标签:.com pos com 选择 扩展 辅助 范围 cal 信息
前面曾提到过CTPN,这里就学习一下,首先还是老套路,从论文学起吧。这里给出英文原文论文网址供大家阅读:https://arxiv.org/abs/1609.03605。
CTPN,以前一直认为缩写一般是从题目的开始依次排序选取首字母的,怕是孤陋寡闻了,全称是“ Detecting Text in Natural Image with Connectionist Text Proposal Network”,翻译过来是基于连接Proposal(直译太难受!!)网络的文本检测。
作者在论文中描述了,根据他们提出的方法可以对图片中的文本行进行准确的定位。他的基本做法是直接在卷积获得的feature map上生成的一系列适当尺寸的文本proposals进行文本行的检测。
本文的一个亮点是作者提出了一个垂直anchor的机制,可以同时预测出固定宽度proposal的位置以及文本/非文本的分数,可以大幅度提高精度。这里有个小问题,既然用到proposals,那他们是从哪里来的呢,
作者告诉我们这些有序的proposals是由RNN(循环神经网络)得到的,RNN可以很好的结合CNN,形成一个end-to-end的可训练模型。作者也很自觉的提到了,用RNN如此操作的好处是可以使CTPN探索丰富的图像上下文的信息,能够检测模糊的文本,貌似不赖啊。。。亮出CTPN的优点吧,据作者说,CTPN是可以在多尺度和多语言文本中进行检测的。而且比较方便的是,他并不需要后期的处理。
作者提出的垂直anchor可以以适当的规模准正确的预测文本的位置。然后,提出的网内循环结构,可以将较大尺寸的文本proposal有序的连接,这样做的好处是可以对上下文丰富的文本信息进行编码。
针对物体检测可以大致地认为。如果检测到边界框与groundtruth的重叠大于0.5,则可以从图片的主要部分很简单的认出物体。文本检测需要覆盖文本行或单词的整个区域。作者提到了文本检测的一个用的比较多的评估标准,就是Wolf标准。作者是通过扩展RPN的结构来准确的对文本行进行定位。
作者表态,他们的工作主要由四个部分:第一部分,作者将文本检测的问题转化为定位一系列合适尺寸的文本proposals的问题。个人感觉将问题分散化了(将复杂问题转为简单问题的思想值得借鉴)。因此,为了实现上述过程,作者提出了一个anchor回归机制,通过这个方式,可以同时预测出每个文本proposal的垂直方向的位置和文本/非文本的分数值,以便获得更好的定位。相比之下,RPN貌似提供的定位就差强人意了。。
接下来,大佬们又提出了一种in-network 循环机制,可以直接在CNN的feature map 上建立连续的文本proposals。这波操作看可以对文本行上下文的信息进行有意义的探索。第三,大佬又强调,上述两种方法可以很好的符合文本序列的本质,形成end-to-end的可训练模型。第四是一些大佬们取得的成绩,这里感兴趣的同学可以从论文里查看,这里就不赘述了。
传统的文本检测方法大体可以分为两类,一类为连接组件(CC),另一类为滑动窗口。CC是通过使用fast filter 对文本/非文本像素进行区分,然后通过使用(强度,颜色,渐变)等低级属性将文本像素分为笔画或者候选字符。而 滑动窗口是通过在图像上密集的移动多尺寸的窗口。字符/非字符窗口通过预训练的分类器,使用手动设计的特征或CNN靠后层的特征进行区分。当然,作者指明了上述两种方法的弊端,就是在接下来的组件filter和文本行的构建过程中,出现的错误会进行累积,最终会产生较大的误差。此外,很好的将非字符组件排除同时较准确的检测文本行是比较困难的。滑动窗口有一个比较大的问题,就是计算上比较费钱,因为需要在大量的窗口上运行分类器。
作者告诉我们在物体检测中,一种比较普遍的方式是通过一些低级特征产生一些proposals,然后送到卷积网络里进行进一步的分类和修改。其中,通过选择性搜索(SS)可以产生proposals,目前应用的比较广泛。在faster R-CNN中又有RPN,直接从CNNN的feature map中获得proposals。由于共享卷积,因此RPN的运算速度是比较快的。但是RPN是不具有区别性的,需要进一步的分类和修复。

重点来了,这里介绍CTPN的结构,这个网络的三个关键是:一是在fine-scale 的proposals中检测文本,二是循环连接的文本proposals,最后是辅助细化操作。接下来我们就按顺序看看作者们是如何实现的吧。
Detecting Text in Fine-scale Proposals
作者告诉我们CTPN与RPN相似的地方是,也是一个完整的卷积网络,也可以允许任意大小的图像的输入。前面也提到过了,CTPN通过在CNN的feature map 上密集的移动窗口来检测文本行,输出的是一系列的适当尺寸(固定宽度16像素,可以从上图右侧看出,长度还是可以调整的)的文本proposal。作者以VGG16进行说明,(为什么要选用VGG16原因是VGG16是由大规模数据训练得到的模型,我们日常生活中的数据相比训练VGG16的数据集要差好几个级别,所以,一般以VGG16进行迁移学习,进行微调)。作者使用大小为3*3的空间窗口,在最后一层卷积(VGG16的conv5)的feature map上滑动窗口。conv5的 feature map 的大小是由输入图像的大小决定的。而总步长和感受野分别为16和228个像素。他们都是有网络结构决定的固定的范围。这里有个隐含的问题那就是,前面提到过滑动窗口需要耗费大量的计算,但这里却又可以,为什么呢?原因是在卷积层中滑动窗口可以共享卷积,这样可以减少计算成本。采用不同尺寸的滑动窗口可以检测不同大小的物体。出色的是,Ren提出了anchor 回归机制允许RPN可以使用单尺度窗口检测多尺度的对象。这个想法的核心是通过使用一些灵活的anchors在大尺度和纵横比的范围内对物体进行预测。
这里作者进行了提示,就是文本检测不同于物体检测。文本检测没有一个明显封闭边界,同时是一个序列,可能在笔画,字符,单词,文本行和文本等多级组件之间没有明确的区分。因此,文本检测是定义在文本或文本行上的。

由上图可以看到RPN进行的单词检测很难准确的进行水平预测,是因为单词中的每个字符都是分离的,对文本的头和尾无法很好的区分。因此,作者认为将文本行视为一系列缩放文本proposals,每个proposal通常代表文本行的一小部分。作者又觉得,每次仅预测每个proposal垂直位置会更准确,因为水平的不好预测。。。由于RPN预测的是对象的四个坐标,从而减少了搜索空间。
作者们提出了一种垂直anchor的机制,可以同时预测每个proposal的文本/非文本分数和y轴的位置。检测固定宽度的文本proposal比检测单个或分离的字符更容易。为了让在一系列固定宽度的文本proposal上检测文本行也可以应对多个比例和纵横比的文本。作者们亲自 设计文本proposals。首先,detector密集的搜索conv5中的每个空间位置。文本Proposal具有16个像素的固定宽度是有意义的(密集的through conv5中的feature map)总步长恰好为16个像素。接下俩,又给每个proposal设计了k个垂直anchor用来预测每个点的y坐标。这k个anchor 具有固定16个像素的水平位置,但垂直位置在k个不同的高度上变化,这里作者使用的是10个anchors。高度在11-273个像素变化,垂直坐标是如何计算的呢,作者告诉我们是通过 一个proposal 边界框的高度和y轴的中心计算得到的。有关预测anchor边界框的相对的垂直坐标的计算是由下式得到,
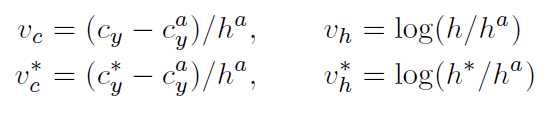
参数说明:V={Vc,Vh},V*={Vc*,Vh*}分别为预测的坐标和groundTruth。Cy 和Ha是anchor box的y轴的中心和高度,可以根据输入图像提前计算得到。因此,每个预测的文本proposal有一个大小为h*16的边界框(如上述右图),大体上,文本proposal相对于228*228的感受野来说小很多。
这里总结一下检测的处理过程,给定一张图片,这里由一个W*H*C 的conv5的feature map,detector通过一个大小为3*3的窗口密集的滑动conv5,每个滑动窗口用一个3*3*C的feature map用于进行预测。对每个预测来说,水平位置和k个anchors的位置是固定的,这个是由输入图像在conv5的feature map上窗口的位置预先计算得到的。detector 输出每个窗口位置处k个anchor的文本/非文本分数和预测的y的坐标。生成的文本proposals 是由文本/非文本分数值大于0.7(通过使用NMS)的anchor生成的。通过使用垂直anchor和fine-scale 策略,detector可以处理各种比例和纵横比的文本行,进一步节省了计算量和时间。
第一部分介绍完了,接下来就是 Reccurrent Connectionist Text Proposals
为了提高精度,作者将文本行分割为一个fine-scale的序列文本Proposal,并分别对他们中的每一个进行预测。为什么文本proposal要为序列,原因是将独立的proposal单独考虑并不周全,容易将图片中和文本类似的结构(作者举了个小栗子:砖块)预测为文本,这就造成了错误。同时也为了防止忽略含文本信息较少的情况。
有序和无序的比较如下图:

作者 提出这个结构想要达到的目标是直接在卷积层上编码上下文信息,形成一个紧密的网络内部连接。RNN使用可以使用隐藏层对信息进行循环编码。理所当然的,作者在conv5上设计了一个RNN层,将每个窗口的卷积特性作为连续输入,并在RNN的隐藏层H中循环更新其内部状态,公式如下:
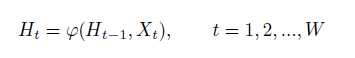
参数说明:其中Xt代表来自第t个滑动窗口的输入conv5的特征,滑动窗口是从左至右滑动,产生每行1....W的顺序features。W是conv5的宽度。Ht是由当前输入Xt与以前的状态Ht-1一起计算得到的当前内部状态。作者用LSTM作为RNN层。在CTPN中,作者使用双向LSTM进一步扩展RNN,允许其在两个方向上对上下文进行编码,使连接感受野能够覆盖图像的整个宽度。对每个LSTM用128D的隐藏层,双向的RNN就问256D,在Ht隐藏层的状态被映射到接下来的全连接层,输出层,用于计算第t个proposal的预测。由上图可以看出,作者们的付出还是得到回报的。
大部分已经介绍完了,然后就大体说一下Side-refinement吧。
据作者表示,借助于连接连续的文本proposal的文本/非文本分数大于0.7,文本行的构建非常easy。
文本行的建立过程:首先,介绍一个定义, 第一个条件是当Bj是离Bi水平距离最近的区域,第二个条件是该距离小于50个像素,第三个条件是垂直重叠要大于0.7,这样满足三个条件才可以将Bj定义为Bi的一个相邻域记作 Bj->Bi。概念问题解决后,作者强调,如果Bi->B j,Bj->Bi,则可以将两个proposal划为一对,这样通过顺序连接相同的propsoals可以构建文本行。精确的检测和RNN连接可以准确的预测垂直方向的位置。水平方向上,图像被分成一系列像素为16的等宽的proposal。当两个水平方向的proposal没有被ground truth的文本行覆盖时,会导致预测的位置不准确,
上述问题对物体检测影响不大,但在文本检测尤其是小文本的检测来说是不容忽视的。因此,side-refinement 就是为了解决此问题而提出的,这个方法可以准确估计左右两侧水平方向上每个anchor/proposal 的偏移量。偏移量的计算如下:
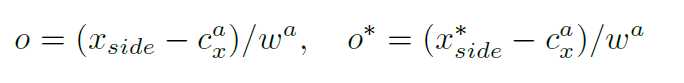
Xside为离当前anchor距离最近的水平边(左边或者右边)的坐标。X*side是水平方向GT坐标,由GT边界框和anchor的位置计算得到。Cx_a是水平方向anchor的中心。Wa是anchor的宽(固定为16)。当将一系列检测到的文本proposals连接成一个文本行时。side-proposal被定义为proposals的开头和结尾(终于明白side的由来了)。作者只使用side-proposal 的偏移量来重新定义左中的文本行的边界框。
论文的主要部分差不多了,接下来让我们看看这个CTPN的输出和他的损失函数吧。
CTPN的三个输出都被一起连接到全连接层上。这三个输出同时预测文本/非文本分数,垂直坐标和side-refinement的偏移量。采用k个anchor对他们三个分别预测,依次在输出层产生2k,2k,和k个参数。作者采用多任务学习来联合优化模型参数,目标函数如下:
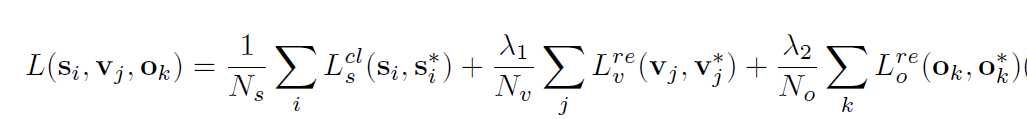
每一个anchor是一个训练样本。i是一个anchor在一个minibatch的序列。Si是anchor i 预测是一个真文本的概率,S*是GT{0,1},j是用于y坐标回归的有效anchor集合中的anchor的索引,他的定义是
一个有效的anchor被定义为positivate anchor S*j=1,或者是与GT的文本proposal 大于0.5的重叠。Vj和Vl*是第j个anchor的y轴方向的预测值和GT.k为side-anchor的标号,side-anchor为一系列离grount Truth文本行框从左至右在水平距离范围内(这里为32个像素)的anchors。Ok和Ok*是x轴上第K个anchor的预测的和GT的偏移量。Ls为区分文本/非文本的Softmax损失,Lv和Lo都为回归损失,其中lamda1,lamda2为损失权重,根据经验设置为1.0和2.0。
CTPN可以用标准的反向传播和随机梯度下降进行end-to-end的训练。与RPN相同的是训练样本为anchors,其位置可以由输入的图片预先计算,所以每个anchor训练的标签可以根据GTbox计算得到。
针对文本/非文本的分类,二进制的标签被分给每一个正anchor(文本)和负anchor(非文本),正负anchor是由IOU与GT边界重叠计算得到的。正的anchor被定义为:IOU与GTbox 的重叠大于0.7的或者最高(集是一个很小的文本pattern也会被分为一个正的anchor)的anchor。负的anchor是IOU小于0.5产生的。CTPN的理论大体讨论到这里,后面还有作者做的实验结果并进行了讨论,可以参考前面给出的论文地址进行进一步的学习。
CTPN: Detecting Text in Natural Image with Connectionist Text Proposal Network
标签:.com pos com 选择 扩展 辅助 范围 cal 信息
原文地址:https://www.cnblogs.com/fourmi/p/8973905.html