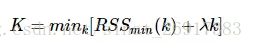标签:batch 源码 函数 评价 img dict machine ati 内容
之前一直用R,现在开始学python之后就来尝试用Python来实现Kmeans。
之前用R来实现kmeans的博客:笔记︱多种常见聚类模型以及分群质量评估(聚类注意事项、使用技巧)
聚类分析在客户细分中极为重要。有三类比较常见的聚类模型,K-mean聚类、层次(系统)聚类、最大期望EM算法。在聚类模型建立过程中,一个比较关键的问题是如何评价聚类结果如何,会用一些指标来评价。
.
scikit-learn 是一个基于Python的Machine Learning模块,里面给出了很多Machine
Learning相关的算法实现,其中就包括K-Means算法。
官网scikit-learn案例地址:http://scikit-learn.org/stable/modules/clustering.html#k-means
部分来自:scikit-learn 源码解读之Kmeans——简单算法复杂的说
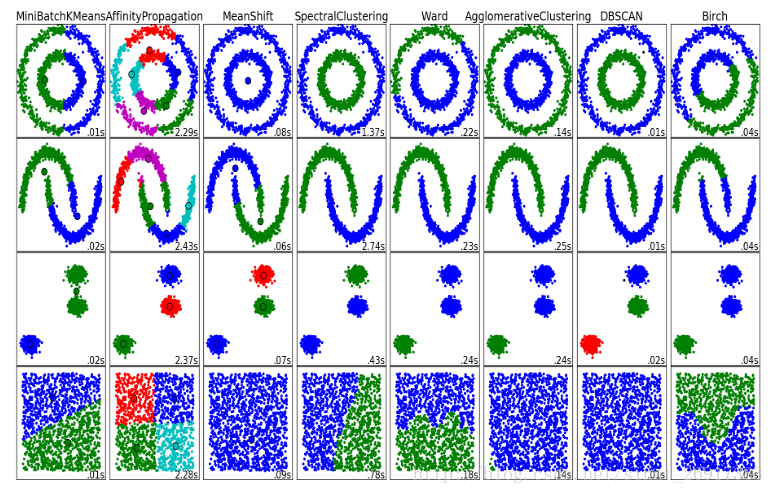
各个聚类的性能对比:
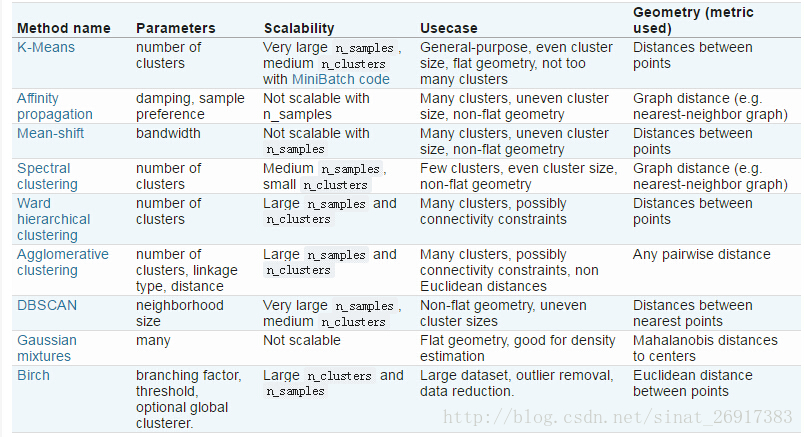
优点:
原理简单
速度快
对大数据集有比较好的伸缩性
缺点:
需要指定聚类 数量K
对异常值敏感
对初始值敏感k-meams算法的能够保证收敛,但不能保证收敛于全局最优点,当初始中心点选取不好时,只能达到局部最优点,整个聚类的效果也会比较差。可以采用以下方法:k-means中心点
选择彼此距离尽可能远的那些点作为中心点;
先采用层次进行初步聚类输出k个簇,以簇的中心点的作为k-means的中心点的输入。
多次随机选择中心点训练k-means,选择效果最好的聚类结果
k-means的误差函数有一个很大缺陷,就是随着簇的个数增加,误差函数趋近于0,最极端的情况是每个记录各为一个单独的簇,此时数据记录的误差为0,但是这样聚类结果并不是我们想要的,可以引入结构风险对模型的复杂度进行惩罚:
λλ是平衡训练误差与簇的个数的参数,但是现在的问题又变成了如何选取λλ了,有研究[参考文献1]指出,在数据集满足高斯分布时,λ=2mλ=2m,其中m是向量的维度。
另一种方法是按递增的顺序尝试不同的k值,同时画出其对应的误差值,通过寻求拐点来找到一个较好的k值,详情见下面的文本聚类的例子。
参考博客:python之sklearn学习笔记
来看看主函数KMeans:
sklearn.cluster.KMeans(n_clusters=8,
init=‘k-means++‘,
n_init=10,
max_iter=300,
tol=0.0001,
precompute_distances=‘auto‘,
verbose=0,
random_state=None,
copy_x=True,
n_jobs=1,
algorithm=‘auto‘
)参数的意义:
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
参考博客:python之sklearn学习笔记
本案例说明了,KMeans分析的一些类如何调取与什么意义。
import numpy as np
from sklearn.cluster import KMeans
data = np.random.rand(100, 3) #生成一个随机数据,样本大小为100, 特征数为3
#假如我要构造一个聚类数为3的聚类器
estimator = KMeans(n_clusters=3)#构造聚类器
estimator.fit(data)#聚类
label_pred = estimator.labels_ #获取聚类标签
centroids = estimator.cluster_centers_ #获取聚类中心
inertia = estimator.inertia_ # 获取聚类准则的总和estimator初始化Kmeans聚类;estimator.fit聚类内容拟合;
estimator.label_聚类标签,这是一种方式,还有一种是predict;estimator.cluster_centers_聚类中心均值向量矩阵
estimator.inertia_代表聚类中心均值向量的总和
案例来源于:使用scikit-learn进行KMeans文本聚类
from sklearn.cluster import KMeans
num_clusters = 3
km_cluster = KMeans(n_clusters=num_clusters, max_iter=300, n_init=40, init=‘k-means++‘,n_jobs=-1)
#返回各自文本的所被分配到的类索引
result = km_cluster.fit_predict(tfidf_matrix)
print "Predicting result: ", resultkm_cluster是KMeans初始化,其中用init的初始值选择算法用’k-means++’;
km_cluster.fit_predict相当于两个动作的合并:km_cluster.fit(data)+km_cluster.predict(data),可以一次性得到聚类预测之后的标签,免去了中间过程。
其中:
km_cluster.labels_
km_cluster.predict(data)这是两种聚类结果标签输出的方式,结果貌似都一样。都需要先km_cluster.fit(data),然后再调用。
Kmeans算法之后的一些分析,参考来源:用Python实现文档聚类
from sklearn.cluster import KMeans
num_clusters = 5
km = KMeans(n_clusters=num_clusters)
%time km.fit(tfidf_matrix)
clusters = km.labels_.tolist()分为五类,同时用%time来测定运行时间,把分类标签labels格式变为list。
from sklearn.externals import joblib
# 注释语句用来存储你的模型
joblib.dump(km, ‘doc_cluster.pkl‘)
km = joblib.load(‘doc_cluster.pkl‘)
clusters = km.labels_.tolist()frame = pd.DataFrame(films, index = [clusters] , columns = [‘rank‘, ‘title‘, ‘cluster‘, ‘genre‘])
frame[‘cluster‘].value_counts()选择更靠近质心的点,其中 km.cluster_centers_代表着一个 (聚类个数*维度数),也就是不同聚类、不同维度的均值。
该指标可以知道:
一个类别之中的,那些点更靠近质心;
整个类别组内平方和。
类别内的组内平方和要参考以下公式: 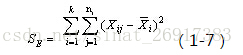
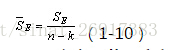
通过公式可以看出:
质心均值向量每一行数值-每一行均值(相当于均值的均值)
注意是平方。其中,n代表样本量,k是聚类数量(譬如聚类5)
其中,整篇的组内平方和可以通过来获得总量:
km.inertia_k-means+python︱scikit-learn中的KMeans聚类实现( + MiniBatchKMeans)
标签:batch 源码 函数 评价 img dict machine ati 内容
原文地址:https://www.cnblogs.com/mfryf/p/9007530.html