标签:roc 进程创建 likely 寄存器 备份 after sof 发展 security
进程是操作系统的资源分配和独立运行的基本单位。它一般由以下三个部分组成
进程创建时,操作系统就新建一个PCB结构,它之后就常驻内存,任一时刻可以存取, 在进程结束时删除。PCB是进程实体的一部分,是进程存在的唯一标志。
当创建一个进程时,系统为该进程建立一个PCB;当进程执行时,系统通过其PCB 了 解进程的现行状态信息,以便对其进行控制和管理;当进程结束时,系统收回其PCB,该进 程随之消亡。操作系统通过PCB表来管理和控制进程。
| 进程描述信息 | 进程控制和管理信息 | 资源分配清单 | 处理机相关信息 |
|---|---|---|---|
| 进程标识符(PID) | 进程当前状态 | 代码段指针 | 通用寄存器值 |
| 用户标识符(UID) | 进程优先级 | 数据段指针 | 地址寄存器值 |
| 代码运行入口地址 | 堆栈段指针 | 控制寄存器值 | |
| 程序的外存地址 | 文件描述符 | 标志寄存器值 | |
| 进入内存时间 | 键盘 | 状态字 | |
| 处理机占用时间 | 鼠标 | ||
| 信号量使用 |
该表是一个PCB的实例,PCB主要包括进程描述信息、进程控制和管理信息、资源 分配清单和处理机相关信息等。各部分的主要说明如下:
1) 进程描述信息
进程标识符:标志各个进程,每个进程都有一个并且是唯一的标识号。
用户标识符:进程归属的用户,用户标识符主要为共享和保护服务。
2) 进程控制和管理信息
进程当前状态:描述进程的状态信息,作为处理机分配调度的依据。
进程优先级:描述进程抢占处理机的优先级,优先级高的进程可以优先获得处理机。
3) 资源分配清单,用于说明有关内存地址空间或虚拟地址空间的状况;所打开文件的 列表和所使用的输入/输出设备信息。
4) 处理机相关信息,主要指处理机中各寄存器值,当进程被切换时,处理机状态信息 都必须保存在相应的PCB中,以便在该进程重新执行时,能再从断点继续执行。
在一个系统中,通常存在着许多进程,有的处于就绪状态,有的处于阻塞状态,而且阻塞的原因各不相同。为了方便进程的调度和管理,需要将各进程的PCB用适当的方法组织起来。目前,常用的组织方式有链接方式和索引方式两种。链接方式将同一状态的PCB链接成一个队列,不同状态对应不同的队列,也可以把处于阻塞状态的进程的PCB,根据其阻塞原因的不同,排成多个阻塞队列。索引方式是将同一状态的进程组织在一个索引表中,索引表的表项指向相应的PCB,不同状态对应不同的索引表,如就绪索引表和阻塞索引表等。
程序段就是能被进程调度程序调度到CPU执行的程序代码段。注意,程序可以被多个进程共享,就是说多个进程可以运行同一个程序。
一个进程的数据段,可以是进程对应的程序加工处理的原始数据,也可以是程序执行时产生的中间或最终结果。
/*task_struct 进程描述符*/ struct task_struct { /*进程的运行状态*/ volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ /*stack进程内核栈*/ /* * 进程通过alloc_thread_info()分配它的内核栈, * 通过free_thread_info()释放它的内核栈 * 两个函数定义在<asm/thread_info.h>中. * thread_info是进程的另一个内核数据结构,存放在进程内核栈的尾端. * thread_info内部的task域存放指向该任务实际的task_struct. * linux内核栈是由联合体thread_union表示的,定义在<linux/sched.h>中. */ void *stack; atomic_t usage; unsigned int flags; /* per process flags, defined below */ unsigned int ptrace; int lock_depth; /* BKL lock depth */ #ifdef CONFIG_SMP #ifdef __ARCH_WANT_UNLOCKED_CTXSW int oncpu; #endif #endif /* * 内核中规定,进程的优先级范围为[0,MAX_PRIO-1].其中分为实时进程部分: * [0,MAX_RT_PRIO-1]和非实时进程部分:[MAX_RT_PRIO,MAX_PRIO-1]. * 优先级值越小,意味着优先级别越高,任务先被内核调度. * prio 指任务当前的动态优先级,其值影响任务的调度顺序. * normal_prio指的是任务的常规优先级,该值基于static_prio和调度策略计算 * static_prio值得是任务的静态优先级,在进程创建时分配,该值会影响分配给 * 任务的时间片的长短和非实时任务动态优先级的计算. * rt_prioity指的是任务的实时优先级.0表示普通任务,[1,99]表示实时任务. * 值越大,优先级越高 * 对于实时进程:prio = normal_prio = static_prio * 对于普通进程:prio = normal_prio = MAX_RT_PRIO -1 -rt_priority * prio的值在使用实时互斥量时会暂时提升,释放后恢复成normal_prio */ int prio, static_prio, normal_prio; const struct sched_class *sched_class; /*sched_entity se 调度器实体 用来对进程运行时间做记账*/ struct sched_entity se; struct sched_rt_entity rt; #ifdef CONFIG_PREEMPT_NOTIFIERS /* list of struct preempt_notifier: */ struct hlist_head preempt_notifiers; #endif /* * fpu_counter contains the number of consecutive context switches * that the FPU is used. If this is over a threshold, the lazy fpu * saving becomes unlazy to save the trap. This is an unsigned char * so that after 256 times the counter wraps and the behavior turns * lazy again; this to deal with bursty apps that only use FPU for * a short time */ unsigned char fpu_counter; s8 oomkilladj; /* OOM kill score adjustment (bit shift). */ #ifdef CONFIG_BLK_DEV_IO_TRACE unsigned int btrace_seq; #endif /* * 调度策略 实时进程FIFO/RR or OTHER */ unsigned int policy; cpumask_t cpus_allowed; #ifdef CONFIG_PREEMPT_RCU int rcu_read_lock_nesting; int rcu_flipctr_idx; #endif /* #ifdef CONFIG_PREEMPT_RCU */ #if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT) struct sched_info sched_info; #endif struct list_head tasks; /* * ptrace_list/ptrace_children forms the list of my children * that were stolen by a ptracer. */ struct list_head ptrace_children; struct list_head ptrace_list; /* * mm域存放了进程使用的内存描述符,内核线程的此域值为NULL * active_mm域存放当前活动的内存描述符,内核线程把前一个活动进程的 * mm域值存入此域,并作为临时地址空间执行程序. */ struct mm_struct *mm, *active_mm; /* task state */ struct linux_binfmt *binfmt; /* * exit_state进程的退出状态 */ int exit_state; int exit_code, exit_signal; int pdeath_signal; /* The signal sent when the parent dies */ /* ??? */ unsigned int personality; unsigned did_exec:1; /* * pid进程标识符 */ pid_t pid; /* * tgid进程组标识符 * POSIX标准规定,一个多线程应用程序中的所有线程必须有相同的PID * 在linux中,一个线程组的所有线程使用与该组的领头线程pid相同的值 * 作为线程组id,并存入tgid域中. * 另:使用getpid()系统调用得到的是tgid而非pid */ pid_t tgid; #ifdef CONFIG_CC_STACKPROTECTOR /* Canary value for the -fstack-protector gcc feature */ unsigned long stack_canary; #endif /* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->parent->pid) */ /* * 实际的父进程,父进程,仅在调试时才区分二者 */ struct task_struct *real_parent; /* real parent process (when being debugged) */ struct task_struct *parent; /* parent process */ /* * children/sibling forms the list of my children plus the * tasks I‘m ptracing. */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent‘s children list */ struct task_struct *group_leader; /* threadgroup leader */ /* PID/PID hash table linkage. */ struct pid_link pids[PIDTYPE_MAX]; /* *线程链表 */ struct list_head thread_group; struct completion *vfork_done; /* for vfork() */ int __user *set_child_tid; /* CLONE_CHILD_SETTID */ int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */ unsigned int rt_priority; cputime_t utime, stime, utimescaled, stimescaled; cputime_t gtime; cputime_t prev_utime, prev_stime; unsigned long nvcsw, nivcsw; /* context switch counts */ /* * 进程创建时间 */ struct timespec start_time; /* monotonic time */ /* * 进程实际的创建时间,基于系统启动时间 */ struct timespec real_start_time; /* boot based time */ /* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */ /* * 累计进程的次缺页数min_flt和主缺页数maj_flt */ unsigned long min_flt, maj_flt; cputime_t it_prof_expires, it_virt_expires; unsigned long long it_sched_expires; struct list_head cpu_timers[3]; /* process credentials */ /* * uid/gid运行该进程的用户的用户标识符和组标识符 * euid/egid有效的uid/gid * fsuid/fsgid文件系统的uid/gid 通常与euid/egid相同 * 在检查进程对文件系统的访问权限时使用fsuid/fsgid * suid/sgid为备份uid/gid */ uid_t uid,euid,suid,fsuid; gid_t gid,egid,sgid,fsgid; struct group_info *group_info; kernel_cap_t cap_effective, cap_inheritable, cap_permitted, cap_bset; unsigned keep_capabilities:1; struct user_struct *user; #ifdef CONFIG_KEYS struct key *request_key_auth; /* assumed request_key authority */ struct key *thread_keyring; /* keyring private to this thread */ unsigned char jit_keyring; /* default keyring to attach requested keys to */ #endif char comm[TASK_COMM_LEN]; /* executable name excluding path - access with [gs]et_task_comm (which lock it with task_lock()) - initialized normally by flush_old_exec */ /* file system info */ int link_count, total_link_count; #ifdef CONFIG_SYSVIPC /* ipc stuff */ struct sysv_sem sysvsem; #endif #ifdef CONFIG_DETECT_SOFTLOCKUP /* hung task detection */ unsigned long last_switch_timestamp; unsigned long last_switch_count; #endif /* CPU-specific state of this task */ /* * 用来标识进程的存储状态,具体实现依赖于特定的CPU架构 * 保存内核使用的相关任务状态段内容 */ struct thread_struct thread; /* filesystem information */ /* * 文件系统信息 */ struct fs_struct *fs; /* open file information */ /* * 打开文件表 */ struct files_struct *files; /* namespaces */ struct nsproxy *nsproxy; /* signal handlers */ struct signal_struct *signal; struct sighand_struct *sighand; sigset_t blocked, real_blocked; sigset_t saved_sigmask; /* To be restored with TIF_RESTORE_SIGMASK */ struct sigpending pending; unsigned long sas_ss_sp; size_t sas_ss_size; int (*notifier)(void *priv); void *notifier_data; sigset_t *notifier_mask; #ifdef CONFIG_SECURITY void *security; #endif struct audit_context *audit_context; #ifdef CONFIG_AUDITSYSCALL uid_t loginuid; unsigned int sessionid; #endif seccomp_t seccomp; /* Thread group tracking */ u32 parent_exec_id; u32 self_exec_id; /* Protection of (de-)allocation: mm, files, fs, tty, keyrings */ spinlock_t alloc_lock; /* Protection of the PI data structures: */ spinlock_t pi_lock; #ifdef CONFIG_RT_MUTEXES /* PI waiters blocked on a rt_mutex held by this task */ struct plist_head pi_waiters; /* Deadlock detection and priority inheritance handling */ struct rt_mutex_waiter *pi_blocked_on; #endif #ifdef CONFIG_DEBUG_MUTEXES /* mutex deadlock detection */ struct mutex_waiter *blocked_on; #endif #ifdef CONFIG_TRACE_IRQFLAGS unsigned int irq_events; int hardirqs_enabled; unsigned long hardirq_enable_ip; unsigned int hardirq_enable_event; unsigned long hardirq_disable_ip; unsigned int hardirq_disable_event; int softirqs_enabled; unsigned long softirq_disable_ip; unsigned int softirq_disable_event; unsigned long softirq_enable_ip; unsigned int softirq_enable_event; int hardirq_context; int softirq_context; #endif #ifdef CONFIG_LOCKDEP # define MAX_LOCK_DEPTH 48UL u64 curr_chain_key; int lockdep_depth; struct held_lock held_locks[MAX_LOCK_DEPTH]; unsigned int lockdep_recursion; #endif /* journalling filesystem info */ void *journal_info; /* stacked block device info */ struct bio *bio_list, **bio_tail; /* VM state */ struct reclaim_state *reclaim_state; struct backing_dev_info *backing_dev_info; struct io_context *io_context; unsigned long ptrace_message; siginfo_t *last_siginfo; /* For ptrace use. */ #ifdef CONFIG_TASK_XACCT /* i/o counters(bytes read/written, #syscalls */ u64 rchar, wchar, syscr, syscw; #endif struct task_io_accounting ioac; #if defined(CONFIG_TASK_XACCT) u64 acct_rss_mem1; /* accumulated rss usage */ u64 acct_vm_mem1; /* accumulated virtual memory usage */ cputime_t acct_stimexpd;/* stime since last update */ #endif #ifdef CONFIG_NUMA struct mempolicy *mempolicy; short il_next; #endif #ifdef CONFIG_CPUSETS nodemask_t mems_allowed; int cpuset_mems_generation; int cpuset_mem_spread_rotor; #endif #ifdef CONFIG_CGROUPS /* Control Group info protected by css_set_lock */ struct css_set *cgroups; /* cg_list protected by css_set_lock and tsk->alloc_lock */ struct list_head cg_list; #endif #ifdef CONFIG_FUTEX struct robust_list_head __user *robust_list; #ifdef CONFIG_COMPAT struct compat_robust_list_head __user *compat_robust_list; #endif struct list_head pi_state_list; struct futex_pi_state *pi_state_cache; #endif atomic_t fs_excl; /* holding fs exclusive resources */ struct rcu_head rcu; /* * cache last used pipe for splice */ struct pipe_inode_info *splice_pipe; #ifdef CONFIG_TASK_DELAY_ACCT struct task_delay_info *delays; #endif #ifdef CONFIG_FAULT_INJECTION int make_it_fail; #endif struct prop_local_single dirties; #ifdef CONFIG_LATENCYTOP int latency_record_count; struct latency_record latency_record[LT_SAVECOUNT]; #endif }; /*********************************************************************/ /* * thread_info简介 * 这是一个相对于task_struct结构要小很多的一个结构, * 每个内核线程都有一个thread_info结构,当进程从用户态陷入内核后,可以由 * thread_info中的task域指针来找到进程的task_struct. */ /*********************************************************************/ struct thread_info { unsigned long flags; /* low level flags */ int preempt_count; /* 0 => preemptable, <0 => bug */ mm_segment_t addr_limit; /* address limit */ /* * 相应的主任务的task_struct */ struct task_struct *task; /* main task structure */ /* * 执行域, * default_exec_domain 默认的执行域,定义在<kernel/exec_domain.c>中 */ struct exec_domain *exec_domain; /* execution domain */ __u32 cpu; /* cpu */ __u32 cpu_domain; /* cpu domain */ /* * 保存的CPU上下文,其成员为一系列CPU寄存器 */ struct cpu_context_save cpu_context; /* cpu context */ __u32 syscall; /* syscall number */ __u8 used_cp[16]; /* thread used copro */ unsigned long tp_value; struct crunch_state crunchstate; union fp_state fpstate __attribute__((aligned(8))); union vfp_state vfpstate; struct restart_block restart_block; }; /*********************************************************************/ /* * thread_union简介 * 内核栈的数据结构表示.内核栈是向下生长的, * 内核线程描述符thread_info分配在内核栈栈底,由于内核栈空间比 * thread_info结构体大很多,因此这样安排可以有效防止内存重叠. * 出于效率考虑,内核让8KB的内核栈占据两个连续的页框并让第一个页框的起始地址 * 是2^13的倍数. */ /*********************************************************************/ union thread_union { struct thread_info thread_info; unsigned long stack[THREAD_SIZE/sizeof(long)]; }; /*********************************************************************/ /* * current_thread_info简介 * 下面这段代码是current_thread_info在ARM上的实现. * 由于内核栈起始地址是2^13的整数倍,因此在内核态, * 把当前SP&0x1fff得到的地址就是内核栈栈的基地址, * 即存放thread_info的地址. */ /*********************************************************************/ static inline struct thread_info *current_thread_info(void) { register unsigned long sp asm ("sp"); return (struct thread_info *)(sp & ~(THREAD_SIZE - 1)); }
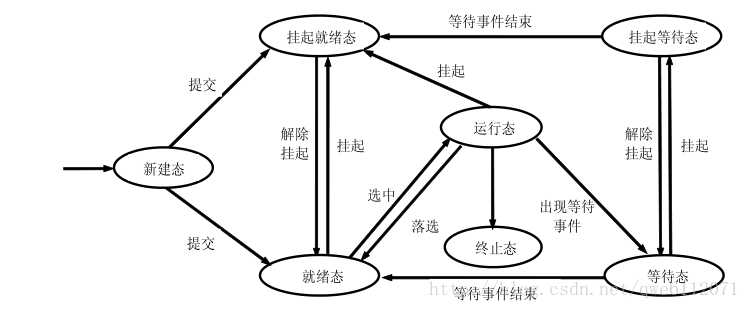
一个进程从创建而产生至撤销而消亡的整个生命周期,可以用一组状态加以刻划,根据三态模型,进程的生命周期可分为如下三种进程状态:
1. 运行态(running):占有处理器正在运行
2. 就绪态(ready):具备运行条件,等待系统分配处理器以便运行
3. 等待态(blocked):不具备运行条件,正在等待某个事件的完成
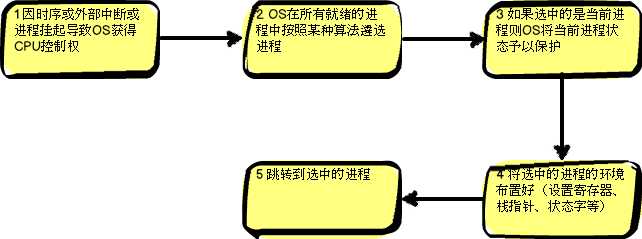
下图为进程转换图
进程调度是操作系统进程管理的一个重要组成部分,其任务是选择下一个要运行的进程
首先,一般的程序任务分为三种:CPU计算密集型、IO密集型与平衡(计算与IO各半)型,对于不同类型的程序,调度需要达到的目的也有所不同。对于IO密集型,响应时间最重要;对于CPU密集型,则周转时间最重要;而对于平衡型,进行某种响应和周转之间的平衡就显得比较重要。因此,进程调度的目标就是要达到极小化平均响应时间、极大化系统吞吐率、保持系统各个功能部件均处于繁忙状态和提供某种貌似公平的机制。
先来先服务(FCFS)算法是一种最常见的算法,它是人的本性中的一种公平观念。其优点就是简单且实现容易,缺点则是短的工作有可能变得很慢,因为其前面有很长的工作在执行,这样就会造成用户的交互式体验也比较差。
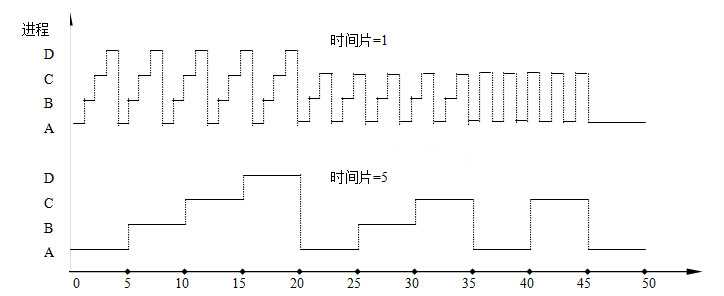
时间片轮转是对FCFS算法的一种改进,其主要目的是改善短程序的响应时间,实现方式就是周期性地进行进程切换。时间片轮转的重点在于时间片的选择,需要考虑多方因素:如果运行的进程多时,时间片就需要短一些;进程数量少时,时间片就可以适当长一些。因此,时间片的选择是一个综合的考虑,权衡各方利益,进行适当折中。
优先级调度算法给每个进程赋予一个优先级,每次需要进程切换时,找一个优先级最高的进程进行调度。这样如果赋予长进程一个高优先级,则该进程就不会再“饥饿”。事实上,短任务优先算法本身就是一种优先级调度,只不过它给予短进程更高的优先级而已。
该算法的优点在于可以赋予重要的进程以高优先级以确保重要任务能够得到CPU时间,其缺点则有二:一是低优先级的进程可能会“饥饿”,二是响应时间无法保证。第一个缺点可以通过动态地调节任务的优先级解决,例如一个进程如果等待时间过长,其优先级将因持续提升而超越其他进程的优先级,从而得到CPU时间。第二个缺点可以通过将一个进程优先级设置为最高来解决,但即使将优先级设置为最高,但如果每个人都将自己的进程优先级设置为最高,其响应时间还是无法保证。
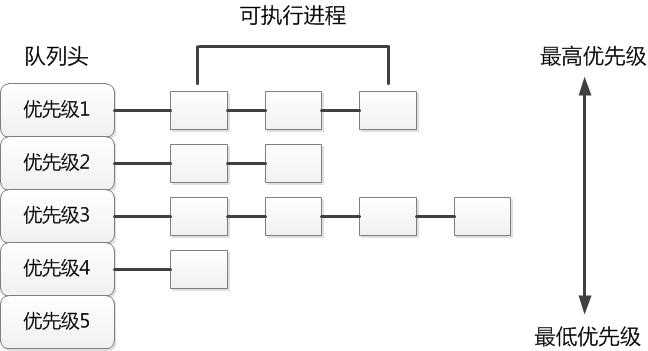
之前的算法都存在一定缺点,那么可否有一个算法混合他们的优点,摒弃它们的缺点,这就是所谓的混合调度算法。混合调度算法将所有进程分为不同的大类,每个大类为一个优先级。如果两个进程处于不同的大类,则处于高优先级大类的进程优先执行;如果处于同一个大类,则采用时间片轮转算法来执行。混合调度算法的示意图如下图所示:
CFS思路很简单,就是根据各个进程的权重分配运行时间。
进程的运行时间计算公式为:
分配给进程的运行时间 = 调度周期 * 进程权重 / 所有进程权重之和 (公式1)
vruntime = 实际运行时间 * 1024 / 进程权重 。 (公式2)
void wake_up_new_task(struct task_struct *p, unsigned long clone_flags) { ..... if (!p->sched_class->task_new || !current->se.on_rq) { activate_task(rq, p, 0); } else { /* * Let the scheduling class do new task startup * management (if any): */ p->sched_class->task_new(rq, p); inc_nr_running(rq); } check_preempt_curr(rq, p, 0); ..... }
p->sched_class->task_new对应的函数是task_new_fair:
static void task_new_fair(struct rq *rq, struct task_struct *p) { struct cfs_rq *cfs_rq = task_cfs_rq(p); struct sched_entity *se = &p->se, *curr = cfs_rq->curr; int this_cpu = smp_processor_id(); sched_info_queued(p); update_curr(cfs_rq); place_entity(cfs_rq, se, 1); /* ‘curr‘ will be NULL if the child belongs to a different group */ if (sysctl_sched_child_runs_first && this_cpu == task_cpu(p) && curr && curr->vruntime < se->vruntime) { /* * Upon rescheduling, sched_class::put_prev_task() will place * ‘current‘ within the tree based on its new key value. */ swap(curr->vruntime, se->vruntime); resched_task(rq->curr); } enqueue_task_fair(rq, p, 0); }
place_entity计算新进程的vruntime:
static void place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial) { u64 vruntime = cfs_rq->min_vruntime; /* * The ‘current‘ period is already promised to the current tasks, * however the extra weight of the new task will slow them down a * little, place the new task so that it fits in the slot that * stays open at the end. */ if (initial && sched_feat(START_DEBIT)) vruntime += sched_vslice(cfs_rq, se); if (!initial) { //先不看这里, } se->vruntime = vruntime; }
check_preempt_curr(rq, p, 0);这个函数就直接调用了check_preempt_wakeup:
/* * Preempt the current task with a newly woken task if needed: */ 我略去了一些不太重要的代码 static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int sync) { struct task_struct *curr = rq->curr; struct sched_entity *se = &curr->se, *pse = &p->se; //se是当前进程,pse是新进程 /* * Only set the backward buddy when the current task is still on the * rq. This can happen when a wakeup gets interleaved with schedule on * the ->pre_schedule() or idle_balance() point, either of which can * drop the rq lock. * * Also, during early boot the idle thread is in the fair class, for * obvious reasons its a bad idea to schedule back to the idle thread. */ if (sched_feat(LAST_BUDDY) && likely(se->on_rq && curr != rq->idle)) set_last_buddy(se); set_next_buddy(pse); while (se) { if (wakeup_preempt_entity(se, pse) == 1) { resched_task(curr); break ; } se = parent_entity(se); pse = parent_entity(pse); } }
wakeup_preempt_entity(se, pse)判断后者是否能够抢占前者:
/* * Should ‘se‘ preempt ‘curr‘. * * |s1 * |s2 * |s3 * g * |<--->|c * * w(c, s1) = -1 * w(c, s2) = 0 * w(c, s3) = 1 * */ static int wakeup_preempt_entity(struct sched_entity *curr, struct sched_entity *se) { s64 gran, vdiff = curr->vruntime - se->vruntime; if (vdiff <= 0) return -1; gran = wakeup_gran(curr); if (vdiff > gran) return 1; return 0; }
/*** * try_to_wake_up - wake up a thread * @p: the to-be-woken-up thread * @state: the mask of task states that can be woken * @sync: do a synchronous wakeup? * * Put it on the run-queue if it‘s not already there. The "current" * thread is always on the run-queue (except when the actual * re-schedule is in progress), and as such you‘re allowed to do * the simpler "current->state = TASK_RUNNING" to mark yourself * runnable without the overhead of this. * * returns failure only if the task is already active. */ static int try_to_wake_up(struct task_struct *p, unsigned int state, int sync) { int cpu, orig_cpu, this_cpu, success = 0; unsigned long flags; struct rq *rq; rq = task_rq_lock(p, &flags); if (p->se.on_rq) goto out_running; update_rq_clock(rq); activate_task(rq, p, 1); success = 1; out_running: check_preempt_curr(rq, p, sync); p->state = TASK_RUNNING; out: current->se.last_wakeup = current->se.sum_exec_runtime; task_rq_unlock(rq, &flags); return success; }
/* * schedule() is the main scheduler function. */ asmlinkage void __sched schedule(void ) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; need_resched: preempt_disable(); //在这里面被抢占可能出现问题,先禁止它! cpu = smp_processor_id(); rq = cpu_rq(cpu); rcu_qsctr_inc(cpu); prev = rq->curr; switch_count = &prev->nivcsw; release_kernel_lock(prev); need_resched_nonpreemptible: spin_lock_irq(&rq->lock); update_rq_clock(rq); clear_tsk_need_resched(prev); //清除需要调度的位 //state==0是TASK_RUNNING,不等于0就是准备睡眠,正常情况下应该将它移出运行队列 //但是还要检查下是否有信号过来,如果有信号并且进程处于可中断睡眠就唤醒它 //注意对于需要睡眠的进程,这里调用deactive_task将其移出队列并且on_rq也被清零 //这个deactivate_task函数就不看了,很简单 if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { if (unlikely(signal_pending_state(prev->state, prev))) prev->state = TASK_RUNNING; else deactivate_task(rq, prev, 1); switch_count = &prev->nvcsw; } if (unlikely(!rq->nr_running)) idle_balance(cpu, rq); //这两个函数都是重点,我们下面分析 prev->sched_class->put_prev_task(rq, prev); next = pick_next_task(rq, prev); if (likely(prev != next)) { sched_info_switch(prev, next); rq->nr_switches++; rq->curr = next; ++*switch_count; //完成进程切换,不讲了,跟CFS没关系 context_switch(rq, prev, next); /* unlocks the rq */ /* * the context switch might have flipped the stack from under * us, hence refresh the local variables. */ cpu = smp_processor_id(); rq = cpu_rq(cpu); } else spin_unlock_irq(&rq->lock); if (unlikely(reacquire_kernel_lock(current) < 0)) goto need_resched_nonpreemptible; preempt_enable_no_resched(); //这里新进程也可能有TIF_NEED_RESCHED标志,如果新进程也需要调度则再调度一次 if (unlikely(test_thread_flag(TIF_NEED_RESCHED))) goto need_resched; }
entity_tick函数更新状态信息,然后检测是否满足抢占条件:
static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued) { /* * Update run-time statistics of the ‘current‘. */ update_curr(cfs_rq); //....无关代码 if (cfs_rq->nr_running > 1 || !sched_feat(WAKEUP_PREEMPT)) check_preempt_tick(cfs_rq, curr); }
update_curr函数:
static void update_curr(struct cfs_rq *cfs_rq) { struct sched_entity *curr = cfs_rq->curr; u64 now = rq_of(cfs_rq)->clock; //这个clock刚刚在scheduler_tick中更新过 unsigned long delta_exec; /* * Get the amount of time the current task was running * since the last time we changed load (this cannot * overflow on 32 bits): */ //exec_start记录的是上一次调用update_curr的时间,我们用当前时间减去exec_start //就得到了从上次计算vruntime到现在进程又运行的时间,用这个时间换算成vruntime //然后加到vruntime上,这一切是在__update_curr中完成的 delta_exec = (unsigned long )(now - curr->exec_start); __update_curr(cfs_rq, curr, delta_exec); curr->exec_start = now; if (entity_is_task(curr)) { struct task_struct *curtask = task_of(curr); cpuacct_charge(curtask, delta_exec); account_group_exec_runtime(curtask, delta_exec); } } /* * Update the current task‘s runtime statistics. Skip current tasks that * are not in our scheduling class. */ static inline void __update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr, unsigned long delta_exec) { unsigned long delta_exec_weighted; //前面说的sum_exec_runtime就是在这里计算的,它等于进程从创建开始占用CPU的总时间 curr->sum_exec_runtime += delta_exec; //下面变量的weighted表示这个值是从运行时间考虑权重因素换算来的vruntime,再写一遍这个公式 //vruntime(delta_exec_weighted) = 实际运行时间(delta_exe) * 1024 / 进程权重 delta_exec_weighted = calc_delta_fair(delta_exec, curr); //将进程刚刚运行的时间换算成vruntime后立刻加到进程的vruntime上。 curr->vruntime += delta_exec_weighted; //因为有进程的vruntime变了,因此cfs_rq的min_vruntime可能也要变化,更新它。 //这个函数不难,就不跟进去了,就是先取tmp = min(curr->vruntime,leftmost->vruntime) //然后cfs_rq->min_vruntime = max(tmp, cfs_rq->min_vruntime) update_min_vruntime(cfs_rq); }
更新完CFS状态之后回到entity_tick中,这时需要检测是否满足抢占条件,这里也是CFS的关键之一:
static void check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr) { unsigned long ideal_runtime, delta_exec; //这里sched_slice跟上面讲过的sched_vslice很象,不过sched_vslice换算成了vruntime, //而这里这个就是实际时间,没有经过换算,返回值的就是此进程在一个调度周期中应该运行的时间 ideal_runtime = sched_slice(cfs_rq, curr); //上面提到过这个公式了,计算进程已占用的CPU时间,如果超过了应该占用的时间(ideal_runtime) //则设置TIF_NEED_RESCHED标志,在退出时钟中断的过程中会调用schedule函数进行进程切换 delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime; if (delta_exec > ideal_runtime) resched_task(rq_of(cfs_rq)->curr); }
实现了多用户多任务并行执行
可以有效管理和调度进入计算机系统主存储器运行的程序
在现代信息高速发展的社会,效率的重要性不言而喻,而该操作系统进程的设计可以说是符合要求的
标签:roc 进程创建 likely 寄存器 备份 after sof 发展 security
原文地址:https://www.cnblogs.com/baijiaxuandada/p/8977125.html