标签:http 使用 ar strong 数据 sp on c html
http://tech.it168.com/a2011/0416/1178/000001178961_all.shtml
【IT168 资讯】万丈高楼拔地起,高楼的成败取决于是否有一个好的地基。而一个系统的成败则取决于架构设计的优劣。当外部事物让公司项目失败,好的架构可以避免或减少损失,反之,一个不好的系统架构设计可能会让公司的损失更大。如何去设计系统架构呢?有请某跨国公司数据库架构师赵振平给大家分享一下他的经验。

▲某跨国公司数据库架构师赵振平
架构最重要的就是围绕性能、成本、数据高可用性这三点,这三点是紧密相连,密不可分的,所以我们称之为数据库架构设计“铁三角”。这三个因素相互制约,相互影响,密不可分。

铁三角示意图

性能决定成本和高可用性

可用性取决于成本和性能
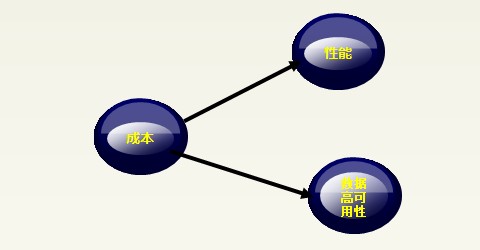
成本决定性能和可用性
数据库架构设计路线图
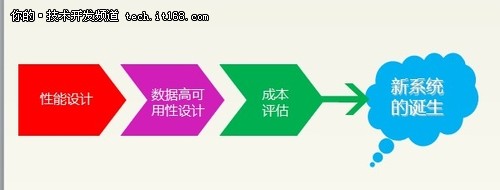
▲数据库架构设计路线图
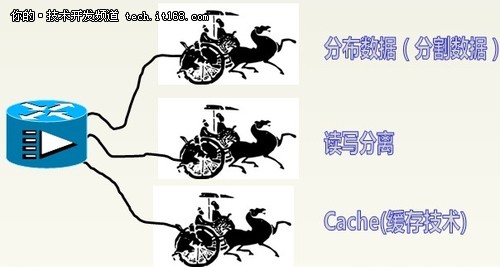
▲驱动性能的三驾马车
第一驾马车--分布数据
分布数据就是根据某些条件把数据分割分布成多块,然后放到不同的物理位置。所谓物理位置是指地理位置,物理主机和物理磁盘。分布数据目前来说是性能优化最有效的方法。分布数据的方法有一下几种:
1、按照国家进行划分
2、按照城市进行划分
3、按照数据中心(DC)进行划分
4、按照数据集合进行划分
垂直拆分(Vertical shard )
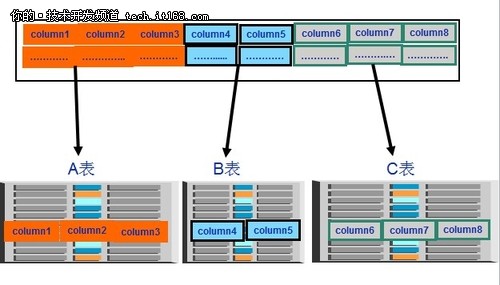
▲垂直拆分示意图
垂直拆分也叫行拆分(Row Splitting),其实就是把组成一行的多个列分开,放到不同的表中,这些表具有不同的结构,拆分后的每个表中含有更少的列。垂直拆分就是列的重新分布。垂直拆分其实就是“业务拆分”。
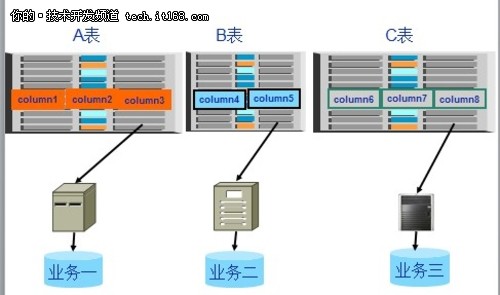
▲垂直拆分示意图
垂直拆分完成以后形成的架构:1、一个业务对应一台数据库;2、其实,这就是垂直拆分(Vertical shard )。
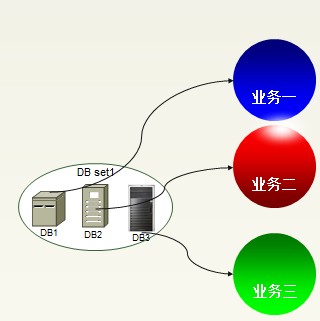
垂直拆分完成以后形成的架构
当“业务二”成为了焦点和热点,就必须对数据库进行水平拆分,什么是水平拆分?水平拆分其实就是把一个表分成几个表,这些表具有相同的列,但是存放更少的数据。其原理是根据现有的表克隆出新的表,这些表存放不同的数据而已。其具有以下特点:
1、每一块的结构完全相同
2、每一块的表结构和原来的“业务二”数据库的表结构完全相同
3、唯一不同的是,每一块中存放不同用户的数据
4、每一块在结构上其实就是原来数据库的克隆(clone)
5、每一块其实就是一个完整的数据库
假设经过一段时间的发展后,业务二业绩突出,目前的数据库无法满足业务二的需求,又需要对业务二数据库进行拆分。
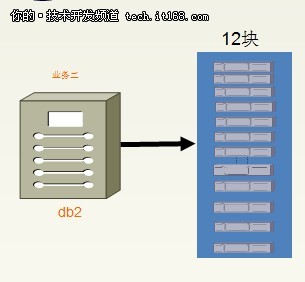
▲“业务二”数据库的拆分
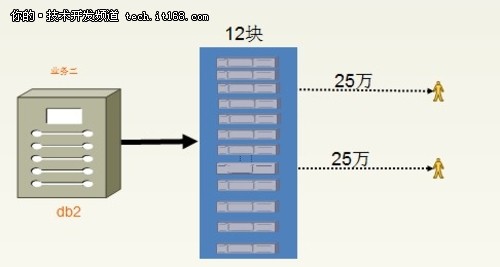
▲用户分布的变化

“业务二”数据库的拆分
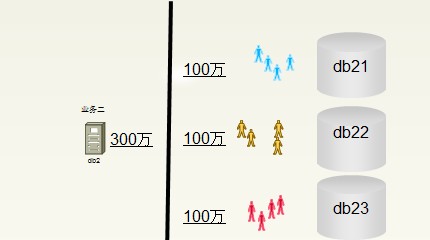
拆分之后用户的变化
其实以上就是水平拆分(Horizontal shard )。所谓水平拆分其实就是把一个表分成几个表,这些表具有相同的列,但是存放更少的数据。其原理是根据现有的表克隆出新的表,这些表存放不同的数据而已。水平拆分完成后,表S被拆分成三个表,这些表具有相同的结构。只是这三个表存放不同的数据。
第二驾马车:“读写分离”
数据拆分后,DB set1一套数据库由5台数据库组成,对于每台这样的数据库,仍然没有达到性能最优,那就要对db22实现读写分离。MySQL代理是一个介于MySQL客户端和MySQL服务器之间的简单程序,可用来监视、分析或者传输他们之间的通讯。最大优点就是:读写分离。

▲对db22实现读写分离

▲读写分离前的数据库

▲读写分离后的数据库
第三驾马车:“Cache(缓存技术)”
当上述分离后的业务三又发生了变化,其性能已经达到了瓶颈,利用拆分技术已经不能突破目前的局限,那么就只能考虑Cache(缓存技术)。
Memcached的应用
在使用Memcached技术的时候要注意两大影响:
查询影响:查询之前,要在Memcached中查找结果.如果找到,则返回它;如果未找到,则到数据库服务器上执行查询,并将结果返回给Memcached
插入影响:先把数据插入到数据库,在内存中受此影响的数据库将变成无效
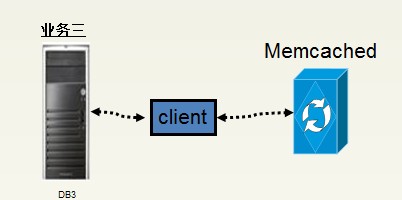
使用Memcached技术示意图
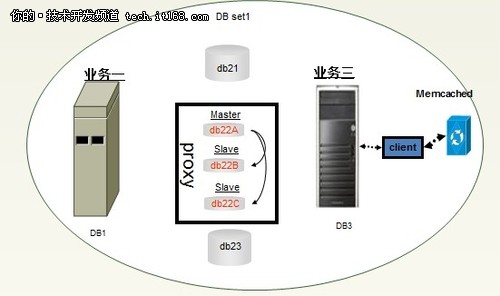
▲Memcached应用后的数据库
除了Memcached之外,当然其他的缓存技术也可以实现同样的效果。比如SolidDB和Oracle timesten等都可以实现这一效果。
标签:http 使用 ar strong 数据 sp on c html
原文地址:http://www.cnblogs.com/DjangoBlog/p/3992506.html