标签:bug 特殊 efi 也有 orm 产生 轮询 内存管理 lead
进程:指在系统中能独立运行并作为资源分配的基本单位,它是由一组机器指令、数据和堆栈等组成的,是一个能独立运行的活动实体。
1.动态性:进程的实质是程序的一次执行过程,进程是动态产生,动态消亡的。
2.并发性:任何进程都可以同其他进程一起并发执行。
3.独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位。
4.异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进。
task_struct 是Linux内核的一种数据结构,它被装在到RAM里并且包含着进程的信息。每个进程都把它的信息放在 task_struct 这个数据结构中, task_struct 包含了以下内容:
标识符:描述本进程的唯一标识符,用来区别其他进程。
状态:任务状态,退出代码,退出信号等。
优先级:相对于其他进程的优先级。
程序计数器:程序中即将被执行的下一条指令的地址。
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
上下文数据:进程执行时处理器的寄存器中的数据。
I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息:可以包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
保存进程信息的数据结构叫做 task_struct ,并且可以在 include/linux/sched.h 里找到它。所以运行在系统里的进程都以 task_struct 链表的形式存在于内核中。
2.1.1. 进程状态
volatile long state; int exit_state;
2.1.2. state成员的可能取值
#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define __TASK_STOPPED 4 #define __TASK_TRACED 8 /* in tsk->exit_state */ #define EXIT_ZOMBIE 16 #define EXIT_DEAD 32 /* in tsk->state again */ #define TASK_DEAD 64 #define TASK_WAKEKILL 128 #define TASK_WAKING 256
2.1.3. 进程的各个状态
| TASK_RUNNING | 表示进程正在执行或者处于准备执行的状态 |
| TASK_INTERRUPTIBLE | 进程因为等待某些条件处于阻塞(挂起的状态),一旦等待的条件成立,进程便会从该状态转化成就绪状态 |
| TASK_UNINTERRUPTIBLE | 意思与TASK_INTERRUPTIBLE类似,但是我们传递任意信号等不能唤醒他们,只有它所等待的资源可用的时候,他才会被唤醒。 |
| TASK_STOPPED | 进程被停止执行 |
| TASK_TRACED | 进程被debugger等进程所监视。 |
| EXIT_ZOMBIE | 进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程成为僵尸进程 |
| EXIT_DEAD | 进程被杀死,即进程的最终状态。 |
| TASK_KILLABLE | 当进程处于这种可以终止的新睡眠状态中,它的运行原理类似于 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号 |
2.1.4. 状态转换图
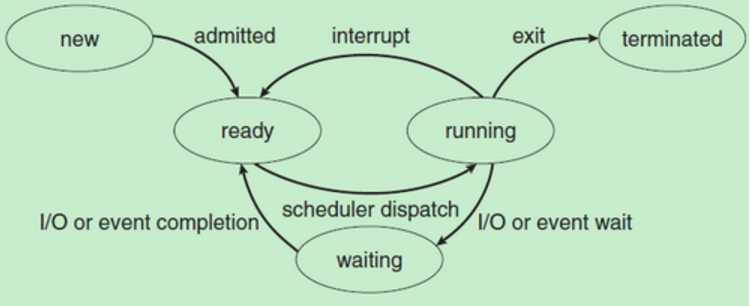
2.2.1. 标识符定义
pid_t pid; //进程的标识符
2.2.2. 关于标识符
pid是 Linux 中在其命名空间中唯一标识进程而分配给它的一个号码,称做进程ID号,简称PID。
程序一运行系统就会自动分配给进程一个独一无二的PID。进程中止后PID被系统回收,可能会被继续分配给新运行的程序。
是暂时唯一的:进程中止后,这个号码就会被回收,并可能被分配给另一个新进程。
2.3.1. 标记符
unsigned int flags; /* per process flags, defined below */
flags反应进程的状态信息,用于内核识别当前进程的状态。
2.3.2. flags的取值范围
#define PF_EXITING 0x00000004 /* getting shut down */ #define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */ #define PF_VCPU 0x00000010 /* I‘m a virtual CPU */ #define PF_WQ_WORKER 0x00000020 /* I‘m a workqueue worker */ #define PF_FORKNOEXEC 0x00000040 /* forked but didn‘t exec */ #define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */ #define PF_SUPERPRIV 0x00000100 /* used super-user privileges */ #define PF_DUMPCORE 0x00000200 /* dumped core */ #define PF_SIGNALED 0x00000400 /* killed by a signal */ #define PF_MEMALLOC 0x00000800 /* Allocating memory */ #define PF_NPROC_EXCEEDED 0x00001000 /* set_user noticed that RLIMIT_NPROC was exceeded */ #define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */ #define PF_USED_ASYNC 0x00004000 /* used async_schedule*(), used by module init */ #define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */ #define PF_FROZEN 0x00010000 /* frozen for system suspend */ #define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */ #define PF_KSWAPD 0x00040000 /* I am kswapd */ #define PF_MEMALLOC_NOIO 0x00080000 /* Allocating memory without IO involved */ #define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */ #define PF_KTHREAD 0x00200000 /* I am a kernel thread */ #define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */ #define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */ #define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_allowed */ #define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */ #define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */ #define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */ #define PF_SUSPEND_TASK 0x80000000 /* this thread called freeze_processes
下面列出几个常用的状态。
| 状态 | 描述 |
|---|---|
| PF_FORKNOEXEC | 表示进程刚被创建,但还没有执行 |
| PF_SUPERPRIV | 表示进程拥有超级用户特权 |
| PF_SIGNALED | 表示进程被信号杀出 |
| PF_EXITING | 表示进程开始关闭 |
struct task_struct __rcu *real_parent; /* real parent process */ struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */ /* * children/sibling forms the list of my natural children */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent‘s children list */ struct task_struct *group_leader; /* threadgroup leader */
可以用下面这些通俗的关系来理解它们:real_parent是该进程的”亲生父亲“,不管其是否被“寄养”;parent是该进程现在的父进程,有可能是”继父“;这里children指的是该进程孩子的链表,可以得到所有孩子的进程描述符,但是需使用list_for_each和list_entry,list_entry其实直接使用了container_of,同理,sibling该进程兄弟的链表,也就是其父亲的所有孩子的链表。用法与children相似;struct task_struct *group_leader这个是主线程的进程描述符,也许你会奇怪,为什么线程用进程描述符表示,因为linux并没有单独实现线程的相关结构体,只是用一个进程来代替线程,然后对其做一些特殊的处理;struct list_head thread_group;这个是该进程所有线程的链表。
CFS(完全公平调度器)是Linux内核2.6.23版本开始采用的进程调度器,它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。它的基本原理如下:设定一个调度周期( sched_latency_ns ),目标是为了让每个进程在这个周期内至少有机会运行一次,也可以说就是每个进程等待CPU的时间最长不超过这个调度周期;然后根据进程的数量,所有进程平分这个调度周期内的CPU使用权,由于进程的优先级即nice值不同,分割调度周期的时候要加权;每个进程的累计运行时间保存在自己的vruntime字段里,哪个进程的vruntime最小就获得本轮运行的权利。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越。
宏 SCHED_NOMAL 和 SCHED_BATCH 主要用于CFS调度。这几个宏的定义可以在 include/linux/sched.h 中找到。文件 kernel/sched.c 包含了内核调度器及相关系统调用的实现。调度的核心函数为 sched.c 中的 schedule() , schedule 函数封装了内核调度的框架。细节实现上调用具体的调度算法类中的函数实现,如 kernel/sched_fair.c 或 kernel/sched_rt.c 中的实现。
在CFS中,当产生时钟tick中断时,sched.c中scheduler_tick()函数会被时钟中断(定时器timer的代码)直接调用,我们调用它则是在禁用中断时。注意在fork的代码中,当修改父进程的时间片时,也会导致sched_tick的调用。sched_tick函数首先更新调度信息,然后调整当前进程在红黑树中的位置。调整完成后如果发现当前进程不再是最左边的叶子,就标记need_resched标志,中断返回时就会调用scheduler()完成进程切换,否则当前进程继续占用CPU。注意这与以前的调度器不同,以前是tick中断导致时间片递减,当时间片被用完时才触发优先级调整并重新调度。sched_tick函数的代码如下:
void scheduler_tick(void) { int cpu = smp_processor_id(); struct rq *rq = cpu_rq(cpu); struct task_struct *curr = rq->curr; sched_clock_tick(); spin_lock(&rq->lock); update_rq_clock(rq); update_cpu_load(rq); curr->sched_class->task_tick(rq, curr, 0); spin_unlock(&rq->lock); perf_event_task_tick(curr, cpu); #ifdef CONFIG_SMP rq->idle_at_tick = idle_cpu(cpu); trigger_load_balance(rq, cpu); #endif }
它先获取目前CPU上的运行队列中的当前运行进程,更新runqueue级变量clock,然后通过sched_class中的接口名task_tick,调用CFS的tick处理函数task_tick_fair(),以处理时钟中断。我们看kernel/sched_fair.c中的CFS算法实现。
具体的调度类如下:
static const struct sched_class fair_sched_class = { .next = &idle_sched_class, .enqueue_task = enqueue_task_fair, .dequeue_task = dequeue_task_fair, .yield_task = yield_task_fair, .check_preempt_curr = check_preempt_wakeup, .pick_next_task = pick_next_task_fair, .put_prev_task = put_prev_task_fair, #ifdef CONFIG_SMP .select_task_rq = select_task_rq_fair, .load_balance = load_balance_fair, .move_one_task = move_one_task_fair, .rq_online = rq_online_fair, .rq_offline = rq_offline_fair, .task_waking = task_waking_fair, #endif .set_curr_task = set_curr_task_fair, .task_tick = task_tick_fair, .task_fork = task_fork_fair, .prio_changed = prio_changed_fair, .switched_to = switched_to_fair, .get_rr_interval = get_rr_interval_fair, #ifdef CONFIG_FAIR_GROUP_SCHED .task_move_group = task_move_group_fair, #endif };
task_tick_fair函数用于轮询调度类的中一个进程。实现如下:
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued) { struct cfs_rq *cfs_rq; struct sched_entity *se = &curr->se; for_each_sched_entity(se) { /* 考虑了组调度 */ cfs_rq = cfs_rq_of(se); entity_tick(cfs_rq, se, queued); } }
该函数获取各层的调度实体,对每个调度实体获取CFS运行队列,调用entity_tick进程进行处理。kernel/sched_fair.c中的函数entity_tick源代码如下:
static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued) { /* * Update run-time statistics of the ‘current‘. */ update_curr(cfs_rq); #ifdef CONFIG_SCHED_HRTICK /* * queued ticks are scheduled to match the slice, so don‘t bother * validating it and just reschedule. */ if (queued) { resched_task(rq_of(cfs_rq)->curr); return; } /* * don‘t let the period tick interfere with the hrtick preemption */ if (!sched_feat(DOUBLE_TICK) && hrtimer_active(&rq_of(cfs_rq)->hrtick_timer)) return; #endif if (cfs_rq->nr_running > 1 || !sched_feat(WAKEUP_PREEMPT)) check_preempt_tick(cfs_rq, curr); }
该函数用kernel/sched_fair.c:update_curr()更新当前进程的运行时统计信息,然后调用kernel/sched_fair.c:check_preempt_tick(),检测是否需要重新调度,用下一个进程来抢占当前进程。update_curr()实现记账功能,由系统定时器周期调用,实现如下:
static inline void __update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr, unsigned long delta_exec) { unsigned long delta_exec_weighted; schedstat_set(curr->exec_max, max((u64)delta_exec, curr->exec_max)); curr->sum_exec_runtime += delta_exec; /* 总运行时间更新 */ schedstat_add(cfs_rq, exec_clock, delta_exec); /* 更新cfs_rq的exec_clock */ /* 用优先级和delta_exec来计算weighted,以用于更新vruntime */ delta_exec_weighted = calc_delta_fair(delta_exec, curr);
操作系统(Operation System)从本质上说,并不是指我们平时看到的那些窗口、菜单、应用程序。那些只是天边的浮云。操作系统其实是隐藏后面,我们根本看不到的部分。操作系统一般来说,工作就是:进程管理、内存管理、文件管理、设备管理等等。操作系统中最核心的概念是进程, 进程也是并发程序设计中的一个最重要、 最基本的概念。进程是一个动态的过程, 即进程有生命周期, 它拥有资源, 是程序的执行过程, 其状态是变化的。所谓的调度器,就是进程管理的一部分。
Linux一开始的调度器是复杂度为O(n)的始调度算法, 这个算法的缺点是当内核中有很多任务时,调度器本身就耗费不少时间,所以,从linux2.5开始引入赫赫有名的O(1)调度器。然而,O(1)调度器又被另一个更优秀的调度器取代了,它就是CFS调度器Completely Fair Scheduler. 这个也是在2.6内核中引入的,具体为2.6.23,即从此版本开始,内核使用CFS作为它的默认调度器,O(1)调度器被抛弃了。但其实目前任何调度器算法都还无法满足所有应用的需要,CFS也有一些负面的测试报告。相信随着Linux的发展,还会有新的调度算法,我们拭目以待。
标签:bug 特殊 efi 也有 orm 产生 轮询 内存管理 lead
原文地址:https://www.cnblogs.com/cloudbai/p/8973180.html