标签:模式匹配 sans targe 表达式 字母数 字符集 tool .com 其他
可以读懂你写的正则表达式
根据你写的表达式去执行任务
用re去操作正则
使用一些规则来检测一些字符串是否符合个人要求,从一段字符串中找到符合要求的内容。在线测试网站: http://tool.chinaz.com/regex/
元字符:更加笼统的匹配
|
元字符 |
匹配内容 |
|
. |
匹配除换行符以外的任意字符 |
|
^ |
只匹配字符串的开始 |
|
$ |
只匹配字符串的结束 |
|
\w |
匹配字母或数字或下划线 |
|
\s |
匹配任意空白符 |
|
\d |
匹配数字 |
|
\n |
匹配一个换行符 |
|
\t |
匹配一个制表符 |
|
\W |
匹配非字母数字和下划线 |
|
\S |
匹配非空白符 |
|
\D |
匹配非数字 |
|
a|b |
匹配字符a或b |
|
() |
匹配括号内的表达式,也表示一个组 |
|
[ ] |
匹配字符组的字符 |
|
[^ ] |
匹配除了字符组中字符的所有字符 |
量词:
|
量词 |
用法说明 |
|
* |
重复零次或更多次 |
|
+ |
重复一次或更多次 |
|
? |
重复零次或一次 |
|
{n} |
重复n次 |
|
{n,} |
重复n次或更多次 |
|
{n,m} |
重复n到m次 |
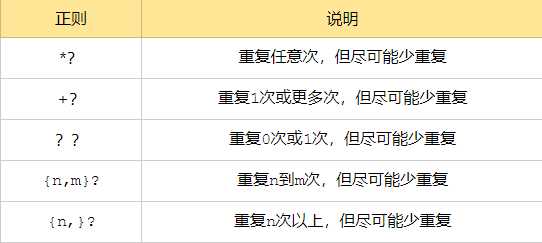
.*?的用法说明:
. 任意字符
* 取0至无限长度
? 非贪婪模式
.*?x 合在一起表示取尽量少的任意字符,知道一个x出现
其他使用说明:
* + ? { }:
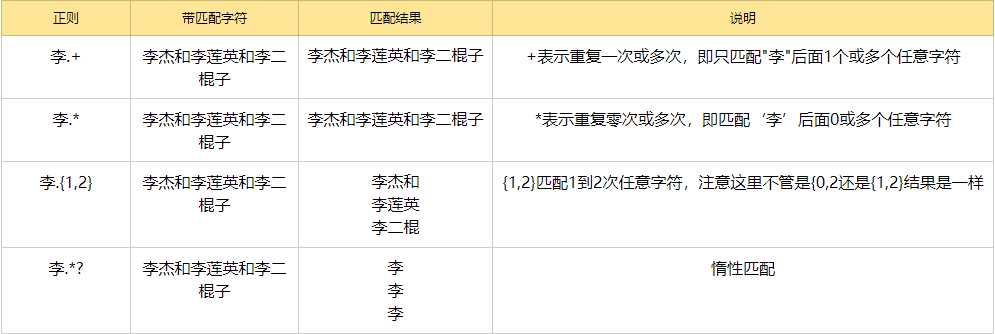
注: *,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
字符集[][^]:
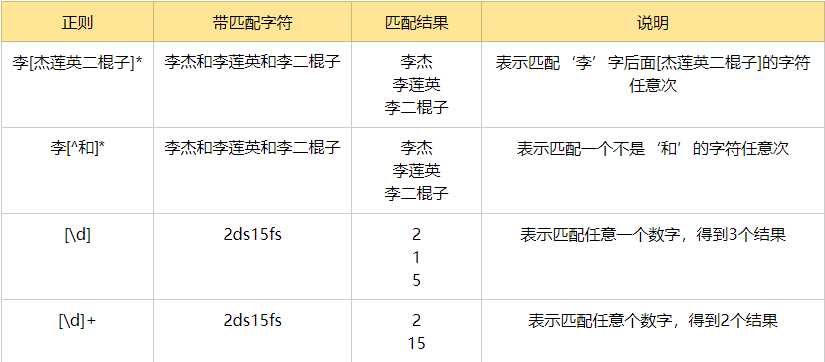
分组 ()与 或 |[^]:
身份证号是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能是0
如果是18位,则前17位全部是数字,末尾可能是x
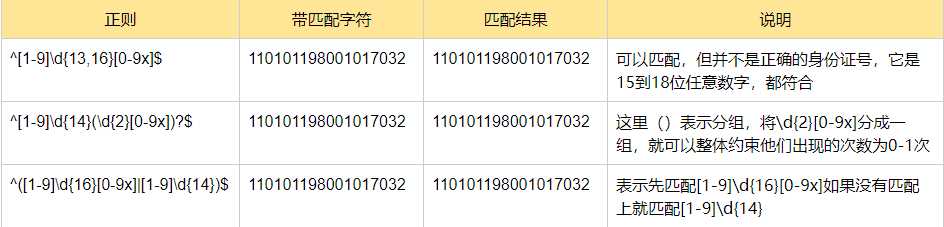
转义符 \:
在正则中,存在很多特殊意义的元字符,如\d,\s等,如果要在正则中匹配正常的‘\d’而不是‘数字’就需要对‘\d’进行转义,变成‘\\’
在py中,无论是正则表达式还是待匹配内容都是以字符串形式出现的,字符串中\也有特殊含义,本身也需要转义,这时候就要用到r‘\d’转换
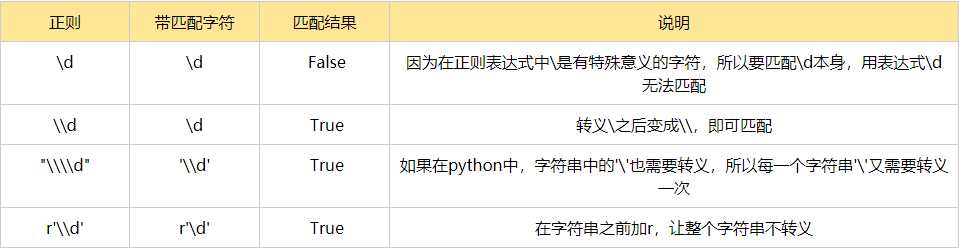
贪婪匹配:
满足匹配时,匹配尽可能长的字符串

几个常用非贪婪匹配格式
import re
ret = re.findall(‘a‘, ‘eva egon yuan‘)
print(ret) # [‘a‘, ‘a‘]
ret = re.findall(‘\d+‘, ‘dsaglhlkdfh1892494kashdgkjh127839‘)
print(ret) # [‘1892494‘, ‘127839‘]
# findall接收两个参数 : 正则表达式 要匹配的字符串
# 一个列表数据类型的返回值:所有和这条正则匹配的结果
ret = re.search(‘a‘, ‘eavegonyaun‘).group()
print(ret) # a
# 函数会在字符串内查找模式匹配,直到找到第一个匹配然后返回一个包含匹配信息的对象,该
# 对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,未调用group时
# 则返回None。
# search和findall的区别:
# 1.search找到一个就返回,findall是找所有
# 2.findall是直接返回一个结果的列表,search返回一个对象
ret = re.match(‘a‘, ‘eva egon yuan‘)
if ret:
print(ret.group())
# 意味着在正则表达式中添加了一个^
# 同search,不过尽在字符串开始处进行匹配
ret = re.sub(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘, 2)
print(ret) # evaHegonHyuan4
# 将前两个数字换成H
ret = re.subn(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘)
print(ret) # (‘evaHegonHyuanH‘, 3)
# #将数字替换成‘H‘,返回元组(替换的结果,替换了多少次)
ret = re.split("\d+", "eva3egon4yuan")
print(ret) # [‘eva‘, ‘egon‘, ‘yuan‘]
ret = re.split("(\d+)", "eva162784673egon44yuan")
print(ret) # [‘eva‘, ‘3‘, ‘egon‘, ‘4‘, ‘yuan‘]
# split分割一个字符串,默认被匹配到的分隔符不会出现在结果列表中,
# 如果将匹配的正则放到组内,就会将分隔符放到结果列表里
# 在多次执行同一条正则规则的时:
obj = re.compile(‘\d{3}‘)
ret1 = obj.search(‘abc123eeee‘)
ret2 = obj.findall(‘abc123eeee‘)
print(ret1.group()) # 123
print(ret2) # [‘123‘]
# 如果匹配文件中的手机号,可以进行这样的一次编译,节省时间
# finditer适用于结果比较多的情况下,能够有效的节省内存
ret = re.finditer(‘\d‘, ‘ds3sy4784a‘)
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) # 查看第一个结果
print(next(ret).group()) # 查看第二个结果
print([i.group() for i in ret]) # 查看剩余的左右结果
分组:
如果对一组正则表达式整体有一个量词约束,就将这一组表达是分成一个组
# 当分组遇到re模块
import re
ret1 = re.findall(‘www.(baidu|oldboy).com‘, ‘www.baidu.com‘)
ret2 = re.findall(‘www.(?:baidu|oldboy).com‘, ‘www.baidu.com‘)
print(ret1)
print(ret2)
# findall会优先显示组内匹配到的内容返回
# 如果想取消分组优先效果,在组内开始的时候加上?:
# 分组的意义
# 1.对一组正则规则进行量词约束
# 2.从一整条正则规则匹配的结果中优先显示组内的内容
# "<h1>hello</h1>"
ret = re.findall(‘<\w+>(\w+)</\w+>‘, "<h1>hello</h1>")
print(ret) # [‘hello‘]
# 分组命名
ret = re.search("<(?P<tag>\w+)>(?P<content>\w+)</(?P=tag)>", "<h1>hello</h1>")
print(ret.group()) # <h1>hello</h1>,search中没有分组优先的概念
print(ret.group(‘tag‘)) # h1
print(ret.group(‘content‘)) # hello
# 如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
# 获取的匹配结果可以直接用group(序号)拿到对应的值
ret = re.search(r"<(\w+)>(\w+)</\1>", "<h1>hello</h1>")
print(ret.group()) # <h1>hello</h1>
print(ret.group(0)) # <h1>hello</h1>
print(ret.group(1)) # h1
print(ret.group(2)) # hello
标签:模式匹配 sans targe 表达式 字母数 字符集 tool .com 其他
原文地址:https://www.cnblogs.com/LearningOnline/p/8967704.html