标签:公众号 com span 入门 dia request 先来 node str
本文将以抓取百度搜索结果中关键词的相关搜索为例子,教会大家以nodejs制作最简单的爬虫:
开始之前呢,先来个公众号求粉:
将使用的node模块及属性介绍:
request:
用于发送页面请求,抓取页面代码
GET请求
cheerio:
cheerio 是一个 jQuery Core 的子集,其实现了 jQuery Core 中浏览器无关的 DOM 操作 API:
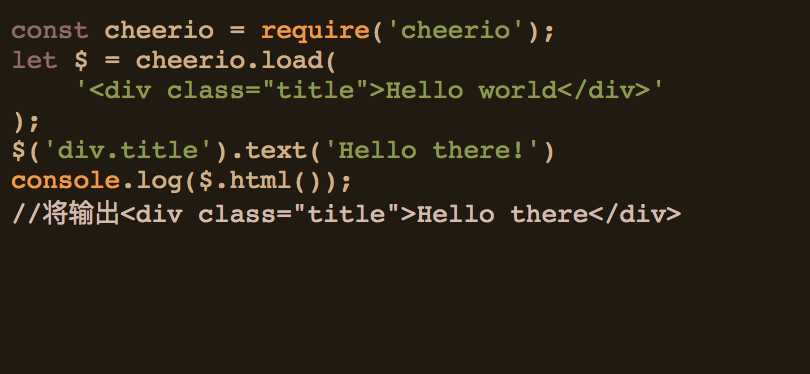
本例子中将使用load方法,以下是一个简单的示例:
express:
基于Node.js 平台,快速、开放、极简的 web 开发框架,这里主要用来做简单的路由功能,就不做详细介绍了,主要是用了get,具体可以参考官网。
具体实现:
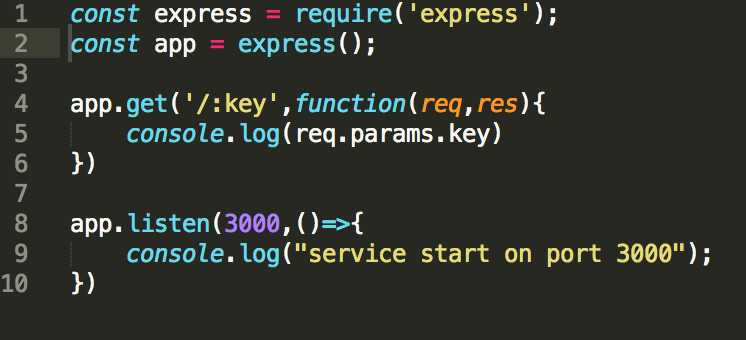
1.首先,我们要使用express搭建简单的node服务
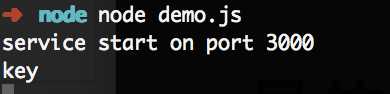
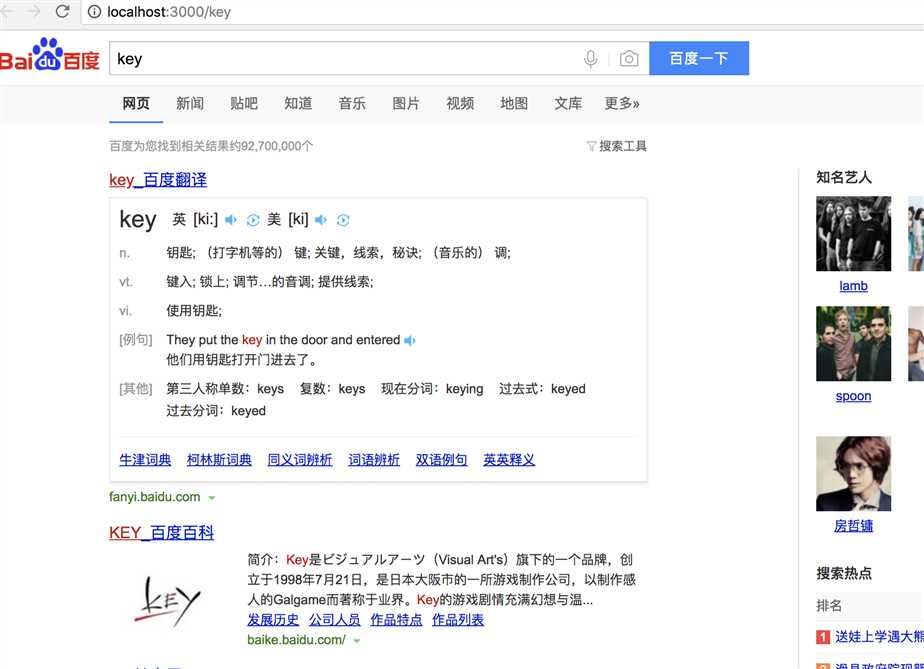
使用命令行运行node demo.js,并在浏览器中访问 localhost:3000/key 运行结果为
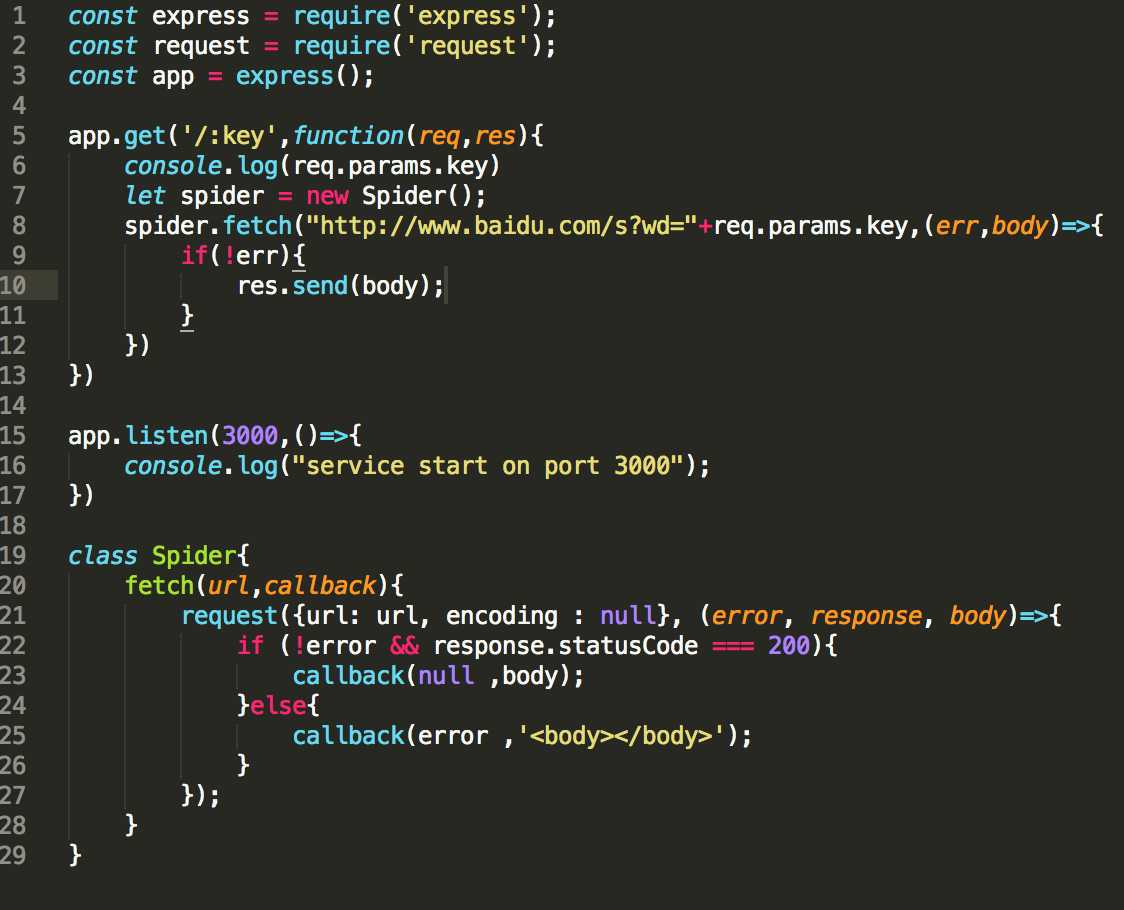
2. 使用request实现页面抓取功能
使用命令行运行node demo.js,并在浏览器中访问 localhost:3000/key 运行结果为
3.使用cheerio将页面代码解析为jquery格式,并用jQuery语法找到抓取的内容位置,这样这个爬虫就实现了!

想要知道具体的解决方案,请关注我的公众号哦~回复 “node爬虫”获取原文哟
公众号

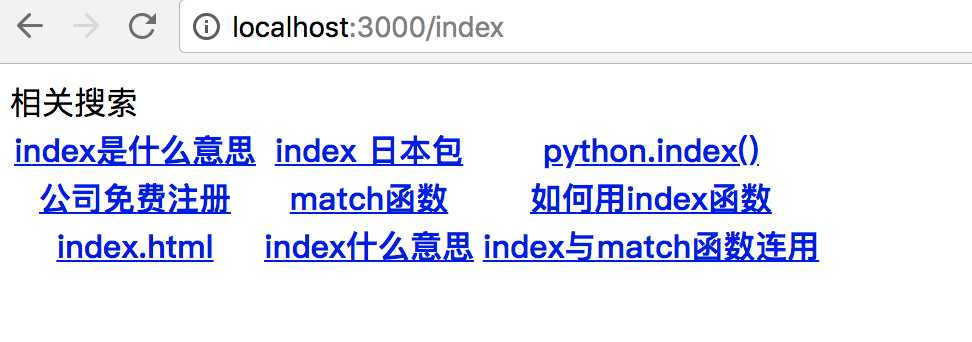
使用命令行运行node demo.js,并在浏览器中访问 localhost:3000/index 运行结果为
tips:
有些网站不是utf-8编码模式,这时可以使用iconv-lite来解除gb2312的乱码问题
当然各个网站都有反爬虫功能,可以通过 研究怎么模拟一个正常用户的请来规避部分问题(百度的中文搜索也会被屏蔽)
本文只是个入门,后序有机会将和大家详细讨论进阶版哦
nodejs实现最简单的爬虫
标签:公众号 com span 入门 dia request 先来 node str
原文地址:https://www.cnblogs.com/maorongmaomao/p/8987261.html