标签:图片 dad 目标 构造 提取 center 信息 匹配 合规
一、简介
关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结;
re作为Python中专为正则表达式相关功能做出支持的模块,提供了一系列方法来完成几乎全部类型的文本信息的处理工作,下面一一介绍:
二、re.compile()
在前一篇文章中我们使用过这个方法,它通过编译正则表达式参数,来返回一个目标对象的匹配模式,进而提高了正则表达式的效率,主要参数如下:
pattern:输入的欲编译正则表达式,需将正则表达式包裹在‘‘内传入,如‘aa*’
flags:编译标志位,用于从某个角度修改正则表达式的匹配方式,常用的有:
re.S:使.匹配包括换行在内的所有字符
re.I:使匹配对大小写不敏感
re.U:根据Unicode规则解析字符,主要用于对中文的匹配中
下面是几个简单的例子:
import re text = ‘即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。‘ ‘‘‘编译我们的正则表达式,规则为找到所有在双引号内的内容(不包括双引号)‘‘‘ regex = re.compile(‘“(.*?)”‘) ‘‘‘打印匹配结果‘‘‘ print(regex.findall(text))
运行结果:

可以看出,匹配到的所有内容会以列表的形式返回;
import re text = ‘即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。‘ ‘‘‘编译我们的正则表达式,规则为大小写英文字母至少出现一次的内容‘‘‘ regex = re.compile(‘[A-Za-z]+‘) ‘‘‘打印匹配结果‘‘‘ print(regex.findall(text))
运行结果:
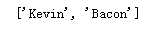
接下来我们对flags参数进行赋值,看看会实现怎样的功能:
import re text = ‘即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。‘ ‘‘‘编译我们的正则表达式,规则为小写英文字母至少出现一次的内容‘‘‘ regex = re.compile(‘[a-z]+‘)#未使用flags无视大小写 ‘‘‘打印匹配结果‘‘‘ print(regex.findall(text))
运行结果:
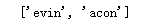
因为我们使用的正则表达式为[a-z]+,所以大写字母部分未能匹配到,下面我们不改变我们的正则表达式部分,而是对flags进行赋参:
import re text = ‘即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。‘ ‘‘‘编译我们的正则表达式,规则为小写英文字母至少出现一次的内容‘‘‘ regex = re.compile(‘[a-z]+‘,flags=re.I)#使用re.I无视大小写 ‘‘‘打印匹配结果‘‘‘ print(regex.findall(text))
运行结果:
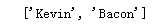
在使用flags=re.I来无视大小写的情况下,在原有的正则表达式的基础上,实现了对大写字母的匹配。
三、re.match()
这个方法个人觉得用的是不是很多,它表示以定义的正则表达式作为对目标字符串开头的匹配(对非开头部分不匹配),下面是一个简单的例子:
import re text = ‘What are you waiting for?‘ ‘‘‘成功匹配到开头,因为字符串开头是W‘‘‘ print(re.match(‘w‘,text,re.I).group())
运行结果:
当字符串开头不匹配时,即使字符串其他部分有匹配的也不返回值(即所谓的只匹配开头部分):
import re text = ‘What are you waiting for? where are you fucking from?‘ ‘‘‘未能成功匹配到开头,因为字符串开头是Wha‘‘‘ print(re.match(‘whe‘,text,re.I))
运行结果:
四、re.search()
re.search()的使用格式类似re.match(),即三个传入参数:pattern,string,flags,但与match匹配开头不同的是,search匹配的是文中出现的第一个满足条件的字符串部分并返回,对后续的不再进行匹配,下面是一个简单的例子:
import re text = ‘What are you waiting for? where are you fucking from?‘ ‘‘‘成功匹配到第一个出现的目标内容,后续的内容便不再匹配‘‘‘ print(re.search(‘a‘,text,re.I).group())
运行结果:
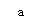
文中有很多a,但search遇到第一个a便停止匹配并返回这第一个值;
这里要注意一下,我在前面几个例子中使用到的group()方法,是针对match或search成功匹配并返回的对象,我们称之为match object,围绕它的常用方法如下:
strat():返回匹配开始的位置
end():返回匹配结束的位置
group():返回被re匹配的字符串
span():返回一个tuple格式的对象,标记了匹配开始,结束的位置,形如(start,end)
事实上,虽然说search只返回一个对象,但我们可以通过将正则表达式改造成若干子表达式拼接的形式,来返回多个分块的对象
import re text = ‘1213sdsdjAKNNK‘ ‘‘‘匹配复合表达式对应的内容(返回对象会根据子表达式进行分块),并分别打印第1、2、3块子内容‘‘‘ print(re.search(‘([1-9]+)*([a-z]+)*([A-Z]+)‘,text).group(1)) print(re.search(‘([1-9]+)*([a-z]+)*([A-Z]+)‘,text).group(2)) print(re.search(‘([1-9]+)*([a-z]+)*([A-Z]+)‘,text).group(3))
运行结果:

五、findall()
注意,这和我们在解析BeautifulSoup对象时使用到的findAll()拼写不同(虽然功能相似),它与match和search不同的是,它会根据传入的正则表达式部分来提取目标字符串中所有符合规则的部分,并传出为列表的形式,下面是一个简单的例子:
import re text = ‘即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。‘ ‘‘‘匹配text中所有以 听 开头的长度为2的字符串‘‘‘ print(re.findall(‘听.‘,text))
运行结果:
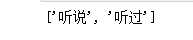
与前面在介绍re.compile()时对findall的用法不同,这里是re.findall(正则表达式,目标字符串)的格式,前面的是 编译好的正则模式.findall(目标字符串),这两种格式的功能等价;
六、re.finditer()
我们有时候会遇到这样的情况:目标字符串非常长(可能是一整篇小说),而符合我们正则表达式的目标内容也非常的多,这种时候如果沿用前面的做法使用re.findall()来一口气将所有结果提取出来保存在一个硕大的列表中,是件非常占用内存的事情,而Python中用来节省内存的生成器(generator)就派上了用场;
re.finditer(pattern,string,flags=0)就利用了这种机制,它构造出一个基于正则表达式pattern和目标字符串string的生成器,使得我们可以在对该生成器的循环中边循环边计算对应位置的值,即从始至终每一轮只保存了当前的位置和当前匹配到的内容,达到节省内存的作用,下面是一个简单的例子:
import re text = ‘abjijdianbdadjijijiha8hihanihhhiihiaaihidaihihaidhihaidahi‘ ‘‘‘构造我们的迭代器‘‘‘ obj = re.finditer(‘a.‘,text) ‘‘‘对obj进行迭代,每次返回当前位置匹配到的内容及对应的起始与结束位置‘‘‘ for i in obj: print(i.group()) print(i.span())
运行结果:

七、re.sub()
类似字符串操作中的replace(),只不过replace()中只能死板地设置固定的内容作为替换项,利用re.sub(pattern,repl,string,count)则可以基于正则表达式达到灵活匹配替换内容,pattern指定了正则表达式部分,repl指定了进行替换的新内容,string指定目标字符串,count指定了替换的次数,默认全部替换,其实前一篇文章结尾处我们得到一篇干净的新闻报道就用到了这种方法,下面再举一个简单的例子:
import re text = ‘abjijdianbdadjijijiha8hihanihhhiihiaaihidaihihaidhihaidahi‘ ‘‘‘构造我们的替代规则‘‘‘ obj = re.sub(‘a.‘,‘嘻嘻‘,text) ‘‘‘打印替换后内容‘‘‘ print(obj)
运行结果:

八、re.split()
类似于字符串处理中的split(),re.split()在原有基础上扩充了正则表达式的功能,re.split(pattern,string,maxsplit),其中pattern指定分隔符的正则表达式,string指定目标字符串,maxsplit指定最大分割个数,下面是一个简单的例子:
import re text = ‘abjijdianbdadjijijiha8hihanihhhiihiaaihidaihihaidhihaidahi‘ ‘‘‘构造我们的分割规则‘‘‘ obj = re.split(‘i.‘,text) ‘‘‘打印分割后内容‘‘‘ print(obj)
运行结果:
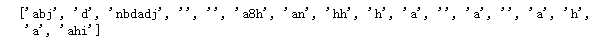
以上就是关于re模块的常用功能,接下来会以一篇实战来详细介绍实际业务中的网络数据采集过程。
标签:图片 dad 目标 构造 提取 center 信息 匹配 合规
原文地址:https://www.cnblogs.com/feffery/p/8993030.html