用谷歌浏览器打开链接,右键点击“审查”在控制台切换至network并点击XHR,这样就可以过滤图片、文件等等不必要的请求只看页面内容的请求
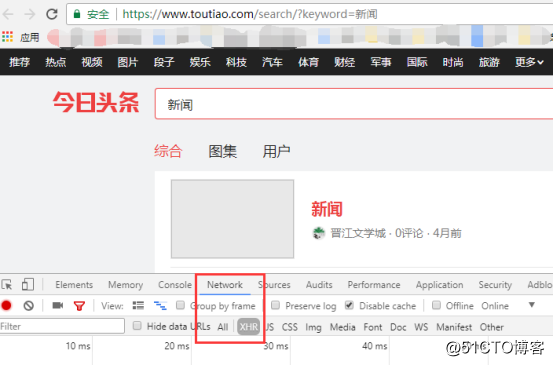
由于页面是ajax加载的,所以将页面拉至最底部,会自动加载出更多文章,这时候控制台抓取到的链接就是我们真正需要的列表页链接:
在蓝天采集中创建一个任务
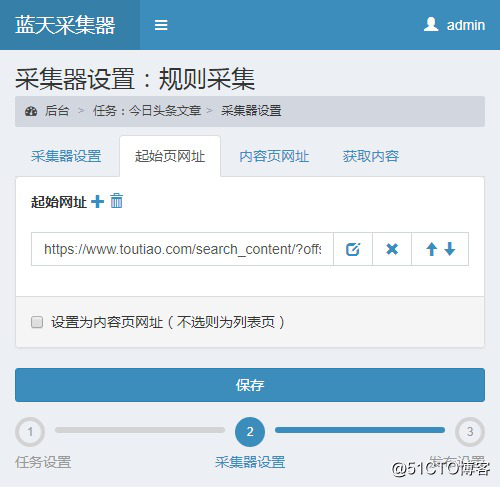
创建完毕点击“采集设置”,在“起始页网址”中填入上面抓取到的链接
接下来匹配内容页网址,头条的文章网址格式是https://www.toutiao.com/group/数字/
点击“内容页网址”编写“匹配内容网址”规则:
(?<content1>http://toutiao.com/group/\d+/)
这是个正则规则,意思就是把匹配的网址装进捕获组content1中,然后在下面填写[内容1] 即对应上面的content1 就可获取到内容页链接
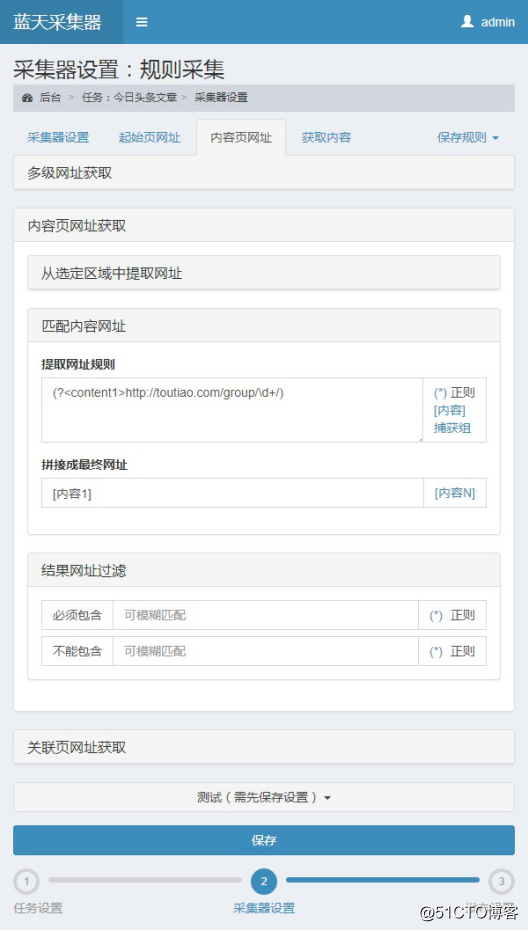
可以点击测试查看是否成功抓取到了链接
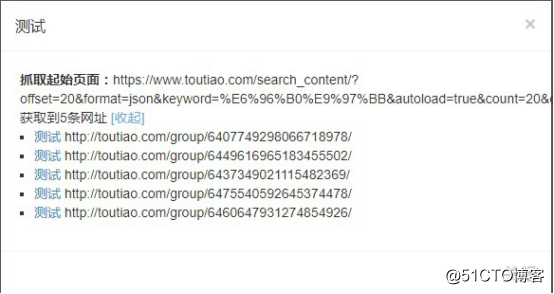
抓取成功就可以开始获取内容了
点击“获取内容”在字段列表右边可以添加默认的字段,如标题、正文等都可以智能识别,如需精准还可以自行编辑字段,支持正则、xpath、json等匹配内容
我们需要抓取文章的标题和正文,由于是ajax显示的所以要写规则匹配出内容,分析篇源码:https://www.toutiao.com/a6358823350874145025/ ,找到文章位置

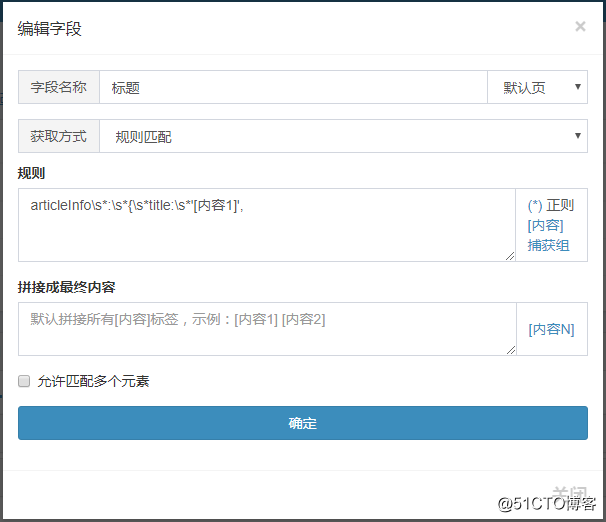
标题规则:articleInfo\s:\s{\stitle:\s‘[内容1]‘,
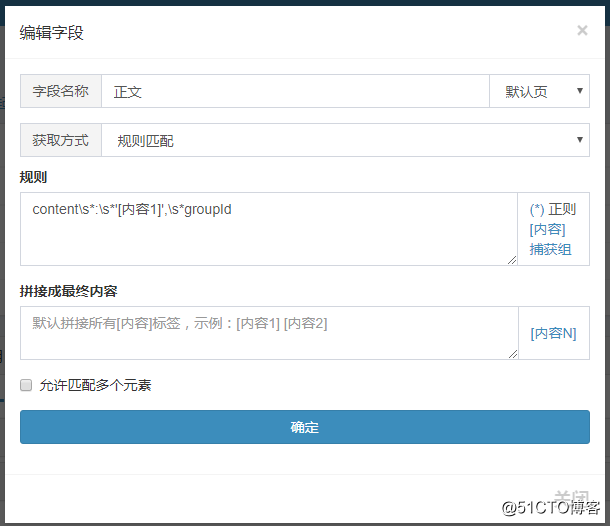
正文规则:content\s:\s‘[内容1]‘,\s*groupId
规则必须保证唯一性,不然会匹配到其他内容上去,将规则添加到字段中,获取方式选规则匹配:
规则编写完后点击保存,点击“测试”看看效果如何
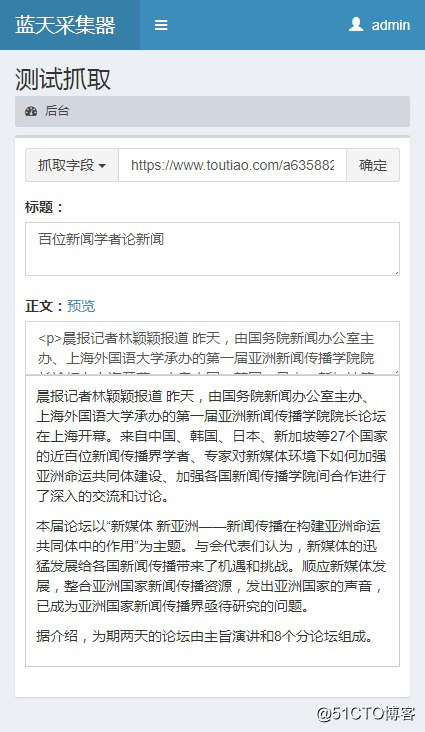
规则无误,抓取正常,抓取到的数据还可以发布到cms系统、直接数据库入库、保存为excel文件等,点击底部导航条的“发布设置”即可,好了今日头条的采集到这里就结束了,大家不妨动手试试!
原文地址:http://blog.51cto.com/10051155/2113774