标签:源码 bsp 特定 order 运行时间 process efi pid 复制
本文主要基于Linux0.01源代码分析进程模型。Linux 0.01虽然是Linux的第一个发行版本,但是却基本具备了操作系统中最重要的组成部分,同时Linux 0.01只有8500行左右的代码,对于初学者而言学习起来比较简单一点。
Linux 0.01源代码下载地址:
https://mirrors.edge.kernel.org/pub/linux/kernel/Historic/
进程是程序执行的基本单位。(其中,进程和程序的区别:程序指的是由若干函数组成的可执行文件,而进程指的是特定程序的一个实例)进程是对硬件所提供的资源进行操作的基本单元,也是顺序执行其实例化程序的基本单位。操作系统根据进程的需要管理和使用系统资源。在一定程度上,进程是由它要执行的一组指令、寄存器的内容和程序执行时程序计数器以及它们的状态定义的。
从系统内核角度看,一个进程仅仅是进程控制表(process table)中的一项。进程控制表中的每一项都是一个 task_struct 结构,task_struct结构定义于 linux/sched.h 。
进程控制表既是一个数组,又是一个双向链表,同时又是一棵树。其物理实现是一个包括多个指针的静态数组。
系统启动后,内核通常作为某个进程的代表。一个指向task_struct的全局指针变量 current 用来记录正在运行的进程。变量current只能由 kernel/sched.c 中的进程调度改变。
//task_struct //任务(进程)数据结构,或称为进程描述符。 struct task_struct { /* these are hardcoded - don‘t touch */ long state; //任务的运行状态/* -1 unrunnable, 0 runnable, >0 stopped */ long counter; //任务运行时间计数(递减)(滴答数),运行时间片。 long priority; //运行优先数。任务开始运行时counter = priority,越大运行越长。 long signal; //信号,每个比特位代表一种信号,信号值=位偏移值+1 struct sigaction sigaction[32]; long blocked; /* bitmap of masked signals */ /* various fields */ int exit_code; //任务执行停止时的退出码 unsigned long start_code, end_code, end_data, brk, start_stack; long pid; //进程标识号(进程号) long father; //父进程号 long pgrp; //父进程组号 long session; //会话号 long leader; unsigned short uid; //用户标识号(用户id) unsigned short euid; //有效用户id unsigned short suid; //保存的用户id unsigned short gid; //组标识号(组id) unsigned short egid; //有效组id unsigned short sgid; //保存的组id long alarm; long utime, stime, cutime, cstime, start_time; unsigned short used_math; /* file system info */ int tty; /* -1 if no tty, so it must be signed */ unsigned short umask; struct m_inode *pwd; //当前工作目录i节点结构 struct m_inode *root; //根目录i 节点结构 struct m_inode *executable; unsigned long close_on_exec;//执行时关闭文件句柄位图标志 struct file *filp[NR_OPEN]; /* ldt for this task 0 - zero 1 - cs 2 - ds&ss */ struct desc_struct ldt[3]; /* tss for this task */ struct tss_struct tss; };
在Linux 0.01内核中的include/linux/sched.h文件中,定义了进程的不同状态,如下所示:
// include/linux/sched.h这里定义了进程运行可能处的状态。 #define TASK_RUNNING 0 // 进程正在运行或已准备就绪。 #define TASK_INTERRUPTIBLE 1 // 进程处于可中断等待状态。 #define TASK_UNINTERRUPTIBLE 2 // 进程处于不可中断等待状态,主要用于I/O 操作等待。 #define TASK_ZOMBIE 3 // 进程处于僵死状态,已经停止运行,但父进程还没发信号。 #define TASK_STOPPED 4 // 进程已停止。
| 进程 | 功能 |
| TASK_RUNNING | 表示进程在“Ready List”中,这个进程除了CPU以外,获得了所有的其他资源 |
| TASK_INTERRUPTIBLE | 进程在睡眠,正在等待一个信号或一个资源(Sleeping) |
| TASK_UNINTERRUPTIBLE | 进程等待一个资源,当前进程在“Wait Queue” |
| TASK_ZOMBIE | 僵尸进程(没有父进程的子进程) |
| TASK_STOPPED | 标识进程在被调试 |
Linux系统使用系统调用 fork() 来创建一个进程,使用 exit() 来结束进程。 fork() 和 exit() 的源程序保存在 kernel/fork.c 和 kernel/exit.c 中。
fork()的主要任务是初始化要创建进程的数据结构,其步骤如下:
1.申请一个空闲的页面来保存task_struct
2.查找一个空的进程槽(find_empty_process())
3.为kernel_stack_page申请另一个空闲的内存页作为堆栈
4.将父进程的LDT表复制给子进程
5.复制父进程的内存映射信息
6.管理文件描述符合链接点
fork.c
/* * ‘fork.c‘ contains the help-routines for the ‘fork‘ system call * (see also system_call.s), and some misc functions (‘verify_area‘). * Fork is rather simple, once you get the hang of it, but the memory * management can be a bitch. See ‘mm/mm.c‘: ‘copy_page_tables()‘ */ #include <errno.h> #include <linux/sched.h> #include <linux/kernel.h> #include <asm/segment.h> #include <asm/system.h> extern void write_verify(unsigned long address); long last_pid=0; void verify_area(void * addr,int size) { unsigned long start; start = (unsigned long) addr; size += start & 0xfff; start &= 0xfffff000; start += get_base(current->ldt[2]); //current->ldt[2]指向数据段 while (size>0) { size -= 4096; write_verify(start); //在memory.c中定义 start += 4096; } } int copy_mem(int nr,struct task_struct * p) { unsigned long old_data_base,new_data_base,data_limit; unsigned long old_code_base,new_code_base,code_limit; code_limit=get_limit(0x0f); //0X0F=代码段选择器,8M data_limit=get_limit(0x17); //0x17=数据段选择器,8m old_code_base = get_base(current->ldt[1]); old_data_base = get_base(current->ldt[2]); if (old_data_base != old_code_base) panic("We don‘t support separate I&D"); if (data_limit < code_limit) panic("Bad data_limit"); new_data_base = new_code_base = nr * 0x4000000; //0x4000000=64M set_base(p->ldt[1],new_code_base); //重新设置本任务的LDT描述符 set_base(p->ldt[2],new_data_base); if (copy_page_tables(old_data_base,new_data_base,data_limit)) { free_page_tables(new_data_base,data_limit); //如果不能copy_page_tables,那么恢复以前的状态 return -ENOMEM; } return 0; } /* * Ok, this is the main fork-routine. It copies the system process * information (task[nr]) and sets up the necessary registers. It * also copies the data segment in it‘s entirety. */ int copy_process(int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss) { struct task_struct *p; int i; struct file *f; p = (struct task_struct *) get_free_page(); if (!p) return -EAGAIN; *p = *current; /* NOTE! this doesn‘t copy the supervisor stack */ p->state = TASK_RUNNING; p->pid = last_pid; p->father = current->pid; p->counter = p->priority; p->signal = 0; p->alarm = 0; p->leader = 0; /* process leadership doesn‘t inherit */ p->utime = p->stime = 0; p->cutime = p->cstime = 0; p->start_time = jiffies; p->tss.back_link = 0; p->tss.esp0 = PAGE_SIZE + (long) p; p->tss.ss0 = 0x10; p->tss.eip = eip; p->tss.eflags = eflags; p->tss.eax = 0; p->tss.ecx = ecx; p->tss.edx = edx; p->tss.ebx = ebx; p->tss.esp = esp; p->tss.ebp = ebp; p->tss.esi = esi; p->tss.edi = edi; p->tss.es = es & 0xffff; p->tss.cs = cs & 0xffff; p->tss.ss = ss & 0xffff; p->tss.ds = ds & 0xffff; p->tss.fs = fs & 0xffff; p->tss.gs = gs & 0xffff; p->tss.ldt = _LDT(nr); p->tss.trace_bitmap = 0x80000000; //0X80000000=2048M if (last_task_used_math == current) __asm__("fnsave %0"::"m" (p->tss.i387)); //保存浮点参数 if (copy_mem(nr,p)) { //为此任务设置LDT,并且拷贝父进程的页表作为自己的页表 free_page((long) p); return -EAGAIN; } for (i=0; i<NR_OPEN;i++) if (f=p->filp[i]) //系统init_task设置filp[NR_OPEN]为空 f->f_count++; if (current->pwd) //系统init_task设置PWD为空 current->pwd->i_count++; if (current->root) current->root->i_count++; //下面二行是在GDT中安装本任务的TSS和LDT set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss)); //gdt+(nr<<1)是因为每个任务在GDT中占两个单位 set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt)); task[nr] = p; /* do this last, just in case */ //将此任务登记入任务组 return last_pid; } int find_empty_process(void) //在初始化过的64个任务中寻找最近的一个空任务 { int i; repeat: if ((++last_pid)<0) last_pid=1; for(i=0 ; i<NR_TASKS ; i++) if (task[i] && task[i]->pid == last_pid) goto repeat; for(i=1 ; i<NR_TASKS ; i++) if (!task[i]) return i; return -EAGAIN; }
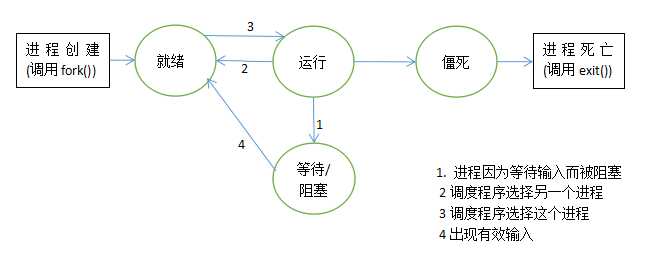
进程的调度( schedule() 函数)
处于TASK_RUNNING状态的进程一道运行队列(run queue),将schedule()函数按CPU调度算法在合适的时候被选中运行,分配给CPU。
新创建的进程都是处于TASK_RUNNING装填,而且被挂到run queue的对手。进程调度采用变形的轮转法(round robin)。当时间片到时(10ms的整数倍),由时钟中断引起新一轮调度,把当前进程挂到run queue队尾。
调度程序的一个重要工作就是选择系统所有可运行的进程中最适合运行的进程加以运行。一个可运行的进程是一个只等待CPU的进程。Linux使用合理而简单的基于优先级的调度算法在系统当前的进程中进行选择。当它选择了准备运行的新进程,它就保存当前进程的状态、与处理器相关的寄存器和其他需要保存的上下文信息到进程的task_struct数据结构中,然后恢复要运行的新进程的状态(和处理器相关),把系统的控制交给这个进程。为了公平地在系统中所有可以运行(runnable)的进程之间分配CPU时间,调度程序在每一个进程的task_struct结构中保留了信息。
1 void schedule(void) 2 { 3 int i,next,c; 4 struct task_struct ** p; 5 6 /* check alarm, wake up any interruptible tasks that have got a signal */ 7 8 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) 9 if (*p) { 10 if ((*p)->alarm && (*p)->alarm < jiffies) { 11 (*p)->signal |= (1<<(SIGALRM-1)); 12 (*p)->alarm = 0; 13 } 14 if ((*p)->signal && (*p)->state==TASK_INTERRUPTIBLE) 15 (*p)->state=TASK_RUNNING; 16 } 17 18 /* this is the scheduler proper: */ 19 20 while (1) { //此循环是取得任务的counter最高的那个任务,作为要切换的任务 21 c = -1; 22 next = 0; 23 i = NR_TASKS; 24 p = &task[NR_TASKS]; 25 while (--i) { 26 if (!*--p) 27 continue; 28 if ((*p)->state == TASK_RUNNING && (*p)->counter > c) 29 c = (*p)->counter, next = i; 30 } 31 if (c) break; //如果所有的任务counter都一样,且都为0,那么执行下面的代码,根据任务的先后顺序和权限大小重设各任务的counter 32 for(p = &LAST_TASK ; p > &FIRST_TASK ; --p) 33 if (*p) 34 (*p)->counter = ((*p)->counter >> 1) + 35 (*p)->priority; 36 } 37 switch_to(next); //切换任务 38 } 39 40 int sys_pause(void) //系统暂停 41 { 42 current->state = TASK_INTERRUPTIBLE; 43 schedule(); 44 return 0; 45 } 46 47 void sleep_on(struct task_struct **p) //进程休眠 48 { 49 struct task_struct *tmp; 50 51 if (!p) 52 return; 53 if (current == &(init_task.task)) //初始化任务不能休眠 54 panic("task[0] trying to sleep"); 55 tmp = *p; 56 *p = current; 57 current->state = TASK_UNINTERRUPTIBLE; 58 schedule(); 59 if (tmp) 60 tmp->state=0; //让**p的进程进入运行状态 61 } 62 63 void interruptible_sleep_on(struct task_struct **p) 64 { 65 struct task_struct *tmp; 66 67 if (!p) 68 return; 69 if (current == &(init_task.task)) 70 panic("task[0] trying to sleep"); 71 tmp=*p; 72 *p=current; 73 repeat: current->state = TASK_INTERRUPTIBLE; 74 schedule(); 75 if (*p && *p != current) { 76 (**p).state=0; //先唤醒其他的进程 77 goto repeat; 78 } 79 *p=NULL; 80 if (tmp) 81 tmp->state=0; //唤醒指定的进程 82 } 83 84 void wake_up(struct task_struct **p) 85 { 86 if (p && *p) { 87 (**p).state=0; 88 *p=NULL; 89 } 90 }
从Linux调度器的演变过程:从0.11-2.4版本的O(n)算法 -> 2.5版本的O(1) -> 现在的CFS算法再到未来。在Linux这个集全球众多程序员的聪明才智而不断发展更新的超级内核,总会不断出现新的可行性的措施,也会不断出现新的问题(如使得系统设计越来越复杂),但随着时代的变化,若干年后也许在硬件越来越先进的前提上,曾经不被看好的算法也许能发挥出色(如“返璞归真的Linux BFS调度器”)。
《Linux 0.01内核分析与操作系统设计--创造你自己的操作系统》(卢军编著)
《Linux内核编程》
标签:源码 bsp 特定 order 运行时间 process efi pid 复制
原文地址:https://www.cnblogs.com/yangbirong/p/8973247.html