标签:dem pre 打开 int 区域 encoding 编码 testcase getcwd
前言
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的。
unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTestRunner
一、导入HTMLTestRunner
1.这个模块下载不能通过pip安装了,只能下载后手动导入,下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html
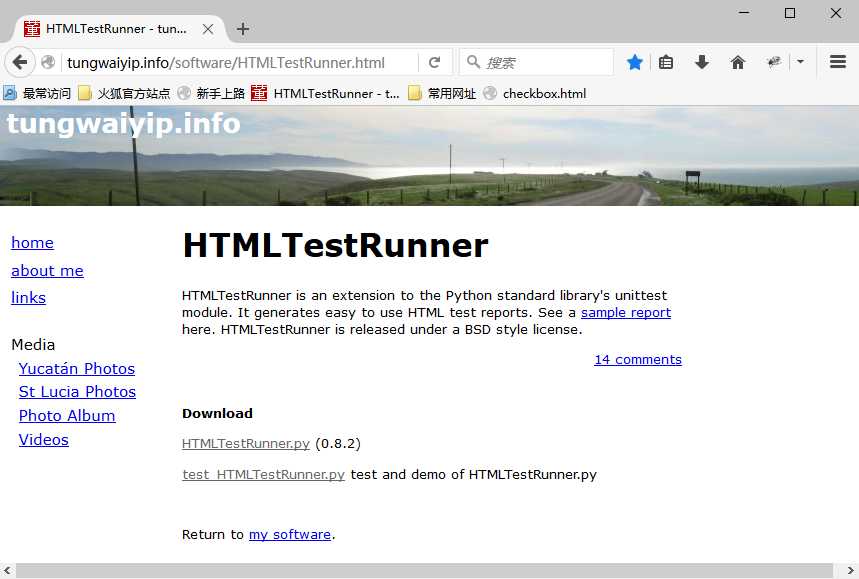
2.Download下HTMLTestRunner.py文件就是我们需要下载的包。
3.下载后手动拖到python安装文件的Lib目录下
二、demo解析
1.下载Download下的第二个文件test_HTMLTestRunner.py,这个就是官方给的一个测试demo了,从这个文件可以找到该模块的用法。
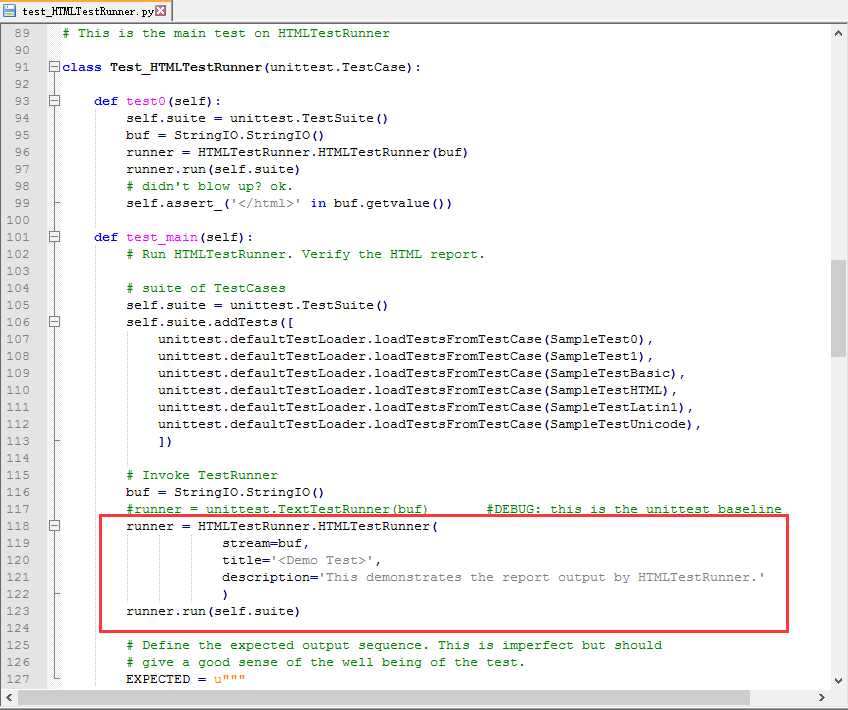
2.找到下图这段,就是官方给的一个demo了,test_main()里上半部分就是加载测试case,我们不需要搞这么复杂。
参考前面一篇内容就行了Selenium2+python自动化53-unittest批量执行(discover)
3.最核心的代码是下面的红色区域,这个就是本篇的重点啦。
三、生成html报告
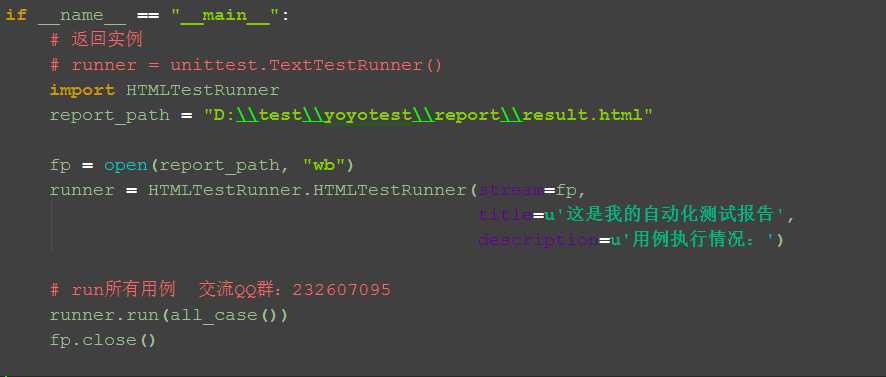
1.我们只需把上面红色区域代码copy到上一篇的基础上稍做修改就可以了,这里主要有三个参数:
--stream:测试报告写入文件的存储区域
--title:测试报告的主题
--description:测试报告的描述
2.report_path是存放测试报告的地址
四、测试报告详情
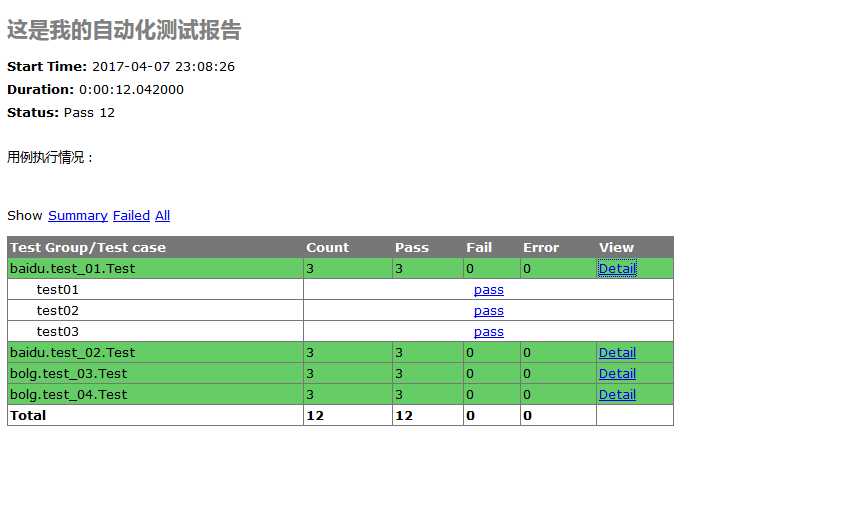
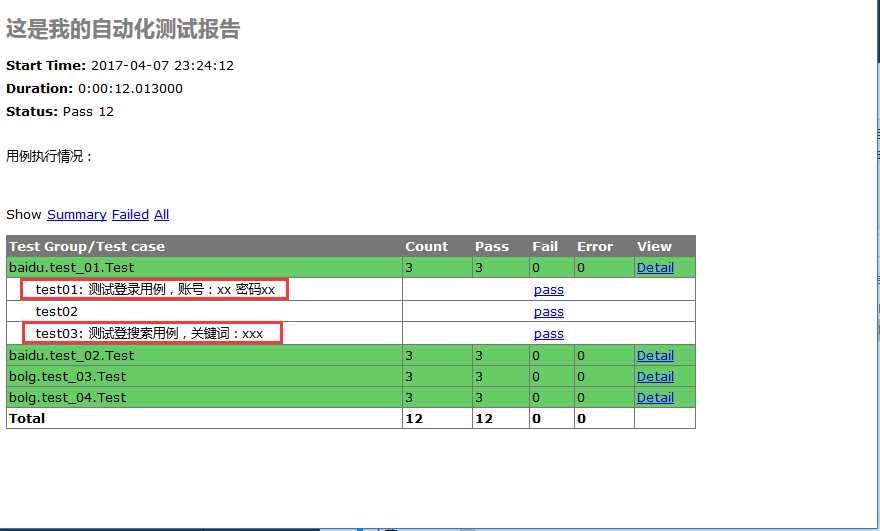
1.找到测试报告文件,用浏览器打开,点开View里的Detail可以查看详情描述。
2.为了生成带中文描述的测试用例,可以在case中添加注释,如在test_01的脚本添加如下注释:
class Test(unittest.TestCase):
def setUp(self):
print "start!"
def tearDown(self):
time.sleep(1)
print "end!"
def test01(self):
u‘‘‘测试登录用例,账号:xx 密码xx‘‘‘
print "执行测试用例01"
def test03(self):
u‘‘‘测试登搜索用例,关键词:xxx‘‘‘
print "执行测试用例03"
3.重新运行后查看测试报告
五、参考代码:
1.我下面的代码文件路径用的相对路径,这样就避免代码换个地址找不到路径的情况了
# coding:utf-8
import unittest
import os
import HTMLTestRunner
# python2.7要是报编码问题,就加这三行,python3不用加
import sys
reload(sys)
sys.setdefaultencoding(‘utf8‘)
# 用例路径
case_path = os.path.join(os.getcwd(), "case")
# 报告存放路径
report_path = os.path.join(os.getcwd(), "report")
def all_case():
discover = unittest.defaultTestLoader.discover(case_path,
pattern="test*.py",
top_level_dir=None)
print(discover)
return discover
if __name__ == "__main__":
# runner = unittest.TextTestRunner()
# runner.run(all_case())
# html报告文件路径
report_abspath = os.path.join(report_path, "result.html")
fp = open(report_abspath, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title=u‘自动化测试报告,测试结果如下:‘,
description=u‘用例执行情况:‘)
# 调用add_case函数返回值
runner.run(all_case())
fp.close()
Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)
标签:dem pre 打开 int 区域 encoding 编码 testcase getcwd
原文地址:https://www.cnblogs.com/jason89/p/8997785.html