标签:servlet 并且 iso byte int() 网上 character charset 开发
在网上看见一篇不错的文章,写的详细。
以下内容引用那篇博文。转载于《http://www.cnblogs.com/whgk/p/6412475.html》,在此仅供学习参考之用。
一、request请求参数出现的乱码问题
get请求:
get请求的参数是在url后面提交过来的,也就是在请求行中,
![]()
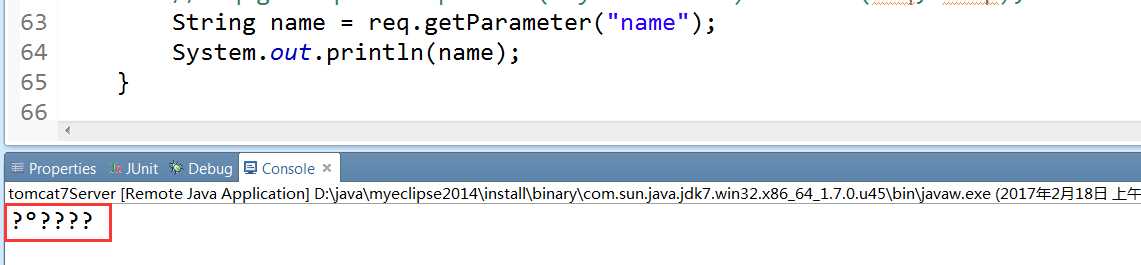
MyServlet是一个普通的Servlet,浏览器访问它时,使用get请求方式提交了一个name=小明的参数值,在doGet中获取该参数值,并且打印到控制台,发现出现乱码
出现乱码的原因:
前提知识:需要了解码表,编码,解码这三个名词的意思。我简单说一下常规的,
码表:是一种规则,用来让我们看得懂的语言转换为电脑能够认识的语言的一种规则,有很多中码表,IS0-8859-1,GBK,UTF-8,UTF-16等一系列码表,比如GBK,UTF-8,UTF-16都可以标识一个汉字,而如果要标识英文,就可以用IS0-8859-1等别的码表。
编码:将我们看得懂的语言转换为电脑能够认识的语言。这个过程就是编码的作用
解码:将电脑认识的语言转换为我们能看得懂得语言。这个过程就是解码的作用
这里只能够代表经过一次编码例子,有些程序中,会将一个汉字或者一个字母用不同的码表连续编码几次,那么第一次编码还是上面所说的作用,第二次编码的话,就是将电脑能够认识的语言转换为电脑能够认识的语言(转换规则不同),那么该解码过程,就必须要经过两次解码,也就是编码的逆过程,下面这个例子就很好的说明了这个问题。
浏览器使用的是UTF-8码表,通过http协议传输,http协议只支持IS0-8859-1,到了服务器,默认也是使用的是IS0-8859-1的码表,看图
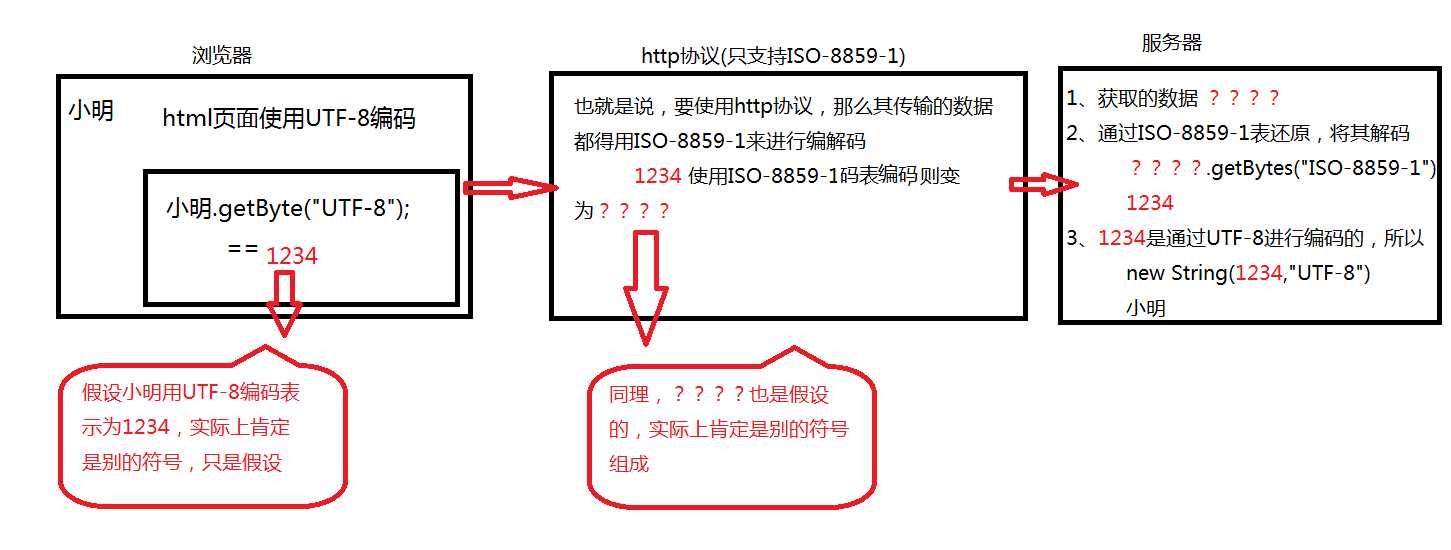
也就是三个过程,经历了两次编码,所以就需要进行两次解码,
1、浏览器将"小明"使用UTF-8码表进行编码(因为小明这个是汉字,所以使用能标识中文的码表,这也是我们可以在浏览器上可以手动设置的,如果使用了不能标识中文的码表,那么就将会出现乱码,因为码表中找不到中文对应的计算机符号,就可能会用??等其他符号表示),编码后得到的为 1234 ,将其通过http协议传输。
2、在http协议传输,只能用ISO-8859-1码表中所代表的符号,所以会将我们原先的1234再次进行一次编码,这次使用的是ISO-8859-1,得到的为 ???? ,然后传输到服务器
3、服务器获取到该数据是经过了两次编码后得到的数据,所以必须跟原先编码的过程逆过来解码,先是UTF-8编码,然后在ISO-8859-1编码,那么解码的过程,就必须是先ISO-8859-1解码,然后在用UTF-8解码,这样就能够得到正确的数据。????.getBytes("ISO-8859-1");//第一次解码,转换为电脑能够识别的语言, new String(1234,"UTF-8");//第二次解码,转换为我们认识的语言
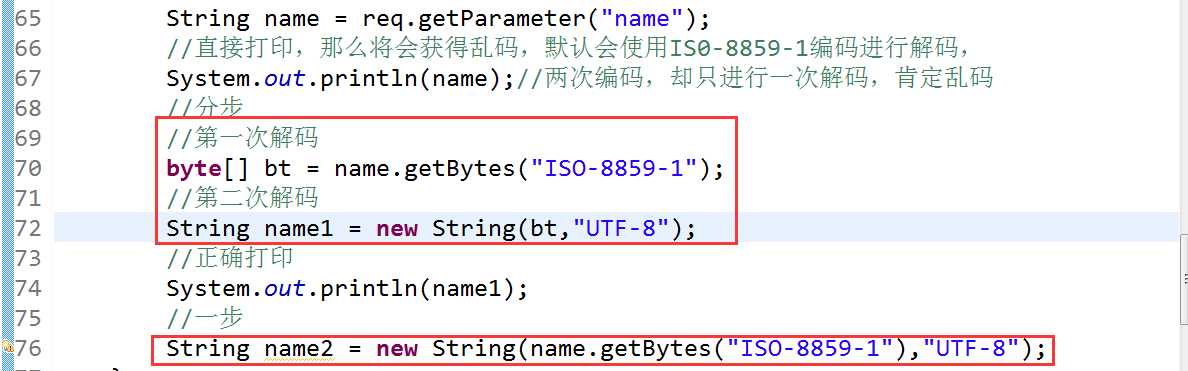
解决代码


Post请求:
post请求方式的参数是在请求体中,相对于get请求简单很多,没有经过http协议这一步的编码过程,所以只需要在服务器端,设置服务器解码的码表跟浏览器编码的码表是一样的就行了,在这里浏览器使用的是UTF-8码表编码,那么服务器端就设置解码所用码表也为UTF-8就OK了
设置服务器端使用UTF-8码表解码
request.setCharacterEncoding("UTF-8"); //命令Tomcat使用UTF-8码表解码,而不用默认的ISO-8859-1了。
所以在很多时候,在doPost方法的第一句,就是这句代码,防止获取请求参数时乱码。
总结请求参数乱码问题
get请求和post请求方式的中文乱码问题处理方式不同
get:请求参数在请求行中,涉及了http协议,手动解决乱码问题,知道出现乱码的根本原因,对症下药,其原理就是进行两次编码,两次解码的过程
new String(xxx.getBytes("ISO-8859-1"),"UTF-8");
post:请求参数在请求体中,使用servlet API解决乱码问题,其原理就是一次编码一次解码,命令tomcat使用特定的码表解码。
request.setCharaterEncoding("UTF-8");
二、response响应回浏览器出现的中文乱码。
首先介绍一下,response对象是如何向浏览器发送数据的。两种方法,一种getOutputStream,一种getWrite。
ServletOutputStream getOutputStream(); //获取输出字节流。提供write() 和 print() 两个输出方法
PrintWriter getWrite(); //获取输出字符流 提供write() 和 print()两个输出方法
print()方法底层都是使用write()方法的,相当于print()方法就是将write()方法进行了封装,使开发者更方便快捷的使用,想输出什么,就直接选择合适的print()方法,而不用考虑如何转换字节。
1、ServeltOutputStream getOutputStream();
不能直接输出中文,直接输出中文会报异常,
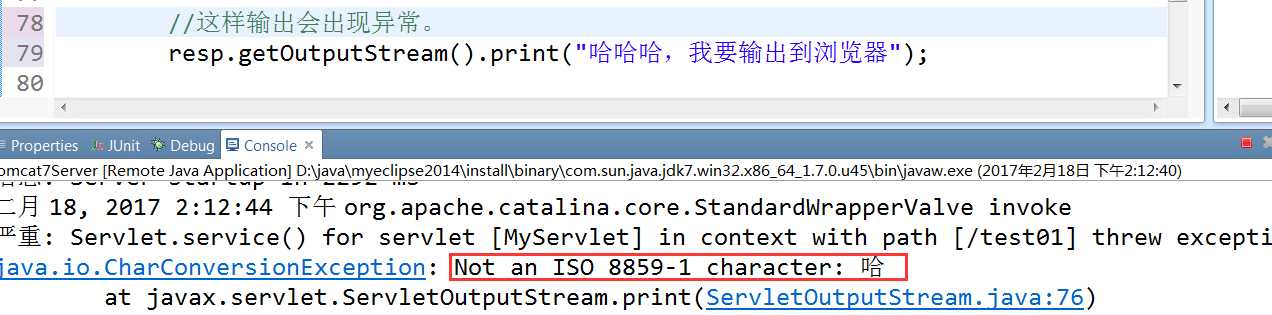
报异常的源代码
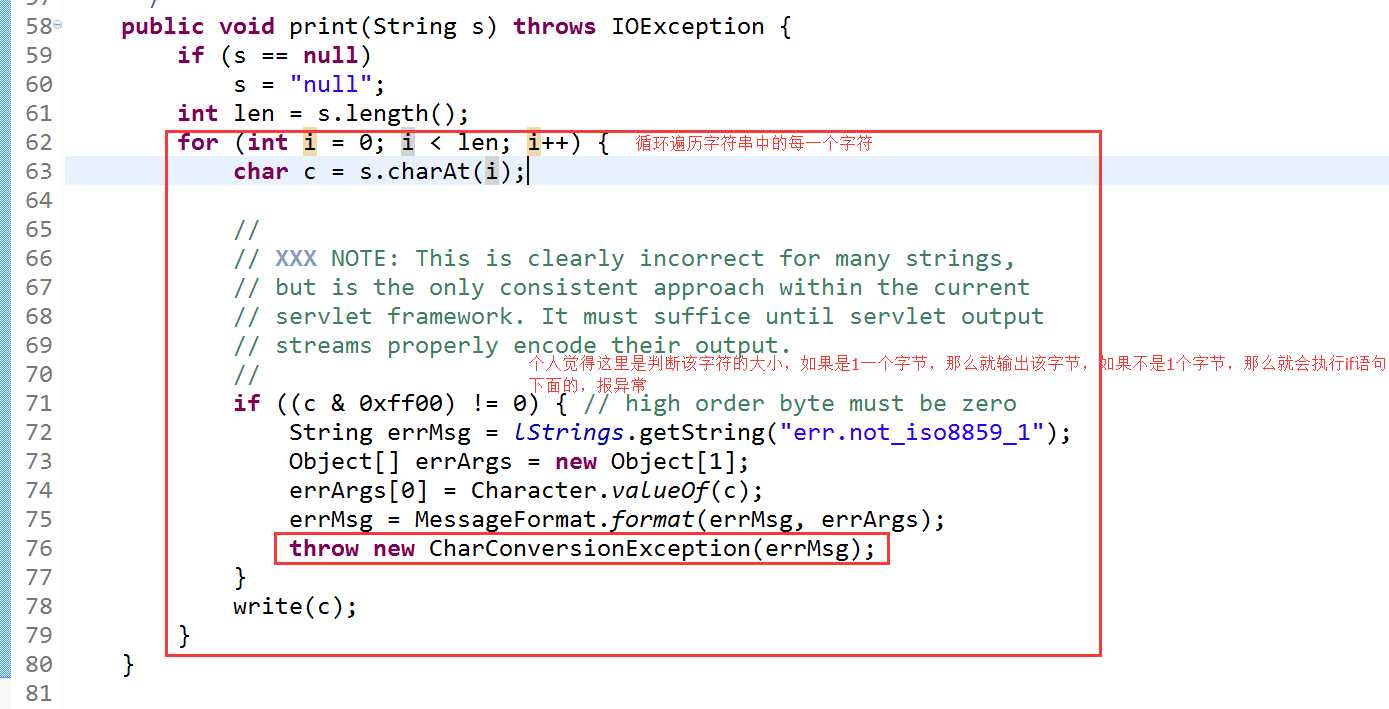
解决:
resp.getoutputStream().write("哈哈哈,我要输出到浏览器".getBytes("UTF-8"));
将要输出的汉字先用UTF-8进行编码,而不用让tomcat来进行编码,这样如果浏览器用的是UTF-8码表进行解码的话,那么就会正确输出,如果浏览器用的不是UTF-8,那么还是会出现乱码,所以说这个关键要看浏览器用的什么码表,这个就不太好,这里还要注意一点,就是使用的是write(byte)方法,因为print()方法没有输出byte类型的方法。
2、PrintWriter getWrite();
直接输出中文,不会报异常,但是肯定会报异常,因为用ISO-8859-1的码表不能标识中文,一开始就是错的,怎么解码编码读没用了
有三种方法来让其正确输出中文
1、使用Servlet API response.setCharacterEncoding()
response.setCharacterEncoding("UTF-8"); //让tomcat将我们要响应到浏览器的中文用UTF-8进行编码,而不使用默认的ISO-8859-1了,这个还是要取决于浏览器是不是用的UTF-8的码表,跟上面的一样有缺陷

2、通知tomcat和浏览器都使用同一张码表
response.setHeader("content-type","text/html;charset=uft-8"); //手动设置响应内容,通知tomcat和浏览器使用utf-8来进行编码和解码。
charset=uft-8就相当于response.setCharacterEncoding("UTF-8");//通知tomcat使用utf-8进行编码
response.setHeader("content-type","text/html;charset=uft-8");//合起来,就是既通知tomcat用utf-8编码,又通知浏览器用UTF-8进行解码。
response.setContentType("text/html;charset=uft-8"); //使用Servlet API 来通知tomcaat和强制浏览器使用UTF-8来进行编码解码,这个的底层代码就是上一行的代码,进行了简单的封装而已。
![]()
3、通知tomcat,在使用html<meta>通知浏览器 (html源码),注意:<meta>建议浏览器应该使用编码,不能强制要求
进行两步

所以response在响应时,只要通知tomcat和浏览器使用同一张码表,一般使用第二种方法,那么就可以解决响应的乱码问题了
三、总结
在上面讲解的时候总是看起来很繁琐,其实知道了其中的原理,很简单,现在来总结一下,
请求乱码
get请求:
经过了两次编码,所以就要两次解码
第一次解码:xxx.getBytes("ISO-8859-1");得到yyy
第二次解码:new String(yyy,"utf-8");
连续写:new String(xxx.getBytes("ISO-8859-1"),"UTF-8");
post请求:
只经过一次编码,所以也就只要一次解码,使用Servlet API request.setCharacterEncoding();
request.setCharacterEncoding("UTF-8"); //不一定解决,取决于浏览器是用什么码表来编码,浏览器用UTF-8,那么这里就写UTF-8。
响应乱码
getOutputStream();
使用该字节输出流,不能直接输出中文,会出异常,要想输出中文,解决方法如下
解决:getOutputStream().write(xxx.getBytes("UTF-8")); //手动将中文用UTF-8码表编码,变成字节传输,变成字节后,就不会报异常,并且tomcat也不会在编码,因为已经编码过了,所以到浏览器后,如果浏览器使用的是UTF-8码表解码,那么就不会出现中文乱码,反之则出现中文乱码,所以这个方法,不能完全保证中文不乱码
getWrite();
使用字符输出流,能直接输出中文,不会出异常,但是会出现乱码。能用三种方法解决,一直使用第二种方法
解决:通知tomcat和浏览器使用同一张码表。
response.setContentType("text/html;charset=utf-8"); //通知浏览器使用UTF-8解码
通知tomcat和浏览器使用UTF-8编码和解码。这个方法的底层原理是这句话:response.setHeader("contentType","text/html;charset=utf-8");
注意:getOutputStream()和getWrite() 这两个方法不能够同时使用,一次只能使用一个,否则报异常
web开发(二) Servlet中response、request乱码问题解决
标签:servlet 并且 iso byte int() 网上 character charset 开发
原文地址:https://www.cnblogs.com/hzb462606/p/8977438.html