有时候从接口的返回值里面获取到的是类似"%u4E0A%u6D77%u60A0%u60A0"这种格式的编码,不是python里面的unicode编码。
python里面的unicode编码应该是这种格式:\u4e0a\u6d77\u60a0\u60a0
unicode编码-python2
1.先看下python的unicode编码:\u60a0,这个是\u开头的,里面的英文是小写
# coding:utf-8
# 前面加u可以直接打印中文
a = u"\u4e0a\u6d77\u60a0\u60a0"
print(a)
# 字符串需decode成默认unicode编码
b = r"\u4e0a\u6d77\u60a0\u60a0"
print(b.decode("unicode_escape"))2.如果在字符串前面加个u,意思是转化成unicode编码,如果获取到的是应该字符串原型,那就需要decode解码成unicode编码,python里面默认的unicode编码名称是unicode_escape
替换%-python2
1.如果是这种带%的编码,先替换成,这样就是unicode编码了,虽然里面的英文字符是大小,还好这里不区分大小写。
# coding:utf-8
c = "%u4E0A%u6D77%u60A0%u60A0"
# 解决办法一:替换%
d = c.replace("%", "\\")
print(d.decode(‘unicode_escape‘))
解决办法二:unichr
1.先切割成单个字符,再用unichr转换成中文,再连成字符串,这个有点复杂了
# coding:utf-8
def switch_to_ch(f):
‘‘‘转换成中文‘‘‘
g = f.split("%u")[1:]
h = [‘‘+unichr(int(i, 16)) for i in g]
return "".join(h)
if __name__ == "__main__":
f = "%u4e0a%u6d77%u60a0%u60a0"
ch = switch_to_ch(f)
print(ch)python3解码
1.python3默认的编码就是unicode,这个跟python2还不太一样,如果直接给字符串decode会报错:AttributeError: ‘str‘ object has no attribute ‘ecode‘
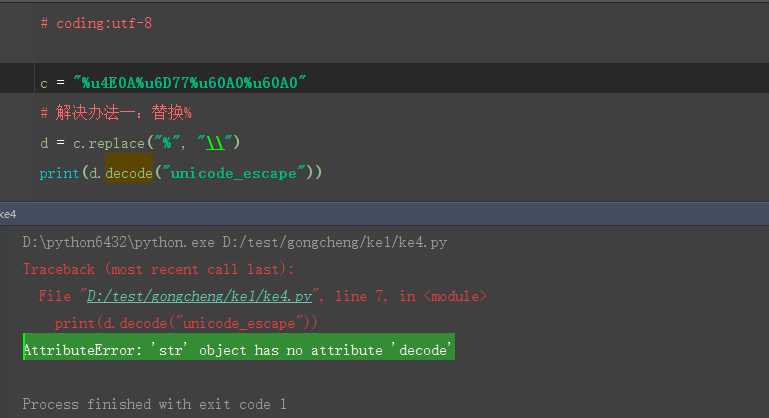
2.python3先encode成utf-8编码,再decode成默认的unicode就可以了
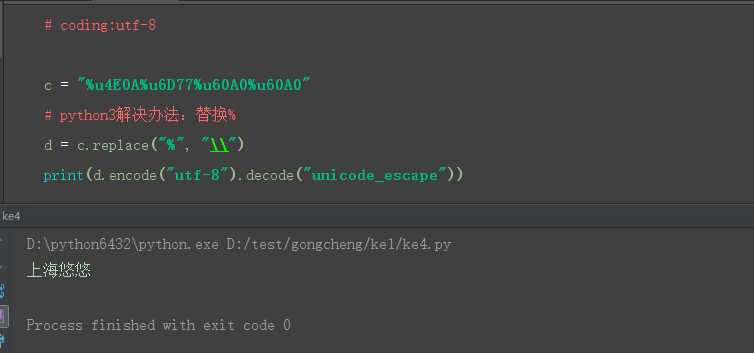
3.代码参考
# coding:utf-8
c = "%u4E0A%u6D77%u60A0%u60A0"
# python3解决办法:替换%
d = c.replace("%", "\\")
print(d.encode("utf-8").decode("unicode_escape"))