标签:而在 激活 没有 并且 ati 额外 cpe 拼接 bsp
GoogleNet设计的初衷是为了提高在网络里面的计算资源的利用率。
网络越大,意味着网络的参数较多,尤其当数据集很小的时候,网络更容易发生过拟合。网络越大带来的另一个缺点就是计算资源的利用率会急剧增加。例如,如果两个卷积层是串联的,他们滤波器数量中任何一个均匀增加都会导致计算资源的二次方浪费。解决这两个问题的方法是用稀疏连接的结构代替全连接。在早期为了打破网络的对称性和提高学习能力,传统的网络都使用随机的稀疏连接,但是计算机硬件对非均匀的稀疏连接的计算效率很差,所以在Alexnet中又启用了全连接,为的是更好的优化并行运算。Incpetion结构因此被提出,它既能保持网络结构的稀疏性,又能利用密集矩阵的高性能计算。
a
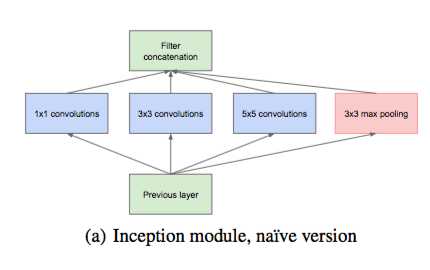
1.该结构采用了不同大小的卷积核,较小的卷积能够提取局部特征,较大的卷积能够渐近全局特征,而且不同大小的卷积有不同的感受野,能够提高网络的鲁棒性,最后通过concatenate合并这些特征。
2.之所以用1x1,3x3,5x5的卷积是为了方便对齐,假设卷积核的步长为1,则只需pad=0、1、2,卷积之后便可得到相同维度的特征映射,就可以直接将他们拼接起来。
3.在该结构中还加入最大池化,最大池化作用的是之前层的输出,目的应该是提供转移翻转不变性。
4.在网络的较高层,特征越抽象,并且网络的感受野变大,所以通常3x3和5x5的卷积数量会增加,会引入大量的参数。当引入池化单元后,参数更多,因为输出滤波器的数量等于前一个阶段滤波器的数量,会导致不可避免的参数膨胀。
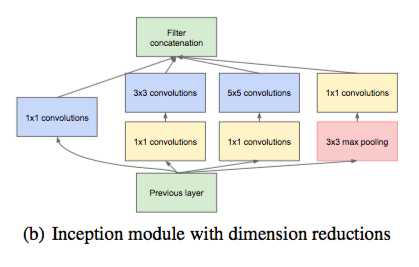
为了解决参数过多的问题,在Inception中引入了1x1的卷积。1x1的卷积有以下两个好处:
(1) 最重要的是1x1的卷积起到了维度衰减的作用,移除了计算瓶颈。假设原来Inception模块的输入特征映射为28x28x192,其中1x1卷积的通道数为64,3x3卷积通道数为128,5x5卷积通道数为32,则卷积核的参数为1x1x192x64+3x3x192x128+5x5x192x32,而在b结构中加入通道数为96和16的1x1卷积,则参数为1x1x192x64+(1x1x192x96+3x3x96x128)+(1x1x192x16+5x5x16x32),参数减少到了原来的1/3。
(2) 通常在1x1的卷积后面会引入一个非线性激活函数,也就是Relu,相当于引入了更多的非线性变换,提高了网络的表示能力。
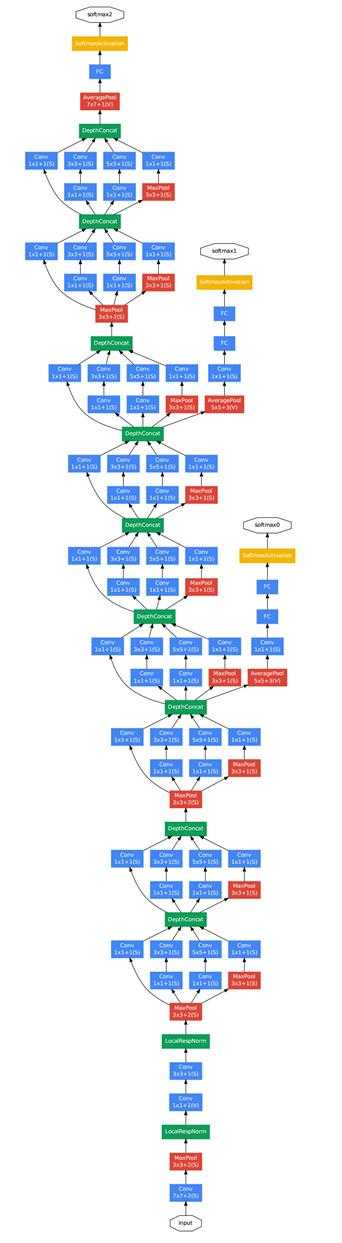
由图可知,Googlenet是由多个Inception模块堆叠而成,它的深度达到了22层,并且网络最后没有使用全连接层而是采用了平均池化层,这样做的好处是减少了参数,防止过拟合。并且为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传播梯度,在测试阶段这两个softmax会被移除。至于为什么不是在一开始就堆叠Inception模块,而是用几个卷积层加池化层是因为在网络的早期,输出的特征映射尺度通常很大,使用单独的卷积层和池化层能够降低特征映射的大小,减少参数,防止过拟合。
标签:而在 激活 没有 并且 ati 额外 cpe 拼接 bsp
原文地址:https://www.cnblogs.com/czy4869/p/8977788.html