标签:学习笔记
日志分析业务中会生成大量的系统日志、应用程序日志、安全日志等,通过对日志的分析可以了解服务器的负载、健康状况,可以分析客户的分布情况、客户的行为,甚至基于这些分析可以做出预测
一般采集流程
日志产出 -> 采集(Logstash、Flume、Scribe)-> 存储 -> 分析 -> 存储(数据库、NoSQL)-> 可视化
通过这些技术就能够把日志中需要的数据提取出来
目标数据形如:
123.125.71.36 - - [06/Apr/2017:18:09:25 +0800] "GET / HTTP/1.1" 200 8642 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
124.```
import datetime
line = ‘‘‘
123.125.71.36 - - [06/Apr/2017:18:09:25 +0800] "GET / HTTP/1.1" 200 8642 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
‘‘‘
CHARS = set(" \t")
def makekey(line: str):
start = 0
skip = False
for i, c in enumerate(line):
if not skip and c in ‘"[‘:
start = i + 1
skip = True
elif skip and c in ‘"]‘:
skip = False
yield line[start:i]
start = i + 1
continue
if skip:
continue
if c in CHARS:
if start == i:
start = i + 1
continue
yield line[start:i]
start = i + 1
else:
if start < len(line):
yield line[start:]
names = (‘remote‘, ‘‘, ‘‘, ‘datetime‘, ‘request‘, ‘status‘, ‘length‘, ‘‘, ‘useragent‘)
ops = (None, None, None, lambda timestr: datetime.datetime.strptime(timestr, ‘%d/%b/%Y:%H:%M:%S %z‘),
lambda request: dict(zip([‘method‘, ‘url‘, ‘protocol‘], request.split())),
int, int, None, None)
def extract(line: str):
return dict(map(lambda item: (item[0], item[2](item[1]) if item[2] is not None else item[1]),
zip(names, makekey(line), ops)))
print(extract(line))PATTERN = r‘‘‘(?P<ip>[\d.]{7,})\s-\s-\s\[(?P<datetime>[^\[\]]+)\]\s"(?P<method>[^"\s]+)\s(?P<url>[^"\s]+)\s(?P<protocol>[^"\s]+)"\s(?P<status>\d{3})\s(?P<size>\d+)\s"(?:.+)"\s"(?P<useragent>[^"]+)"‘‘‘
pattern = re.compile(PATTERN)
ops = {‘datetime‘: (lambda x: datetime.datetime.strptime(x, ‘%d/%b/%Y:%H:%M:%S %z‘)), ‘status‘: int, ‘size‘: int}
def extract(text):
mat = pattern.match(text)
return {k: ops.get(k, lambda x: x)(v) for k, v in mat.groupdict().items()}
PATTERN = r‘‘‘(?P<ip>[\d.]{7,})\s-\s-\s\[(?P<datetime>[^\[\]]+)\]\s"(?P<method>[^"\s]+)\s(?P<url>[^"\s]+)\s(?P<protocol>[^"\s]+)"\s(?P<status>\d{3})\s(?P<size>\d+)\s"(?:.+)"\s"(?P<useragent>[^"]+)"‘‘‘
pattern = re.compile(PATTERN)
ops = {‘datetime‘: (lambda x: datetime.datetime.strptime(x, ‘%d/%b/%Y:%H:%M:%S %z‘)), ‘status‘: int, ‘size‘: int}
def extract(text) -> dict:
mat = pattern.match(text)
if mat:
return {k: ops.get(k, lambda x: x)(v) for k, v in mat.groupdict().items()}
else:
raise Exception(‘No match‘)
def extract(text) -> dict:
mat = pattern.match(text)
if mat:
return {k: ops.get(k, lambda x: x)(v) for k, v in mat.groupdict().items()}
else:
return Nonedef load(path):
with open(path) as f:
for line in f:
fields = extract(line)
if fields:
yield fields
else:
continue产生的数据分析的时候,要按照时间求值
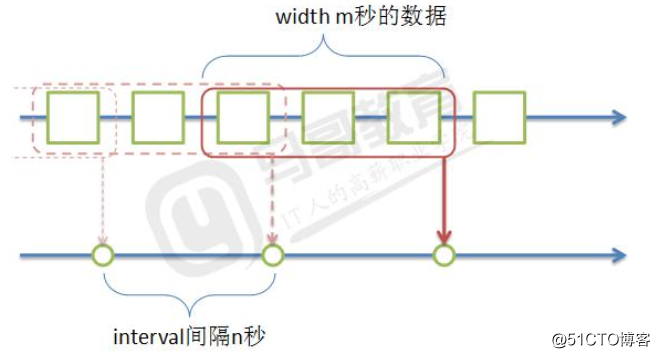
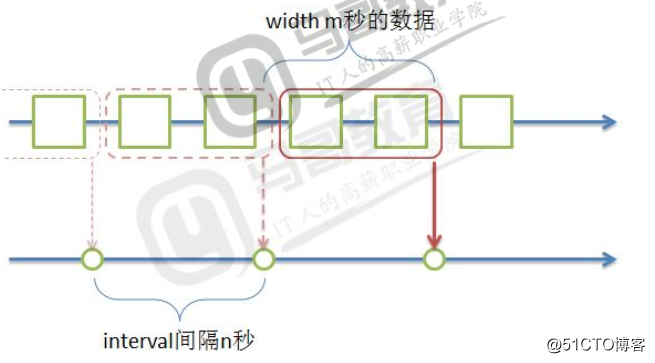
import random
import datetime
import time
def source():
while True:
yield {‘value‘: random.randint(1, 100), ‘datetime‘: datetime.datetime.now()}
time.sleep(1)
s = source()
items = [next(s) for _ in range(3)]
def handler(iterable):
return sum(map(lambda item: item[‘value‘], iterable)) / len(iterable)
print(items)
print("{:.2f}".format(handler(items)))
import random
import datetime
import time
def source(second=1):
while True:
yield {‘value‘: random.randint(1, 100),
‘datetime‘: datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=8)))}
time.sleep(second)
def window(iterator, handler, width: int, interval: int):
start = datetime.datetime.strptime(‘20170101 000000 +0800‘, ‘%Y%m%d %H%M%S %z‘)
current = datetime.datetime.strptime(‘20170101 010000 +0800‘, ‘%Y%m%d %H%M%S %z‘)
buffer = []
delta = datetime.timedelta(seconds=width - interval)
while True:
data = next(iterator)
if data:
buffer.append(data)
current = data[‘datetime‘]
if (current - start).total_seconds() >= interval:
ret = handler(buffer)
print(‘{:.2f}‘.format(ret))
start = current
buffer = [x for x in buffer if x[‘datetime‘] > current - delta]
def handler(iterable):
return sum(map(lambda item: item[‘value‘], iterable)) / len(iterable)
window(source(), handler, 10, 5)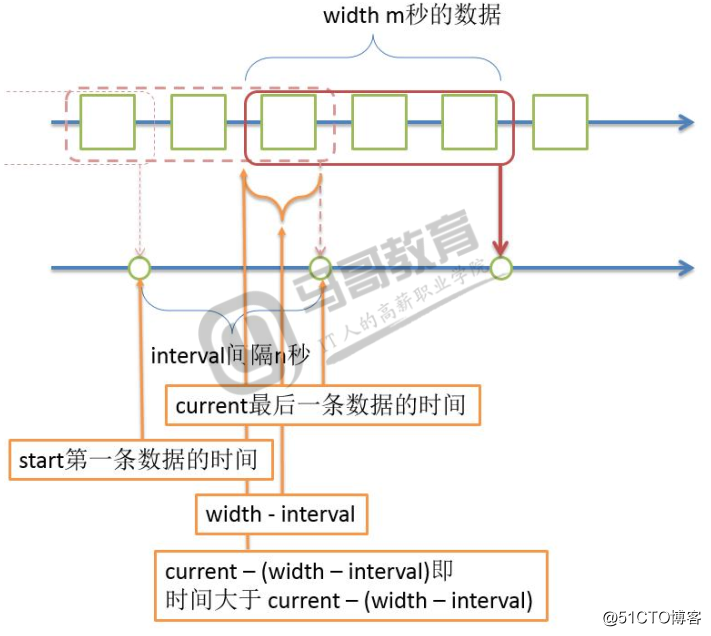
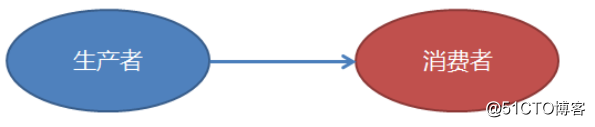
开发的代码耦合高,如果生成规模扩大,不易扩展,生产和消费的速度很难匹配等。
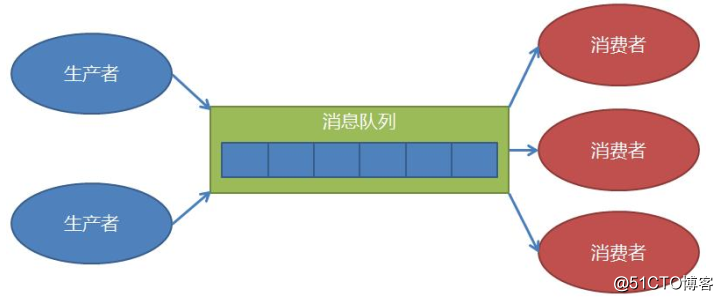
queue.Queue(maxsize=0)
Queue.get(block=True,timeout=None)
Queue.get_nowait()
Queue.put(item,block=True,timeout=None)
生产者(数据源)生产数据,缓冲到消息队列中
数据处理流程:
数据加载 -> 提取 -> 分析(滑动窗口函数)
数据加载 -> 提取 -> 分发 -> 分析函数1&分析函数2
分析1和分析2可以是不同的handler、窗口宽度、间隔时间
暂时采用轮询策略,一对多的副本发送,一个数据通过分发器、发送到多个消费者
消息队列
注册
def dispatcher(src):
reg_handler = []
queues = []
def reg(handler, width, interval):
q = Queue()
queues.append(q)
thrd = threading.Thread(target=window, args=(q, handler, width, interval))
reg_handler.append(thrd)
def run():
for i in reg_handler:
i.start()
for item in src:
for q in queues:
q.put(item)
return reg, run
reg, run = dispatcher(load(‘test.log‘))
reg(handler, 10, 5)
run()import re
from pathlib import Path
import datetime
import time
import threading
from queue import Queue
from user_agents import parse
PATTERN = r‘‘‘(?P<ip>[\d.]{7,})\s-\s-\s\[(?P<datetime>[^\[\]]+)\]\s"(?P<method>[^"\s]+)\s(?P<url>[^"\s]+)\s(?P<protocol>[^"\s]+)"\s(?P<status>\d{3})\s(?P<size>\d+)\s"(?:.+)"\s"(?P<useragent>[^"]+)"‘‘‘
pattern = re.compile(PATTERN)
def extract(text):
ops = {‘datetime‘: (lambda x: datetime.datetime.strptime(x, ‘%d/%b/%Y:%H:%M:%S %z‘)), ‘status‘: int, ‘size‘: int,
‘useragent‘: lambda x: parse(x)}
mat = pattern.match(text)
return {k: ops.get(k, lambda x: x)(v) for k, v in mat.groupdict().items()}
def openfile(filename):
with open(filename) as f:
for text in f:
fields = extract(text)
time.sleep(2)
if fields:
yield fields
else:
continue
# producer
def load(*pathnames):
for path in pathnames:
pathname = Path(path)
if not pathname.exists():
continue
if pathname.is_file():
yield from openfile(pathname)
elif pathname.is_dir():
for filename in pathname.iterdir():
if filename.is_file():
yield from openfile(filename)
def sum_size_handler(iterable):
return sum(map(lambda x: x[‘size‘], iterable))
def status_handler(iterable):
status = {}
for dic in iterable:
key = dic[‘status‘]
status[key] = status.get(key, 0) + 1
return {k: v / len(iterable) for k, v in status.items()}
d = {}
def ua_handler(iterable):
ua_family = {}
for item in iterable:
val = item[‘useragent‘]
key = (val.browser.family, val.browser.version_string)
ua_family[key] = ua_family.get(key, 0) + 1
d[key] = d.get(key, 0) + 1
return ua_family, d
# consumer
def window(q: Queue, handler, width, interval):
st_time = datetime.datetime.strptime(‘19700101 000000 +0800‘, ‘%Y%m%d %H%M%S %z‘)
cur_time = datetime.datetime.strptime(‘19700101 010000 +0800‘, ‘%Y%m%d %H%M%S %z‘)
buffer = []
while True:
# src = next(iterable)
src = q.get()
print(src)
buffer.append(src)
cur_time = src[‘datetime‘]
if (cur_time - st_time).total_seconds() > interval:
val = handler(buffer)
st_time = cur_time
b, d = val
d = sorted(d.items(), key=lambda x: x[1], reverse=True)
print(val)
print(d)
buffer = [x for x in buffer if x[‘datetime‘] > (cur_time - datetime.timedelta(seconds=width - interval))]
def dispatcher(src):
reg_handler = []
queues = []
def reg(handler, width, interval):
q = Queue()
queues.append(q)
thrd = threading.Thread(target=window, args=(q, handler, width, interval))
reg_handler.append(thrd)
def run():
for i in reg_handler:
i.start()
for item in src:
for q in queues:
q.put(item)
return reg, run
if __name__ == ‘__main__‘:
import sys
# path=sys.argv[1]
path = ‘test.log‘
reg, run = dispatcher(load(‘test.log‘))
# reg(sum_size_handler, 20, 5)
# reg(status_handler, 20, 5)
reg(ua_handler, 20, 5)
run()def status_handler(iterable):
status = {}
for dic in iterable:
key = dic[‘status‘]
status[key] = status.get(key, 0) + 1
return {k: v / len(iterable) for k, v in status.items()}浏览器选项中可以修改此设置
pip install pyyaml ua-parser user-agentsd = {}
def ua_handler(iterable):
ua_family = {}
for item in iterable:
val = item[‘useragent‘]
key = (val.browser.family, val.browser.version_string)
ua_family[key] = ua_family.get(key, 0) + 1
d[key] = d.get(key, 0) + 1
return ua_family, d标签:学习笔记
原文地址:http://blog.51cto.com/11281400/2113294