标签:学习笔记
文件操作返回一个文件对象(流对象)和文件描述符。打开文件失败,则返回异常
f = open("test")
print(f.read())
f.close()使用完一定要关闭
| 参数 | 描述 |
|---|---|
| r | 缺省的,表示只读打开,如果调用write,会抛异常。如果文件不存在,抛出FileNotFoundError异常 |
| w | 只写打开,如果文件不存在,则直接创建文件,如果文件存在,则清空文件内容 |
| x | 创建并写入一个新文件,如果文件存在,抛出FileExistsError异常 |
| a | 写入打开,如果文件存在,则追加 |
| b | 二进制模式,与字符编码无关,字节操作使用bytes类型 |
| t | 缺省的,文本模式,将文件的字节按照某种字符编码理解,按照字符操作 |
| + | 读写打开一个文件。给原来只读、只写方式打开提供缺失的读或者写能力,不能单独使用。获取文件对象依旧按照r、w、a、x的特征 |
r只读,wxa只写
wxa都可以产生新文件
文本模式下
二进制模式支持任意起点的偏移,从头、从尾、从中间位置开始。
向后seek可以超界,但是向前seek的时候,不能超界,否则抛异常
flush()
encoding:
errors
newline
readline(size=-1)
由解释器释放对象
from io import StringIO当调用close后,buffer会被释放
getvalue()
from io import BytesIOfrom pathlib import Pathfrom pathlib import Path
p3 = Path.cwd()
p3.partsoutput: (‘/‘, ‘data‘, ‘MyPythonObject‘)
with_name(name) 替换目录最后一个部分并返回一个新的路径
home() 返回当前家目录
is_absolute() 是否绝对路径
absolute() 返回绝对路径,建议使用resolve
as_uri() 将路径返回成URI,例如"file:///etc/passwd"
mkdir(mode=0o777,parents=False,exist_ok=False)
iterdir() 迭代当前目录
glob() 通配给定的模式
rglob() 通配给定的模式,递归目录 返回一个生成器
match() 模式匹配,成功返回True
stat() 查看文件属性
open(mdoe=‘r‘,buffering=-1,encoding=None,errors=None,newline=None)
read_bytes()
read_text(encoding=None,errors=None)
Path.write_bytes(data)
os.name
os.uname()
sys.platform
os.listdir(‘0:/temp‘)
os.stat(path, *, dir_fd=None, follow_symlinks=True)
os.chmod(path, mode, *, dir_fd=None, follow_symlinks=True)
copyfileobj(fsrc, fdst[, length])
copyfile(src, dst, *, follow_symlinks=True)
copymode(src, dst, *, follow_symlinks=True)
copystat(src, dst, *, follow_symlinks=True)
copy(src, dst, *, follow_symlinks=True)
copy2(src, dst, *, follow_symlinks=True)
copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False)
rmtree(path, ignore_errors=False, onerror=None)
csv不指定字符编码
如果字段中含有双引号、逗号、换行符,必须使用双引号括起来。
如果字段本身包含双引号,使用两个双引号表示一个转义
reader(csvfile, dialect=‘excel‘, **fmtparams)
fmtparams可设置
quotechar 字段引用符号,默认双引号
[DEFAULT]
a = test
[mysql]
default-character-set=utf8
a = 1000
[mysqld]
datadir =/dbserver/data
port = 33060
character-set-server=utf8
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES缺省section DEFAULT必须大写
from configparser import ConfigParser
cfg = ConfigParser()可将section当作key,其对应的值是存储着option的键值对字典,即ini文件是一个嵌套字典。默认使用有序字典
read(filenames, encoding=None)
sections()
add_section(section_name)
has_section(section_name)
options(section)
has_option(section)
get(section, option, *, raw=False, vars=None[, fallback])
getboolean(section, option, *, raw=False, vars=None[, fallback])
items(raw=False, vars=None)
items(section, raw=False, vars=None)
set(section, option, value)
remove_section(section)
remove_option(section, option)
serialization 序列化
deserialization 反序列化
dump(obj, protocol=None, *, fix_imports=True)
dump(obj, file, protocol=None, *, fix_imports=True)
loads(file, *, fix_imports=True, encoding="ASCII", errors="strict")
JavaScript Object Notation
值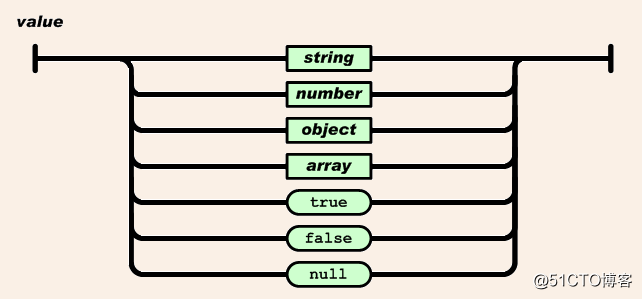
字符串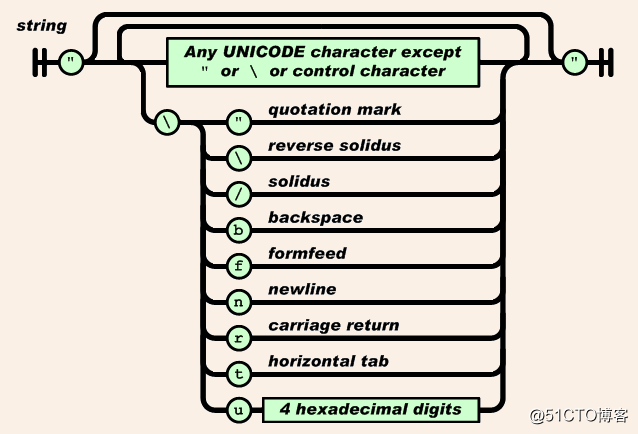
数值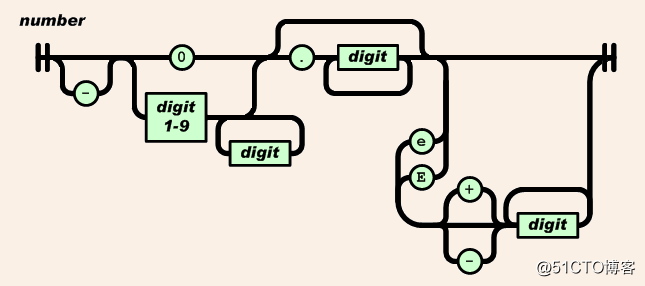
对象
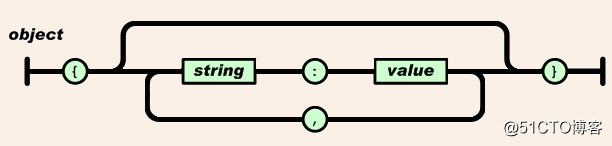

import jsondumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
import msgpackpackb(o, **kwargs) <=> dumps
unpackb(packed, object_hook=None, list_hook=None, bool use_list=1, encoding=None, unicode_errors=‘strict‘, object_pairs_hook=None, ext_hook=ExtType, Py_ssize_t max_str_len=2147483647, Py_ssize_t max_bin_len=2147483647, Py_ssize_t max_array_len=2147483647, Py_ssize_t max_map_len=2147483647, Py_ssize_t max_ext_len=2147483647) <==> loads
pack(o, stream, **kwargs) <==> dump
标签:学习笔记
原文地址:http://blog.51cto.com/11281400/2109233