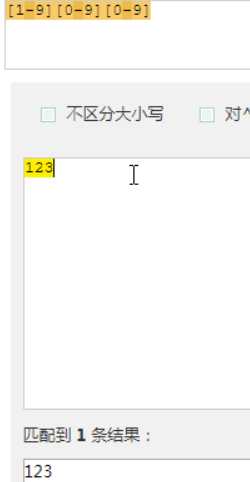
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。

匹配大写

大小写匹配
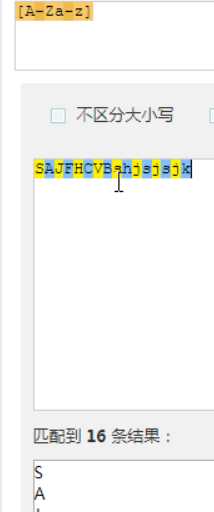


.是万能的,除了换行符以外
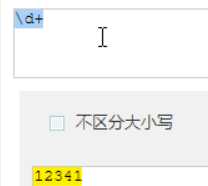
匹配空白
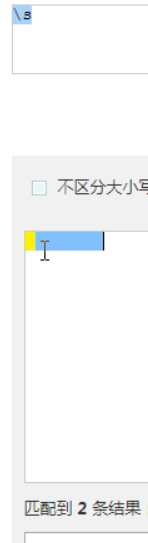
重点
|
^
|
匹配字符串的开始
|
|
$
|
匹配字符串的结尾
|

以海开头
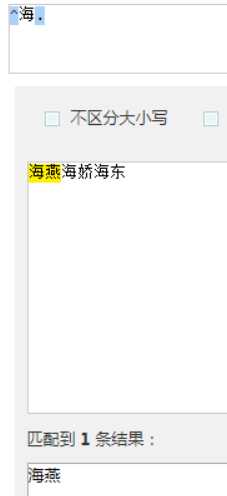
正则表达式,不能写在后面

它只能出现在开始位置不能在中间或者后面位置




这种情况,是唯一ke可以放到任意位置的


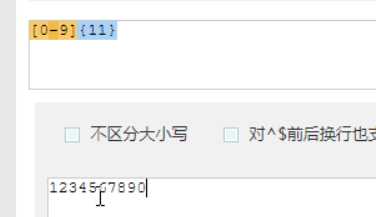
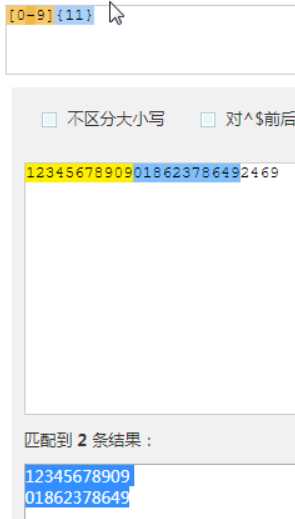
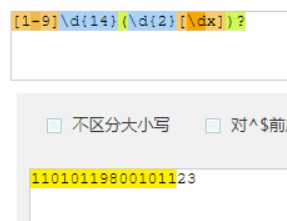
表示匹配11位以上,不能低于11位
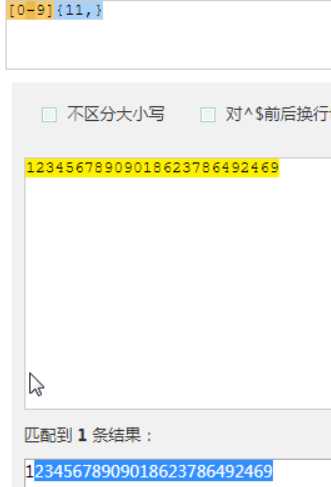
匹配15位,往多的匹配
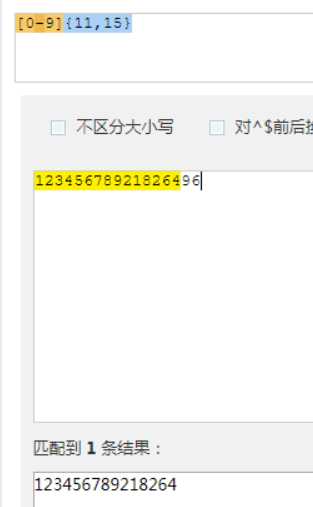
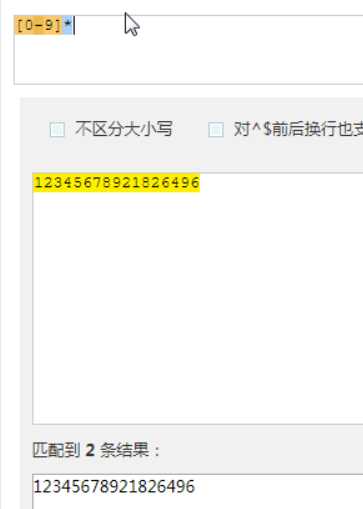
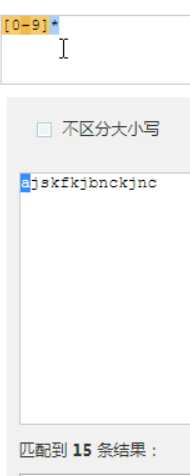
匹配1次或者多次
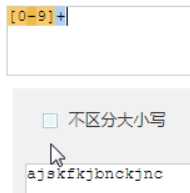
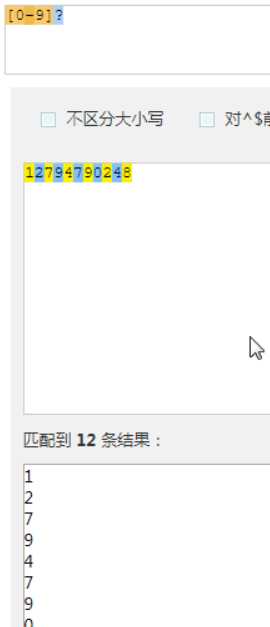
重点:
量词只能约束一个字符串
这里的约束[A-Z]
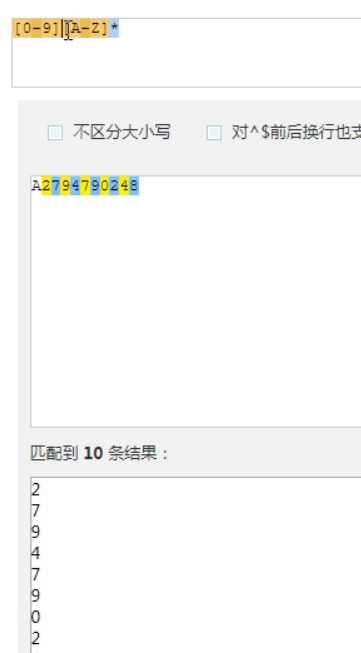
同时约束[0-9]和[A-Z]
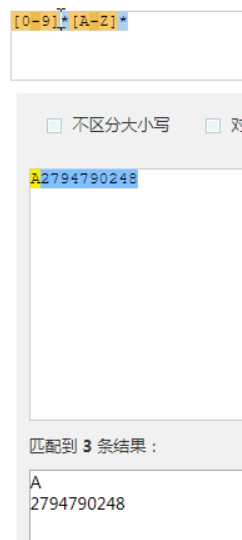

最多2次
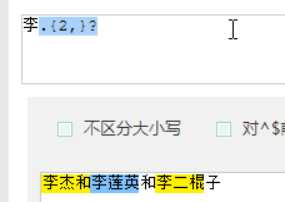
带红线,不是重要的
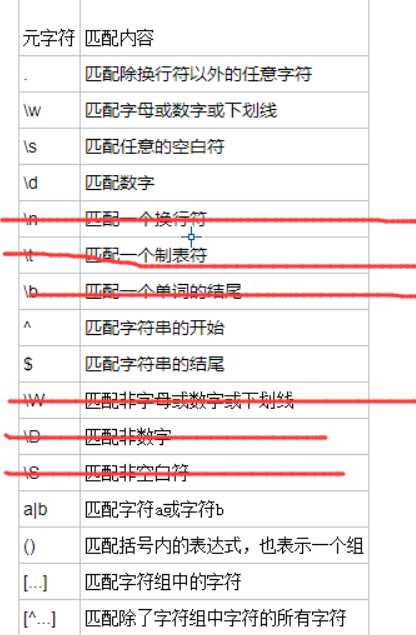
元字符,应该和量词使用


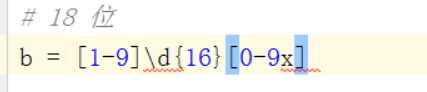

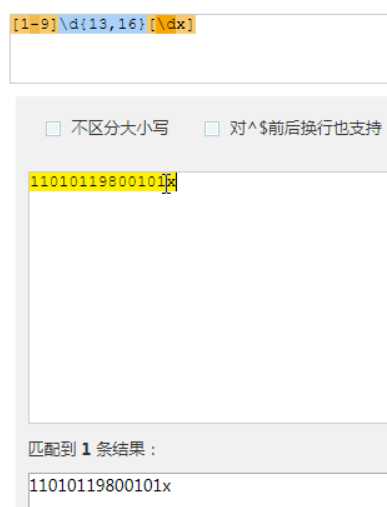

需求对二个约束
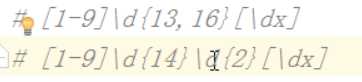
写这样写不好

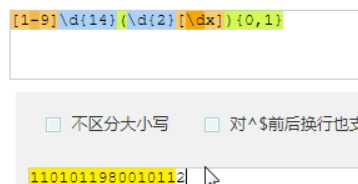
至少匹配15次
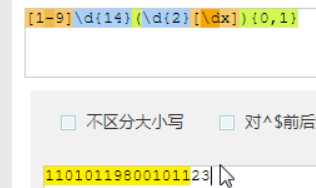
这样写,就比较专业

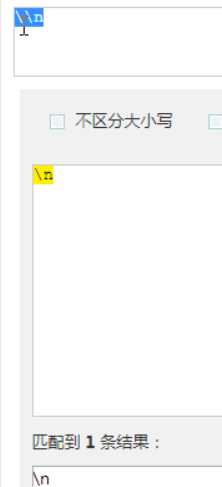
2个下划线就是转义

结果就是一项
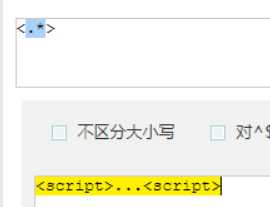
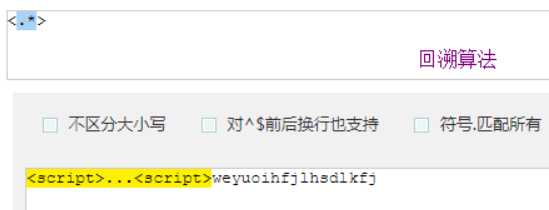
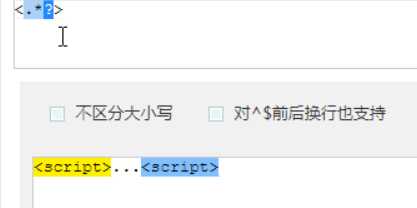
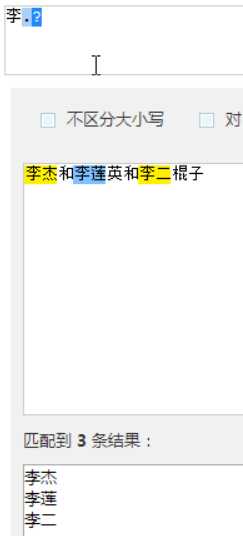
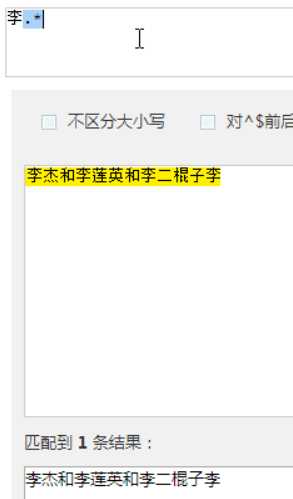
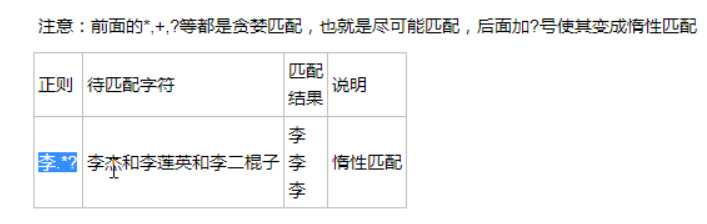
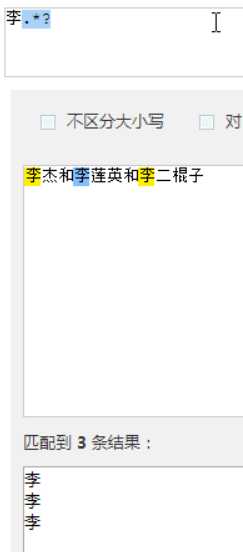
?先匹配后面的。
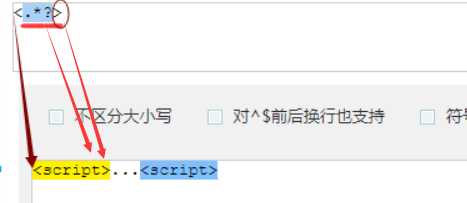
几个常用的非贪婪匹配Pattern
| 匹配字符 | 说明 |
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
标签:连续 com 表示 bsp 代码 nbsp 特殊字符 操作 很多
原文地址:https://www.cnblogs.com/haowen980/p/8968878.html