标签:cal ima 分辨率 加载 另一个 根据 edr loading table
在App Store上显示的下载大小和实际下载下来的大小,我们通过下表做一个对比:
|
iPhone型号
|
系统
|
AppStore 显示大小
|
下载到设备大小
|
|---|---|---|---|
| iPhone6 | 10.2.1 | 91.5MB | 88.9MB |
| iPhone6 | 10.1.1 | 91.5MB | 88.9MB |
| iPhone6 | 9.3.5 | 91.5MB | 84.8MB |
| iPhone 5 | 9.2 | 91.5MB | 84.8MB |
| iPhone6 plus | 10.0.2 | 95.7MB | 93.2MB |
| iPhone7 plus | 10.3.0 | 95.7MB | 93.2MB |
| iPhone5C | 9.2 | 83.9MB | 76MB |
| iPhone5S | 7.1.1 | 147MB | 144MB |
| iPhone5C | 7.1.2 | 147MB | 未知 |
| iPhone5C 越狱 | 8.1.1 | 83.9MB | 144MB |
从上表可以看到:
【App Thinning】:对于iOS应用来说,应用瘦身仅支持最新版本的iTunes,以及运行iOS 9.0或者更高系统的设备,否则的话,App Store将会为用户分发统一的安装包。iOS 9 在发布时隐含一个 Bug , App Thinning ( App 瘦身)无法正确运作。随着 iOS 9.0.2 的发布,此 Bug 已被修复, App 瘦身终于可以运作如常。从 App Store 下载 App 时请谨记这点。App Thinning 会自动检测用户的设备类型(即型号名称)并且只下载当前设备所适用的内容。换句话说,如果使用的是 iPad Mini 1(1x分辨率且非 retina 显示屏)那么只会下载 1x分辨率所使用的文件。更强大和更高分辨率的 ipad(如iPad Mini 3或 4)所使用的资源将不会被下载。因为用户仅需下载自己当前使用的特定设备所需的内容,这不仅加快了下载速度,还节约了设备的存储空间。
苹果建议删除一些无用的执行代码或资源文件。下面我们分别从这两方面来分析安装包瘦身的一些方法和工具。
资源文件包括图片、声音、配置文件、文本文件(例如rtf文件)、xib(在安装包中后缀名为nib)、storyboard等。对于声音、配置文件、文本文件这三类资源文件,一般在安装包中数量不多,可自行在工程中根据实际情况,进行删除或保留。声音文件过大的话,可以考虑用如下命令做压缩:
//tritone.caf为声音文件 afconvert -f AIFC -d ima4 tritone.caf
xib和storyboard文件实际上是一个xml文件,如果某个页面没有使用,可直接删除。这里主要说一下对图片资源的处理方式。
对图片资源类文件,一般采取的方法是这几种:
在这里推荐使用工具LSUnusedResources。它在脚本的基础上,做了两个改进:
接下来,打开工具LSUnusedResources,点击“Browse...”按钮,选择工程所在目录,点击"Search"按钮,即可开始搜索,如下图所示:
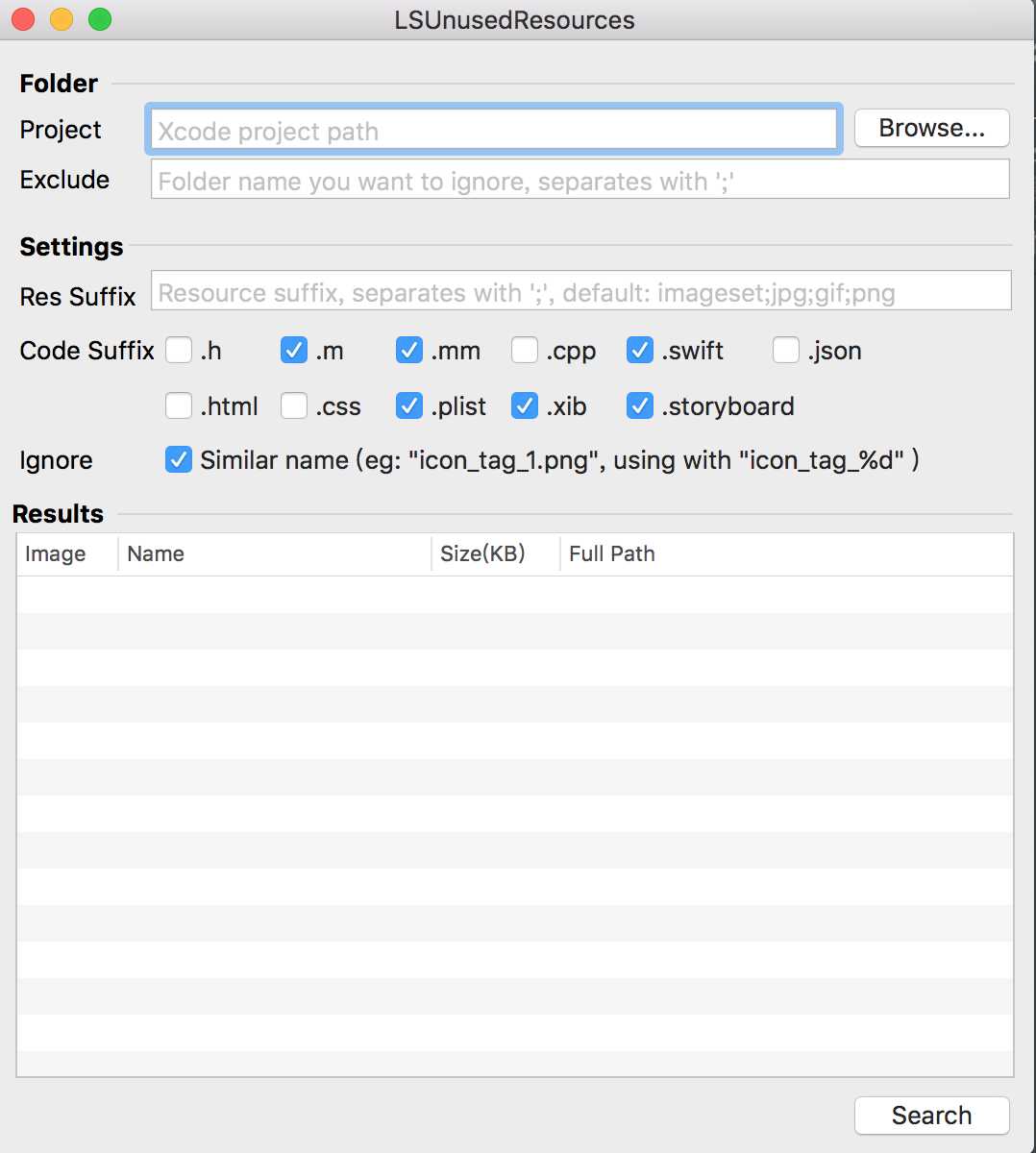
搜索结果出来之后,选中某行,点击“Delete”按钮即可直接删除资源。
压缩工具有很多,这里介绍两个好用的:
【建议】:对于较大尺寸的图片,可以和设计沟通,在不失真和影响效果的前提下,使用TinyPNG进行压缩;较小尺寸的图片,建议使用ImageOptiom。
我们都知道,图片资源的导入方式有如下几种:
1. Assets.xcassets。
2. CreateGroup
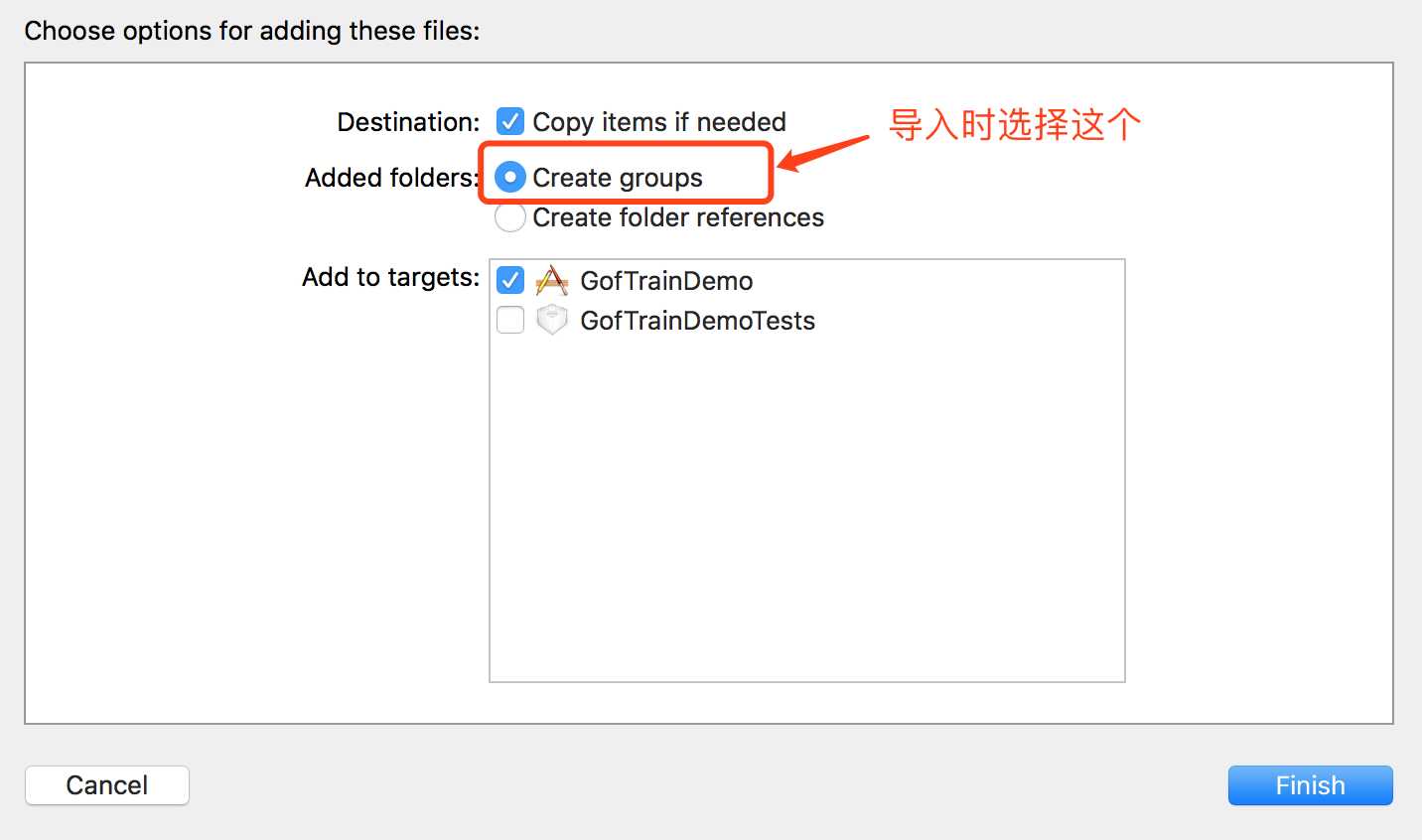
3. CreateFolderRefences
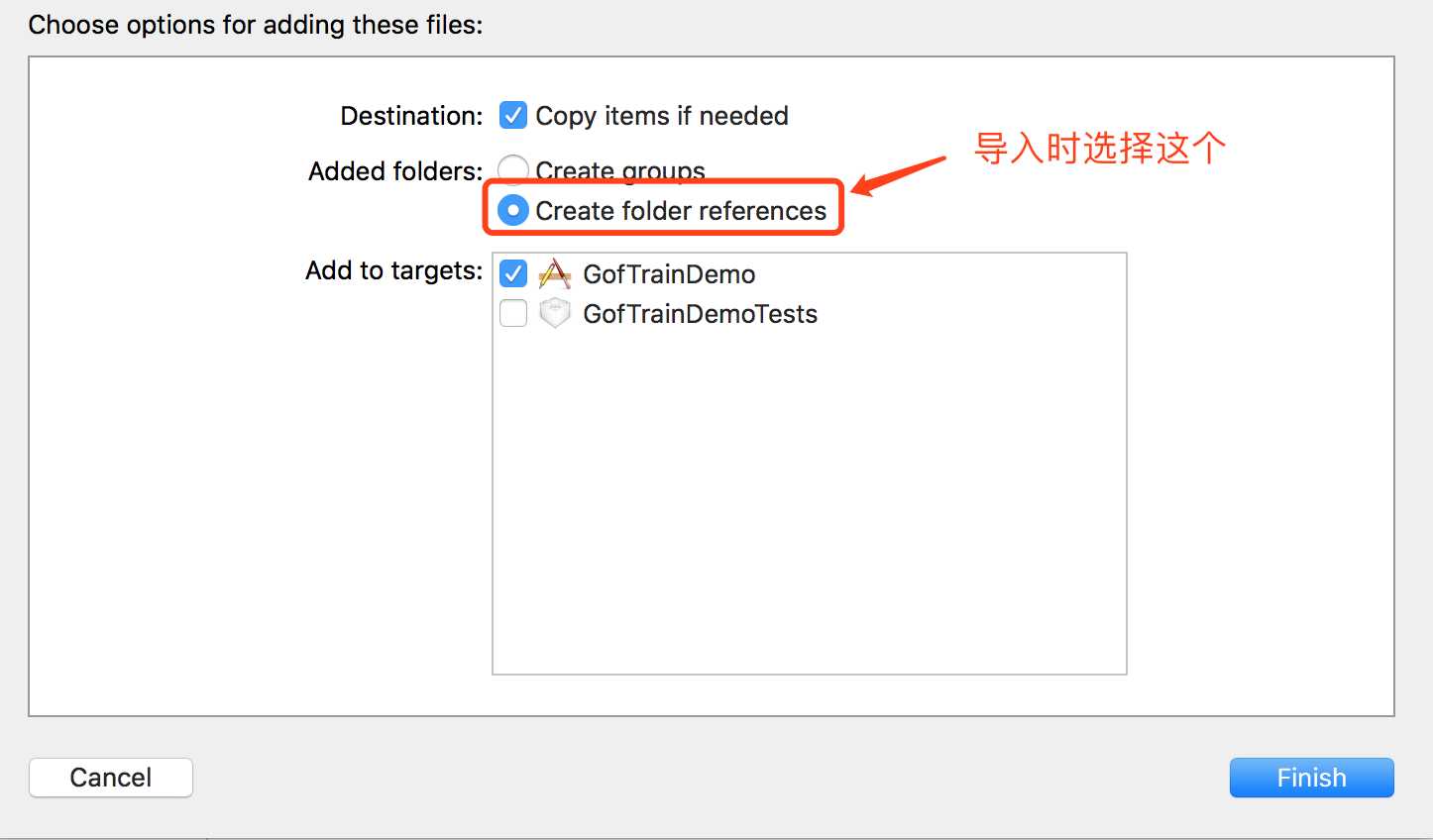
【说明】:蓝色文件夹只是将文件单纯的创建了引用,这些文件不会被编译,所以在使用的时候需要加入其路径。
4. PDFs矢量图(Xcode6+)
5. Bundle(包)
对于上面这几种不同的导入方式,会对打出的包的大小有影响么?
经过测试得知:CreateGroup、CreateFolderRefences两种方式打出来的包,图片都会直接放在.app文件中,所以打包前后,图片的大小不会改变。而加入到Assets.xcassets中的方法则不同,打包后,在.app中会生成Assets.car文件来存储Assets.xcassets中的图片,并且文件大小也大大降低。
| 测试 |
打包前Assets.xcassets文件夹 |
打包后的Assets.car文件夹 |
| 第一次 |
32.7MB |
16.3MB |
| 第二次 | 33.5MB | 26.1MB |
从表格数据可以看到,使用Assets.xcassets来管理图片也可以达到ipa瘦身的效果。
值得留意的是,在将图片资源移到Assets.xcassets管理的时候,一般情况下会自动生成与图片名称相同的,比如loading@2x.png和loading@3x.png会自动放置到一个同名的loading文件夹中。然而有一些不规则命名的图片,会出现一些奇怪的问题:
因此在移动的时候,一定要细致对比。
我们知道,iPhone设备目前主要有四种尺寸:3.5英寸、4英寸、4.7英寸、5.5英寸,对于这几个尺寸的设备,我们来看一下具体的设备型号和屏幕相关信息:
| 机型 | 屏幕宽高(point) | 渲染像素(pixel) | 物理像素(pixel) | 屏幕对角线长度(英寸) | 屏幕模式 |
| iPhone 2G, 3G, 3GS | 320 * 480 | 320 * 480 | 320 * 480 | 3.5(163PPI) | 1x |
| iPhone 4, 4s | 320 * 480 | 640 * 960 | 640 * 960 | 3.5 (326PPI) | 2x |
| iPhone 5, 5s | 320 * 568 | 640 * 1136 | 640 * 1136 | 4 (326PPI) | 2x |
| iPhone 6, 6s, 7 | 375 * 667 | 750 * 1334 | 750 * 1334 | 4.7 (326PPI) | 2x |
| iPhone 6 Plus, 6s Plus, 7 Plus | 414 * 736 | 1242 * 2208 | 1080 * 1920 | 5.5 (401PPI) | 3x |
对于上表中的几个概念,这里做一下说明:
在实际的开发中,所有控件的坐标以及控件大小都是以点为单位的,假如屏幕上需要展示一张 20 * 20 (单位:point)大小的图片,那么设计师应该怎么给图呢?这里就会用到屏幕模式的概念,如果屏幕是 2x,那么就需要提供 40 * 40 (单位: pixel)大小的图片,如果屏幕是 3x,那么就提供 60 * 60 大小的图片,且图片的命名需要遵守以下规范:
<ImageName><device_modifier>.<filename_extension><ImageName>@2x<device_modifier>.<filename_extension><ImageName>@3x<device_modifier>.<filename_extension>其中:
~ipad 或者 ~iphone, 当需要为 iPad 和 iPhone 分别指定一套图时需要加上此字段2x屏幕的设备会自动加载 xxx@2x.png 命名的图片资源,3x屏幕的设备会自动加载 xxx@3x.png 的图片。从友盟统计数据可以看到,现在基本没有 1x屏幕的设备了,所以可以不用提供这个分辨率的图片。
至于开发中,技术人员和设计人员关于设计和切图的工作流程和规范,可以参看知乎上的这篇文章介绍。
AppCode是一种智能的Objective-C集成开发环境,由专业的开发收费IDE的公司Jetbrains开发,具有这些特点:
在这里,我们可以用它的inspect code来扫描无用代码,包括无用的类、函数、宏定义、value、属性等,而safe delete功能使得删除一些由于runtime被调用到的代码时更加安全智能。扫描结果示例:
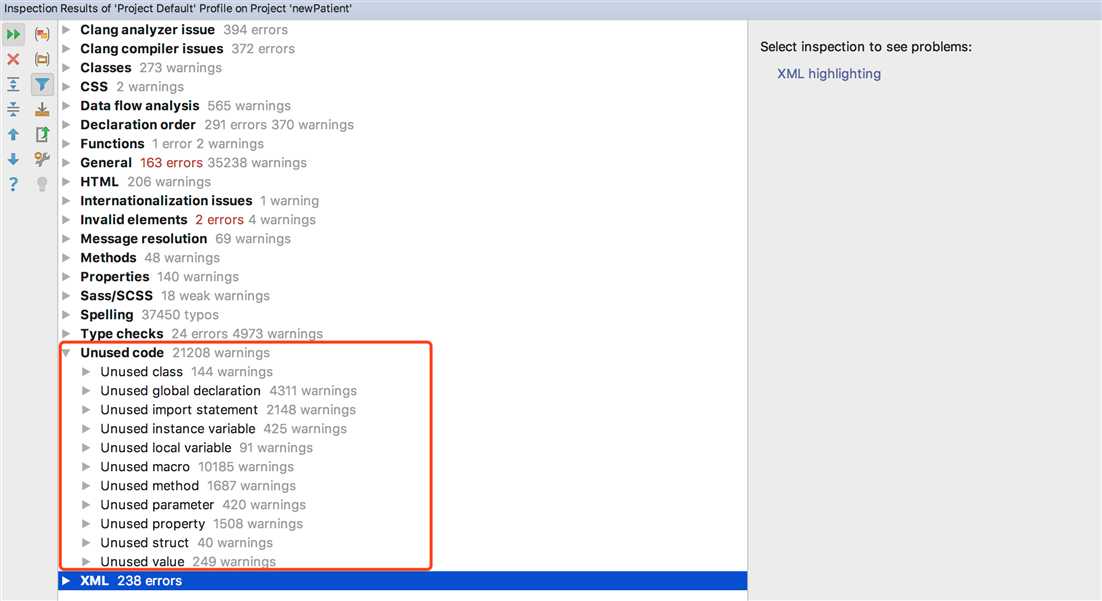
【说明】:如果工程很大,这个扫描的时间可能会比较长。我们现在的工程中,大概有2700个类,扫描时间在一个半小时。
实际上,在2.1的扫描结果中,包含无用类,但2.1的扫描时间会比较长,另外扫描出来的内容也较多。如果只是需要清理无用类的话,可以用如下脚本:
# -*- coding: UTF-8 -*- #!/usr/bin/env python # 使用方法:python py文件 Xcode工程文件目录 import sys import os import re if len(sys.argv) == 1: print ‘请在.py文件后面输入工程路径‘ sys.exit() projectPath = sys.argv[1] print ‘工程路径为%s‘ % projectPath resourcefile = [] totalClass = set([]) unusedFile = [] pbxprojFile = [] def Getallfile(rootDir): for lists in os.listdir(rootDir): path = os.path.join(rootDir, lists) if os.path.isdir(path): Getallfile(path) else: ex = os.path.splitext(path)[1] if ex == ‘.m‘ or ex == ‘.mm‘ or ex == ‘.h‘: resourcefile.append(path) elif ex == ‘.pbxproj‘: pbxprojFile.append(path) Getallfile(projectPath) print ‘工程中所使用的类列表为:‘ for ff in resourcefile: print ff for e in pbxprojFile: f = open(e, ‘r‘) content = f.read() array = re.findall(r‘\s+([\w,\+]+\.[h,m]{1,2})\s+‘,content) see = set(array) totalClass = totalClass|see f.close() print ‘工程中所引用的.h与.m及.mm文件‘ for x in totalClass: print x print ‘--------------------------‘ for x in resourcefile: ex = os.path.splitext(x)[1] if ex == ‘.h‘: #.h头文件可以不用检查 continue fileName = os.path.split(x)[1] print fileName if fileName not in totalClass: unusedFile.append(x) for x in unusedFile: resourcefile.remove(x) print ‘未引用到工程的文件列表为:‘ writeFile = [] for unImport in unusedFile: ss = ‘未引用到工程的文件:%s\n‘ % unImport writeFile.append(ss) print unImport unusedFile = [] allClassDic = {} for x in resourcefile: f = open(x,‘r‘) content = f.read() array = re.findall(r‘@interface\s+([\w,\+]+)\s+:‘,content) for xx in array: allClassDic[xx] = x f.close() print ‘所有类及其路径:‘ for x in allClassDic.keys(): print x,‘:‘,allClassDic[x] def checkClass(path,className): f = open(path,‘r‘) content = f.read() if os.path.splitext(path)[1] == ‘.h‘: match = re.search(r‘:\s+(%s)\s+‘ % className,content) else: match = re.search(r‘(%s)\s+\w+‘ % className,content) f.close() if match: return True ivanyuan = 0 totalIvanyuan = len(allClassDic.keys()) for key in allClassDic.keys(): path = allClassDic[key] index = resourcefile.index(path) count = len(resourcefile) used = False offset = 1 ivanyuan += 1 print ‘完成‘,ivanyuan,‘共:‘,totalIvanyuan,‘path:%s‘%path while index+offset < count or index-offset > 0: if index+offset < count: subPath = resourcefile[index+offset] if checkClass(subPath,key): used = True break if index - offset > 0: subPath = resourcefile[index-offset] if checkClass(subPath,key): used = True break offset += 1 if not used: str = ‘未使用的类:%s 文件路径:%s\n‘ %(key,path) unusedFile.append(str) writeFile.append(str) for p in unusedFile: print ‘未使用的类:%s‘ % p filePath = os.path.split(projectPath)[0] writePath = ‘%s/未使用的类.txt‘ % filePath f = open(writePath,‘w+‘) f.writelines(writeFile) f.close()
同样的工程,这个脚本执行速度大概是三分钟,结果如下:
标签:cal ima 分辨率 加载 另一个 根据 edr loading table
原文地址:https://www.cnblogs.com/gongyuhonglou/p/8985208.html