标签:过滤 调用 ble bsp 运行 只读 内存 方法 本质
函数就相当于一个文件,这个文件有他特定的功能可以减少代码的重写
1 def 函数名 (参数): 2 "函数的注释" 3 函数体 4 return x
若命名了相同的函数名,则调用函数时下面的函数会覆盖掉上面的函数
1.代码重用
2.保持一致性,易维护
3.可扩展性
1.返回值数值 = 0 >>>>>返回None
2.返回值数 = 1 >>>>> 返回object 字典的对象
3.返回值数 > 1 >>>>> 返回元组
1.形参:不占内存,用完释放
2..实参
3.位置参数和关键字参数
位置参数:按顺序一一对应
关键字参数:可指定参数对应,可无序
位置参数与关键字参数混合使用:位置参数应在关键字参数左边 ,否则报错
4.默认参数
若函数定义时指定了默认参数,则函数调用时,可不写参数就用默认参数,写了参数就修改默认参数
5.参数组:*列表 **字典
使用参数组的好处:函数未来扩展功能需传多个值或者你不确定传几个值
全局变量为定义在函数外部的变量
局部变量为定义在函数内部的变量
所以书写时全局变量大写,局部变量小写清晰方便让他人读懂
golobal 指定全局变量
nonlocal 指定上一级变量
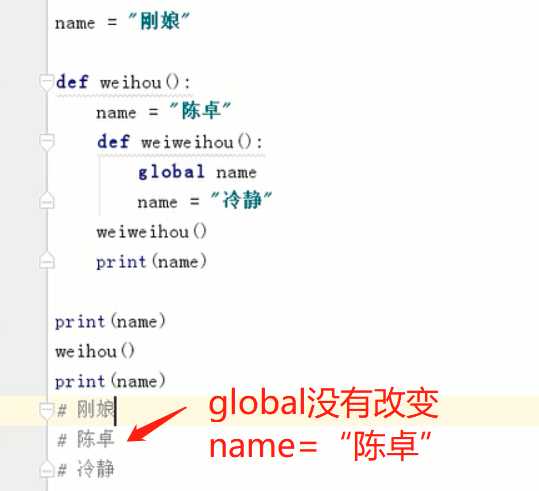
总结:
有声明局部变量:使用局部变量
无声明局部变量:
| 无global | 优先读取局部变量,只读全局变量不对全局变量赋值 |
| 有global | 变量本质上就是全局变量可读可赋值 |
当使用global定义变量时,global应上提,防止报错
a = [‘c‘,‘d‘] def test(): a = ‘我‘ global a #报错!因为global在下面不知道去哪找a所以global应该上提 print(a)
递归就是函数内部不断的调用自己
1.必须有一个明确的结束条件,否则死循环
2.每次进入更深一层递归,问题规模相应比上次少
3.递归的效率不高,层次过大会导致栈溢出
寸到
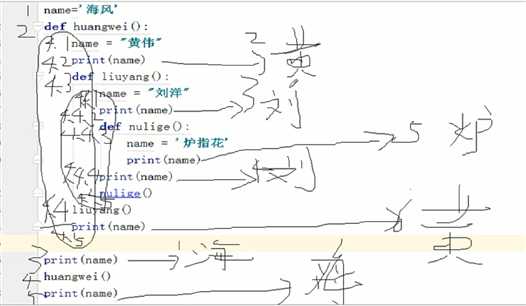
程序是从上到下一直读下去的,其实当程序读到def ...定义函数部分时,只是把函数部分全部转换成字符串存到内存当中,不读取,直到调用函数时才读取。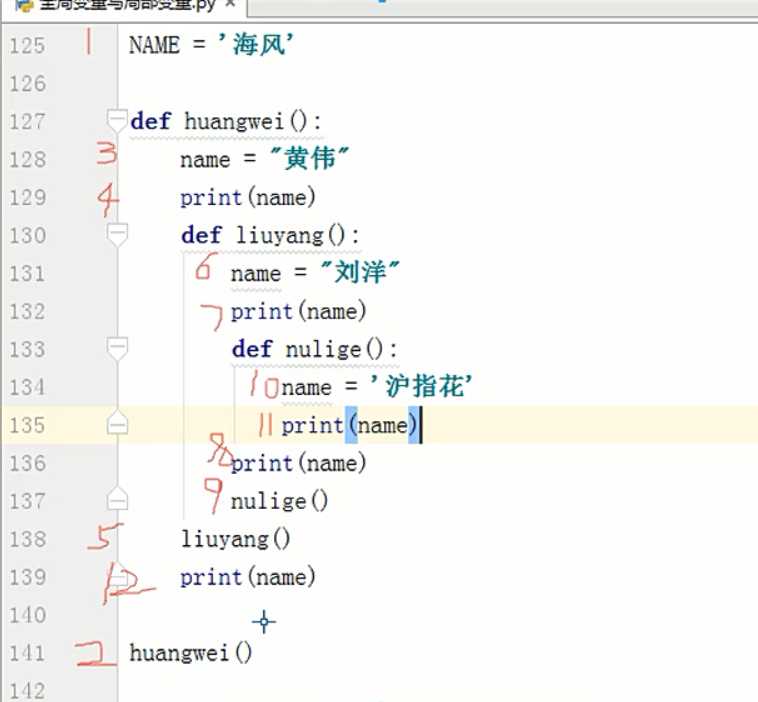
匿名函数只使用于定义简单逻辑的函数
def test(x): return x+1 #使用匿名函数: lambda x:x+1
#若匿名函数接收多个参数,返回多个值则需加括号 lambda x,y,z:(x+1,y+1,z+1)
匿名函数不独立使用,若真要独立使用就得给他起个名字才能运行
fuc = lambda x:x+1 fuc(10)
1.不可变数据
2.第一类对象:函数即为变量
3.尾调用优化(尾递归)
例一:不可变,不用变量保存状态,不修改变量
#非函数式: a = 1 def test(): global a a += 1 return a test() print(a)
#函数式编程 a = 1 def test(n): return n+1 print(test(a) print(a)
高阶函数有一下两个特性,有任何一即为高阶函数
#1.函数的传入参数是一个函数名 def foo(n) print(n) def bar(name) print(‘my name is %s‘ %name) foo(bar(‘echo‘)) #先运行bar()无返回值
#2.返回值中包含函数 def bar (): print(‘from bar‘) def foo(): print(‘from bar ‘) return bar #返回bar的内存地址 n = foo() n() #调用bar函数
1.map函数的起源及其用法
map函数就是在原有的数据上处理下数据
array=[1,3,4,71,2] ret=[] for i in array: ret.append(i**2) print(ret) #如果我们有一万个列表,那么你只能把上面的逻辑定义成函数 def map_test(array): ret=[] for i in array: ret.append(i**2) return ret print(map_test(array)) #如果我们的需求变了,不是把列表中每个元素都平方,还有加1,减一,那么可以这样 def add_num(x): return x+1 def map_test(func,array): ret=[] for i in array: ret.append(func(i)) return ret print(map_test(add_num,array)) #可以使用匿名函数 print(map_test(lambda x:x-1,array)) #上面就是map函数的功能,map得到的结果是可迭代对象 print(map(lambda x:x-1,range(5)))
2.filter函数是过滤,默认保留指定参数
#电影院聚集了一群看电影bb的傻逼,让我们找出他们 movie_people=[‘alex‘,‘wupeiqi‘,‘yuanhao‘,‘sb_alex‘,‘sb_wupeiqi‘,‘sb_yuanhao‘] def tell_sb(x): return x.startswith(‘sb‘) def filter_test(func,array): ret=[] for i in array: if func(i): ret.append(i) return ret print(filter_test(tell_sb,movie_people)) #函数filter,返回可迭代对象 print(filter(lambda x:x.startswith(‘sb‘),movie_people))
3.reduce函数:压缩数据为一个所以reduce
reduce在py3中要引用模块
from functools import reduce
from functools import reduce #合并,得一个合并的结果 array_test=[1,2,3,4,5,6,7] array=range(100) #报错啊,res没有指定初始值 def reduce_test(func,array): l=list(array) for i in l: res=func(res,i) return res # print(reduce_test(lambda x,y:x+y,array)) #可以从列表左边弹出第一个值 def reduce_test(func,array): l=list(array) res=l.pop(0) for i in l: res=func(res,i) return res print(reduce_test(lambda x,y:x+y,array)) #我们应该支持用户自己传入初始值 def reduce_test(func,array,init=None): l=list(array) if init is None: res=l.pop(0) else: res=init for i in l: res=func(res,i) return res print(reduce_test(lambda x,y:x+y,array)) print(reduce_test(lambda x,y:x+y,array,50))
map ,filtet,reduce 总结
当然了,map,filter,reduce,可以处理所有数据类型 name_dic=[ {‘name‘:‘alex‘,‘age‘:1000}, {‘name‘:‘wupeiqi‘,‘age‘:10000}, {‘name‘:‘yuanhao‘,‘age‘:9000}, {‘name‘:‘linhaifeng‘,‘age‘:18}, ] #利用filter过滤掉千年王八,万年龟,还有一个九千岁 def func(x): age_list=[1000,10000,9000] return x[‘age‘] not in age_list res=filter(func,name_dic) for i in res: print(i) res=filter(lambda x:x[‘age‘] == 18,name_dic) for i in res: print(i) #reduce用来计算1到100的和 from functools import reduce print(reduce(lambda x,y:x+y,range(100),100)) print(reduce(lambda x,y:x+y,range(1,101))) #用map来处理字符串列表啊,把列表中所有人都变成sb,比方alex_sb name=[‘alex‘,‘wupeiqi‘,‘yuanhao‘] res=map(lambda x:x+‘_sb‘,name) for i in res: print(i)
详细请查看http://www.runoob.com/python/python-built-in-functions.html
1.abs() 取绝对值
2.布尔运算
| bool() | 将括号内元素转换为布尔值 |
|
all() |
将括号内元素全部进行布尔运算,全真才为真 |
| any() | 将括号内元素全部进行布尔运算,一个真则真 |
3.进制转换
| bin() | 转为二进制 |
| hex() | 转为16进制 |
| oct() | 转为8进制 |
4.bytes()查看多少字节,可指定编码解码,也可不指定
name = ‘您好‘ print(bytes(name ,encoding = ‘utf-8‘,decode‘utf-8))
5.ASCII码处理
| chr() | 打印ASCII码 |
| ord() | 与chr()相反,解asci码 |
6.数字处理
| divmod() | 传入两个参数,取商与余 |
| pow() | 可穿三个参数,最少传2个,若传pow(3,3,2)则求3的3次方后对2取余 |
| round() | 四舍五入 |
7.查看函数使用
| dir() | 查看参数的属性 |
| help | 查看函数的使用 |
8.eval
第一个功能就是把字符串中的数据结构提取出来
第二个功能就是把字符串中表达式计算
9.hash:可hash的数据类型就是不可变数据类型
10.isinstance:输入两个参数,一个是变量,一个 是指定数据类型,查看是否变量是否为指定类型
11.globals()和locals() 联合print()打印本地与局部
12.max()与min()
for循环依次去出元素比较,若开头已比较出结果则后面不比较(比较字符串时或其他)
注意不可有多种数据类型
其返回的是内存地址
12.1.max函数处理的是可迭代对象,相当于一个for循环取出每个元素进行比较。不同数据类型间不能进行比较
12.2.每个元素进行比较,若字符串则从第一个字符开始,若第一个位置分出大小,则后面不比较
#终极玩法 people= [ {‘name ‘ =‘haha‘, ‘age‘ = 100} {‘name‘ = ‘echo‘ , ‘age‘ = 500} ] print(max(people,key=lambd dic:dic[‘age‘]))
key 代表告诉max通过什么方法去比较出每个对象的大小
13.zip() 拉链:输入两个参数,这两个参数为序列然后一一对应转为元组,有多不显示不报错,返回内存地址要用list查看
14.reverse 反转 ,可以反转列表
15.slice 切片:指定切片
l = ‘hello‘ s1 = slice(1,4,2) print(l(s1)) print(s1.start) print(s1.end) print(s1.step) #查看步长
16.sorted 排序:本质比较大小,不同类型不能排序
17 sum :求和
18.type : 查看参数是那种类型
标签:过滤 调用 ble bsp 运行 只读 内存 方法 本质
原文地址:https://www.cnblogs.com/echoboy/p/8973266.html