标签:sub too 2.7 不同 分享图片 turn minus make UNC
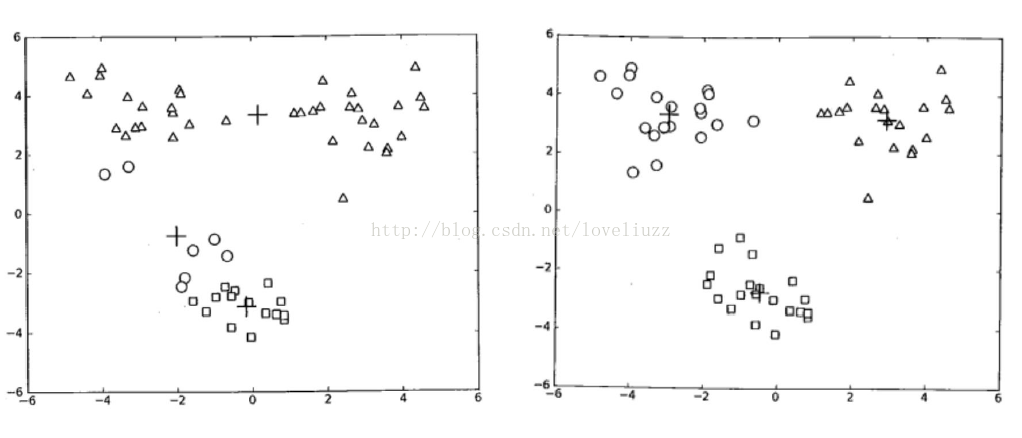
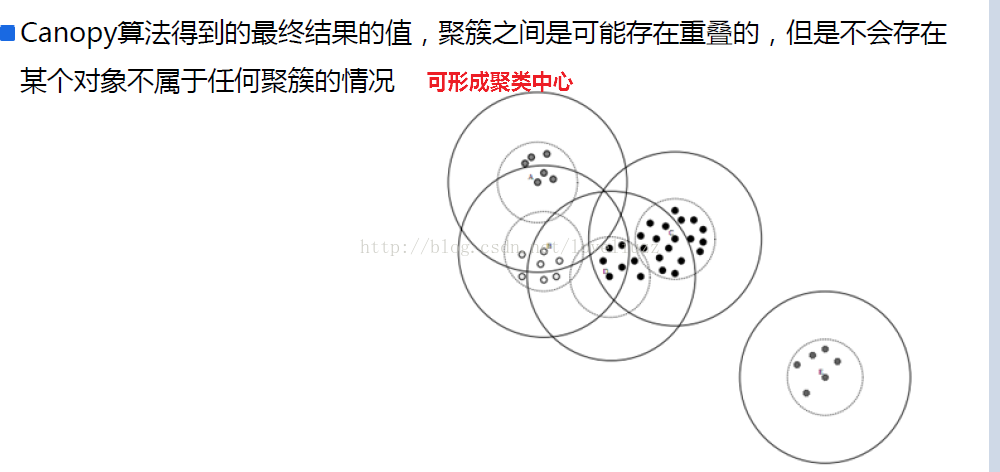
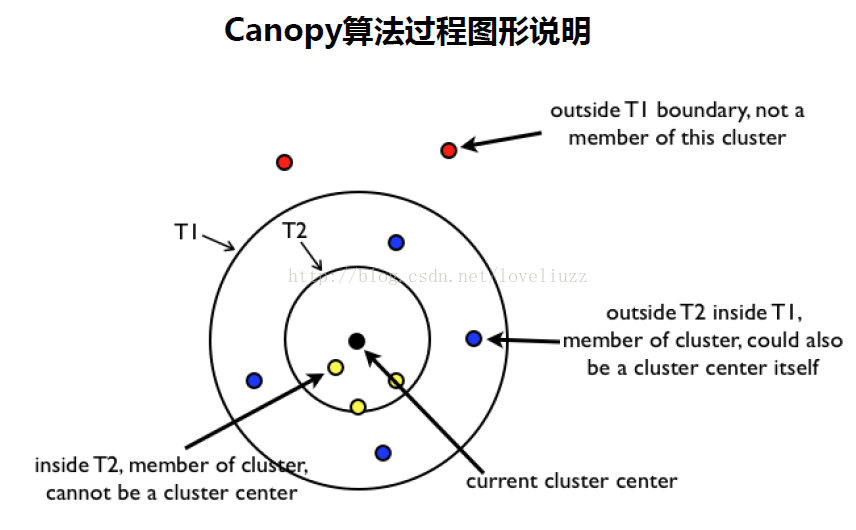
一、关于聚类及相似度、距离的知识点
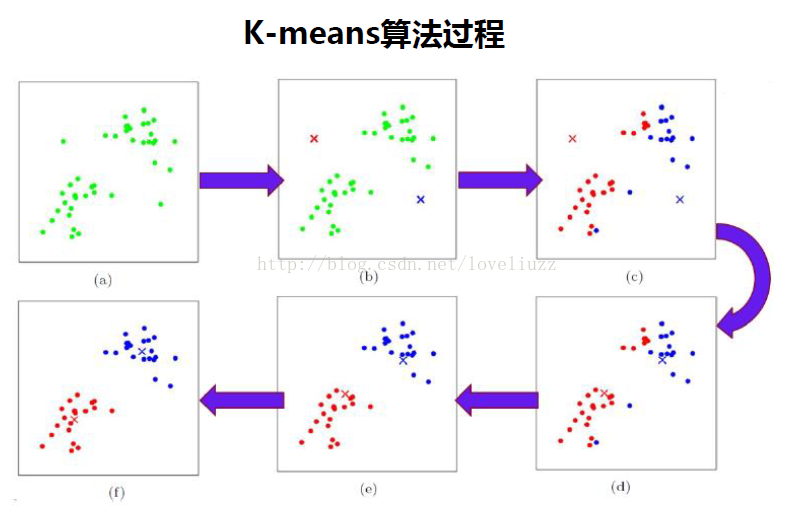
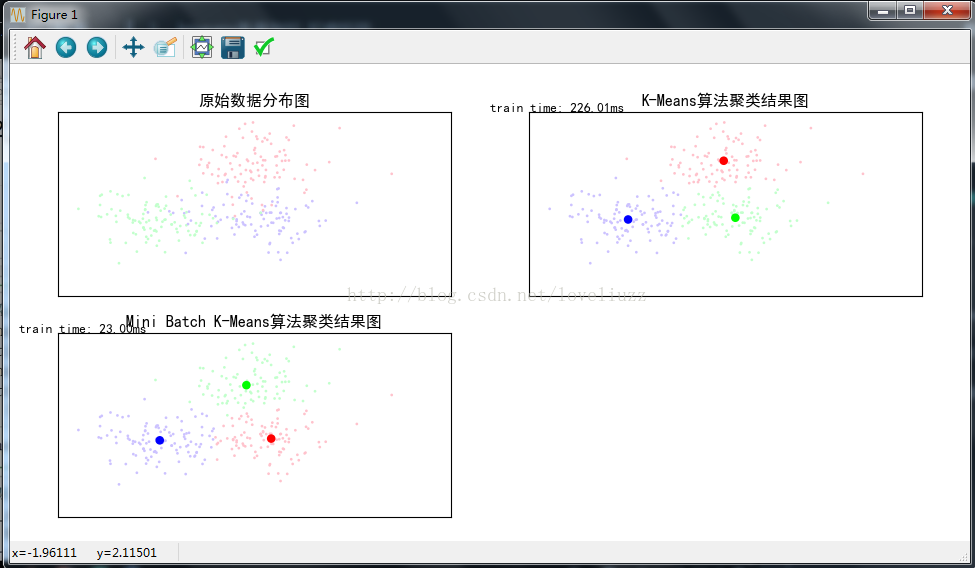
二、k-means算法思想与流程
三、sklearn中对于kmeans算法的参数
四、代码示例以及应用的知识点简介
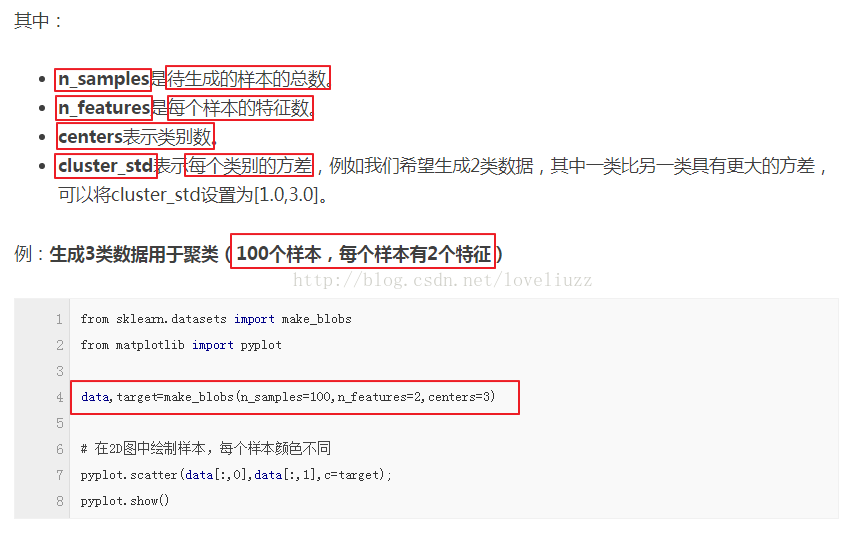
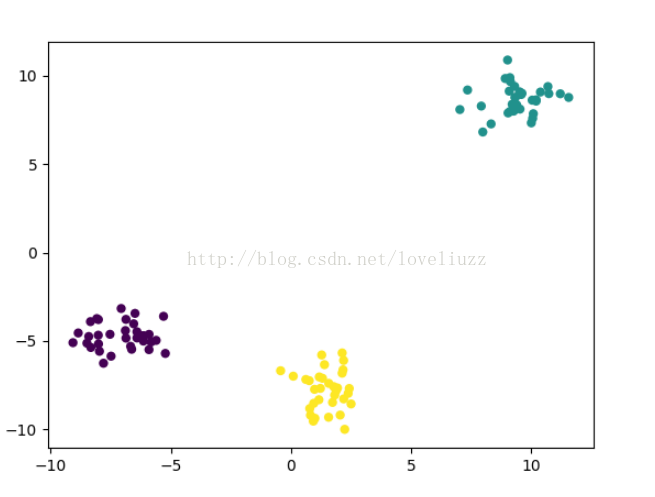
(1)make_blobs:聚类数据生成器
sklearn.datasets.make_blobs(n_samples=100, n_features=2,centers=3, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None)[source]
返回值为:
(2)np.vstack方法作用——堆叠数组
详细介绍参照博客链接:http://blog.csdn.net/csdn15698845876/article/details/73380803
代码中用到的知识点:
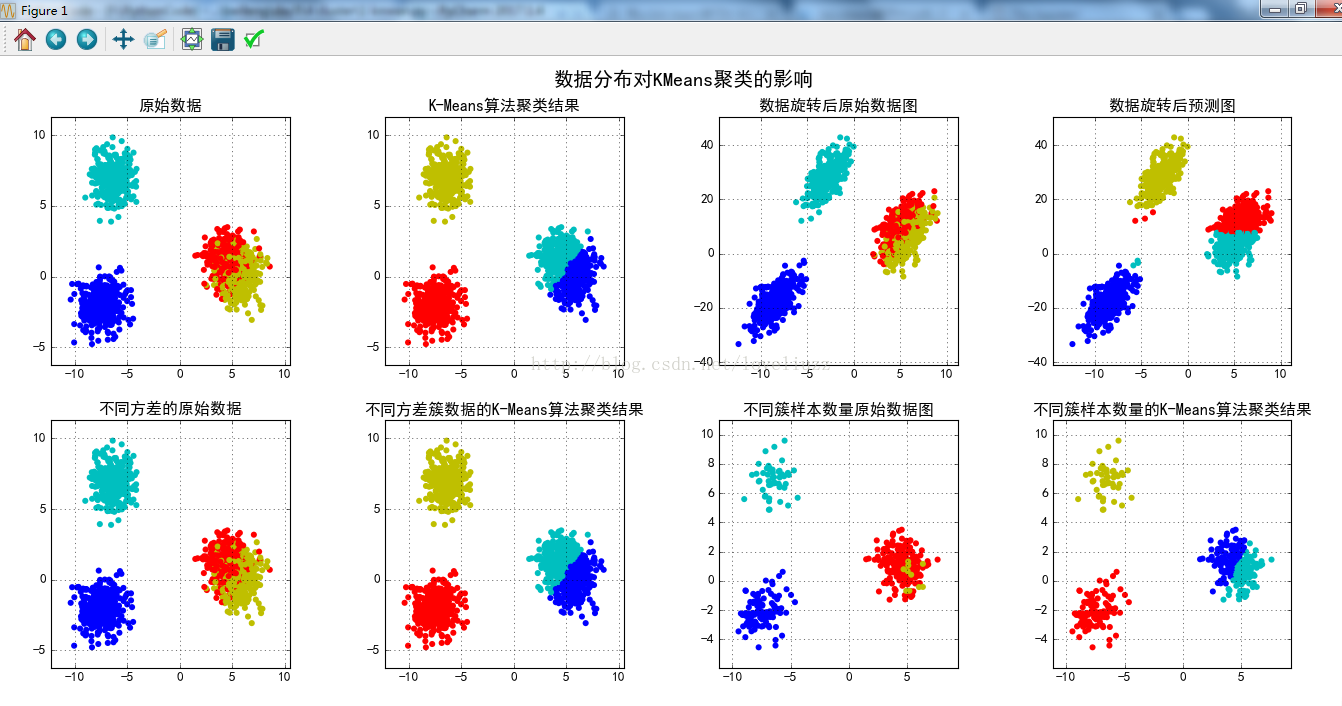
五、聚类算法的衡量指标
标签:sub too 2.7 不同 分享图片 turn minus make UNC
原文地址:https://www.cnblogs.com/mfryf/p/9007524.html