标签:包含 Collector 通配符 tps 良好的 dep 分类 关键字 spel
1. Lucene简介
最受欢迎的java开源全文搜索引擎开发工具包。提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索功能,或者是以此为基础建立起完整的全文检索引擎。是Apache的子项目,网址:http://lucene.apache.org/
2. Lucene用途
为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索功能,或者是以此为基础建立起完整的全文检索引擎。
3. Lucene适用场景
在应用中为数据库中的数据提供全文检索实现。
开发独立的搜索引擎服务、系统
4. Lucene的特性
1、稳定、索引性能高
每小时能够索引150GB以上的数据。
对内存的要求小——只需要1MB的堆内存
增量索引和批量索引一样快。
索引的大小约为索引文本大小的20%~30%。
2、高效、准确、高性能的搜索算法
良好的搜索排序。
强大的查询方式支持:短语查询、通配符查询、临近查询、范围查询等。
支持字段搜索(如标题、作者、内容)。
可根据任意字段排序
支持多个索引查询结果合并
支持更新操作和查询操作同时进行
支持高亮、join、分组结果功能
速度快
可扩展排序模块,内置包含向量空间模型、BM25模型可选
可配置存储引擎
3、跨平台
纯java编写。
作为Apache开源许可下的开源项目,你可在商业或开源项目中使用。
Lucene有多种语言实现版可选(如C、C++、Python等),不光是JAVA。
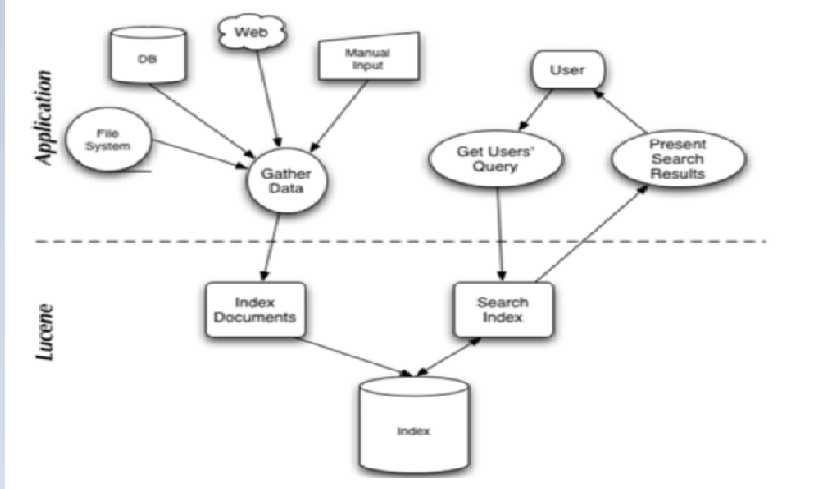
1. 数据收集
2. 创建索引
3. 索引存储
4. 搜索(使用索引)
1. 选用的Lucene版本
选用当前最新版 7.3.0 : https://lucene.apache.org/
2. 系统要求
JDK1.8 及以上版本
3. 集成:将lucene core的jar引入到你的应用中
方式一:官网下载 zip,解压后拷贝jar到你的工程
方式二:maven 引入依赖
4. Lucene 模块说明
core: Lucene core library 核心模块:分词、索引、查询
analyzers-*: 分词器
facet: Faceted indexing and search capabilities 提供分类索引、搜索能力
grouping: Collectors for grouping search results. 搜索结果分组支持
highlighter: Highlights search keywords in results 关键字高亮支持
join: Index-time and Query-time joins for normalized content 连接支持
queries: Filters and Queries that add to core Lucene 补充的查询、过滤方式实现
queryparser: Query parsers and parsing framework 查询表达式解析模块
spatial: Geospatial search 地理位置搜索支持 suggest: Auto-suggest and Spellchecking support 拼写检查、联想提示
5. 先引入lucene的核心模块
<!-- lucene 核心模块 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.3.0</version> </dependency>
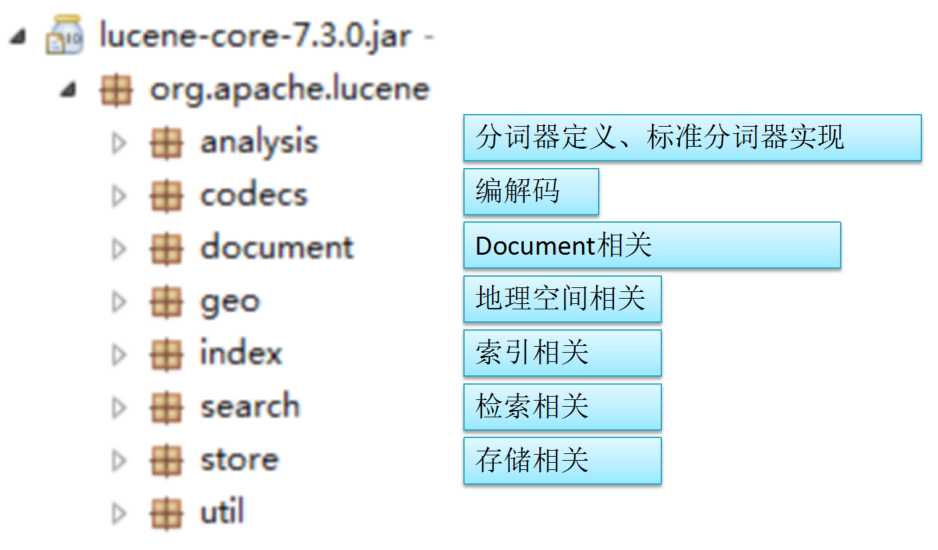
6. 了解核心模块的构成
搜索引擎系列二:Lucene(Lucene介绍、Lucene架构、Lucene集成)
标签:包含 Collector 通配符 tps 良好的 dep 分类 关键字 spel
原文地址:https://www.cnblogs.com/leeSmall/p/8992887.html