标签:span -- 第一个 default and 代码 orm location ddr
转自:https://www.cnblogs.com/woodytu/p/5821827.html
在今天的文章里,我想谈下SQL Server里非常重要的话题:SQL Server如何处理文件的文件组。当你用CREATE DATABASE命令创建一个简单的数据库时,SQL Server为你创建2个文件:
数据文件本身在有且只有一个主文件组里创建。默认情况下,在主文件组里,SQL Server存储素有的数据(用户表,系统表等)。那有额外的文件和文件组的目的是什么?我们来看下。
当你为你的数据创建额外的文件组,你可以在它们里面存储你定义的表和索引,这个会在多个方面帮助你
通常,你应该至少有一个从文件组,这里你可以存储你自己创建的数据库对象。你不应该在主文件组里存储SQL Server为你创建的其他系统对象。
当你创建了你自己的文件组,你也要至少放一个文件进去。另外,你可以增加额外的文件到文件组。这也会提高你的负荷性能,因为SQL Server会散步数据在所有的文件间,即所谓的轮询调度分配算法(Round Robin Allocation Algorithm)。第一个64K在第一个文件存储,第二个64k在第二个文件存储,第三个区在第一个文件存储(在你的文件组里,你有2个文件时)。
使用这个方法,SQL Server可以在缓冲池里闩锁分配位图页(PFS,GAM,SGAM)的多个副本,并提高你的负荷性能。你也可以用这个方法解决在TempDb里默认配置的同个问题。另外,SQL Server也会确保文件组的所有文件在同一时间点满——通过所谓的比例填充算法(Proportional Fill Algorithm)。因此,在文件组里你的所有文件有同样的初始大小和自动增长参数非常重要。不然轮询调度分配算法就不能正常工作。
现在我们来看下一个实例,如何创建额外文件组里有多个文件在里面的数据库。下列代码展示了你必须用到的CREATE DATABASE命令来完成这个任务。

-- Create a new database
CREATE DATABASE MultipleFileGroups ON PRIMARY
(
-- Primary File Group
NAME = ‘MultipleFileGroups‘,
FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\MultipleFileGroups.mdf‘,
SIZE = 5MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 1024KB
),
-- Secondary File Group
FILEGROUP FileGroup1
(
-- 1st file in the first secondary File Group
NAME = ‘MultipleFileGroups1‘,
FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\MultipleFileGroups1.ndf‘,
SIZE = 1MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 1024KB
),
(
-- 2nd file in the first secondary File Group
NAME = ‘MultipleFileGroups2‘,
FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\MultipleFileGroups2.ndf‘,
SIZE = 1MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 1024KB
)
LOG ON
(
-- Log File
NAME = ‘MultipleFileGroups_Log‘,
FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\MultipleFileGroups.ldf‘,
SIZE = 5MB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 1024KB
)
GO
创建完数据库后,问题是如何把表或索引放到特定的文件组?你可以用ON关键字人为制定文件组,如下代码所示:
CREATE TABLE Customers ( FirstName CHAR(50) NOT NULL, LastName CHAR(50) NOT NULL, Address CHAR(100) NOT NULL, ZipCode CHAR(5) NOT NULL, Rating INT NOT NULL, ModifiedDate DATETIME NOT NULL, ) ON [FileGroup1] GO
另一个选项,你标记特定文件组为默认文件组。然后SQL Server自动创建新的数据库对象在没有指定ON关键字的文件组里。
-- FileGroup1 gets the default filegroup, where new database objects -- will be created ALTER DATABASE MultipleFileGroups MODIFY FILEGROUP FileGroup1 DEFAULT GO
这是我通常推荐的方法,因为你不需要再考虑,在创建完你的数据库对象后。因此现在让我们创建一个新的表,它会自动存储在FileGroup1文件组。
-- The table will be created in the file group "FileGroup1"
CREATE TABLE Test
(
Filler CHAR(8000)
)
GO
现在我们进行简单的测试:我们插入40000条记录到表。每条记录8K大小。因此我们插入了320MB数据到表。这是我刚才提的轮询调度分配算法,会进行操作:SQL Server会在2个文件间发放数据:第一个文件有160M的数据,第二个文件也会有160M的数据。
-- Insert 40.000 records, results in about 312MB data (40.000 x 8KB / 1024 = 312,5MB)
-- They are distributed in a round-robin fashion between the files in the file group "FileGroup1"
-- Each file will get about 160MB
DECLARE @i INT = 1
WHILE (@i <= 40000)
BEGIN
INSERT INTO Test VALUES
(
REPLICATE(‘x‘, 8000)
)
SET @i += 1
END
GO
接下来你可以在硬盘上看下,你会看到2个文件时同样的大小。
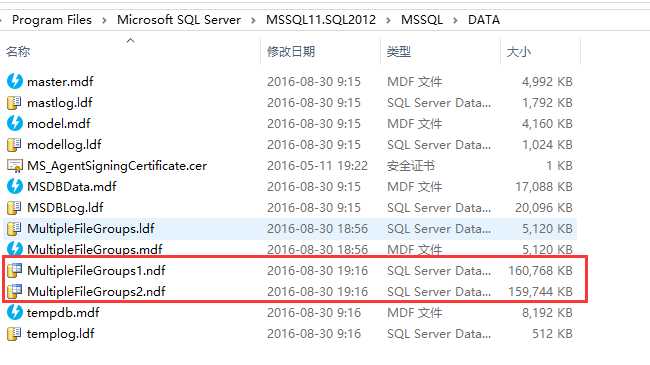
当你把这些文件放在不同的物理硬盘上,你可以同时访问它们。那就是在一个文件组里有多个文件的强大。
你也可以使用下列脚本获取数据库文件的相关信息。
--查看数据库文件与文件组信息
SELECT
name as [database_name],
COUNT (*) AS [DataFiles],
COUNT (DISTINCT data_space_id) AS [Filegroups],
SUM (size)*8/1024 AS [Size(MB)] --default Kb
FROM sys.master_files
WHERE [type_desc] = N‘ROWS‘ -- filter out log files/data_space_id 0
AND [database_id] > 0 -- filter out system databases
AND [FILE_ID] != 65537 -- filter out FILESTREAM
GROUP BY [database_id],name;
GO
-- Retrieve file statistics information about the created database files
DECLARE @dbId INT
SELECT @dbId = database_id FROM sys.databases WHERE name = ‘MultipleFileGroups‘
SELECT
sys.database_files.type_desc,
sys.database_files.physical_name,
sys.dm_io_virtual_file_stats.* FROM sys.dm_io_virtual_file_stats
(
@dbId,
NULL
)
INNER JOIN sys.database_files ON sys.database_files.file_id = sys.dm_io_virtual_file_stats.file_id
GO
标签:span -- 第一个 default and 代码 orm location ddr
原文地址:https://www.cnblogs.com/gered/p/8986648.html