标签:integer 依次 class 实现 长度 fbo except shm dHash
查阅API,看List的介绍。有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。与 set 不同,列表通常允许重复的元素。
List接口:
它是一个元素存取有序的集合。例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)。
它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
List接口常用的子类有:ArrayList集合、LinkedList集合
public static void main(String[] args) { //add(); //delete(); //update(); //get(); edit(); } /* * void add(int index,E element) *在指定位置添加元素 * java.lang.IndexOutOfBoundsException集合的越界异常 * java.lang.ArrayIndexOutOfBoundsException数组的越界异常 * java.lang.StringIndexOutOfBoundsException 字符串越界异常 * */ public static void add() { List<String> list=new ArrayList<String>(); list.add("abc"); list.add("456"); list.add("bcd"); list.add(3, "rrr"); System.out.println(list); } /* * E remove(int index) * 1.删除指定位置上的元素 * 2.返回这个元素的值 * */ public static void delete() { List<String> list=new ArrayList<String>(); list.add("abc"); list.add("456"); list.add("bcd"); list.add(3, "rrr"); System.out.println(list); String element=list.remove(0); System.out.println(element); System.out.println(list); } /* *E set(int index,E element) *1.替换指定位置上的值 *2.还可以获取替换以前的值 * */ public static void update() { List<String> list=new ArrayList<String>(); list.add("abc"); list.add("456"); list.add("bcd"); System.out.println(list); String e=list.set(1, "吴彦祖"); System.out.println(e); System.out.println(list); } /* * E get(int index) * 获取指定索引上的元素值 * */ public static void get() { List<String> list=new ArrayList<String>(); list.add("abc"); list.add("456"); list.add("bcd"); System.out.println(list); System.out.println(list.get(0)); for(int i=0;i<list.size();i++) { System.out.println(list.get(i)); } }
/* * Iterator并发修改异常 * 在遍历的过程中,只能做不改变长度的事情 * 一旦做了改变长度的事情,就会出现并发修改异常 * */ public static void edit() { List<String> list=new ArrayList<String>(); list.add("abc"); list.add("456"); list.add("bcd"); Iterator<String> it=list.iterator(); while(it.hasNext()) { String str=it.next(); System.out.println(str); if(str.equals("456")) { int i=list.indexOf(str); list.set(i, "吴彦祖"); } System.out.println(str); }
List接口下有很多个集合,它们存储元素所采用的结构方式是不同的,这样就导致了这些集合有它们各自的特点,供给我们在不同的环境下进行使用。数据存储的常用结构有:堆栈、队列、数组、链表。
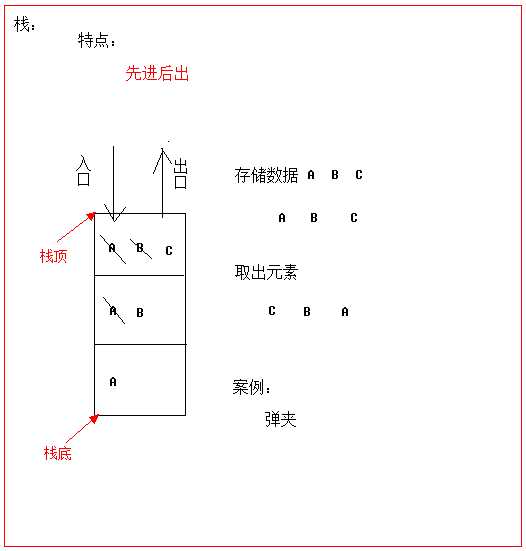
先进后出(即,存进去的元素,要在后它后面的元素依次取出后,才能取出该元素)。例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
栈的入口、出口的都是栈的顶端位置。
压栈:就是存元素。即把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,安检。排成一列,每个人依次检查,只有前面的人全部检查完毕后,才能排到当前的人进行检查。
队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口。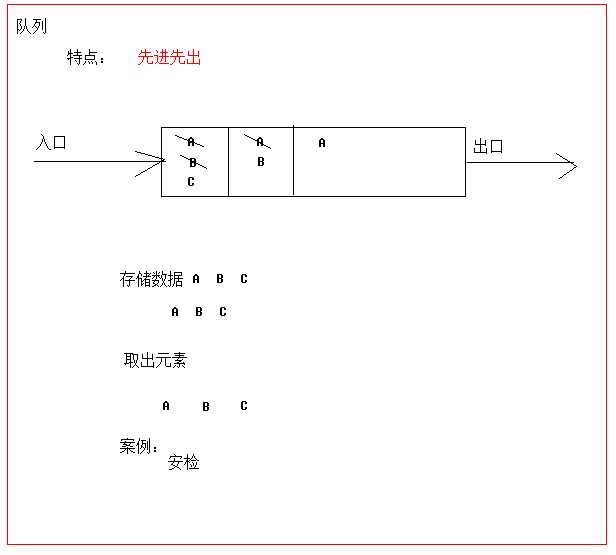
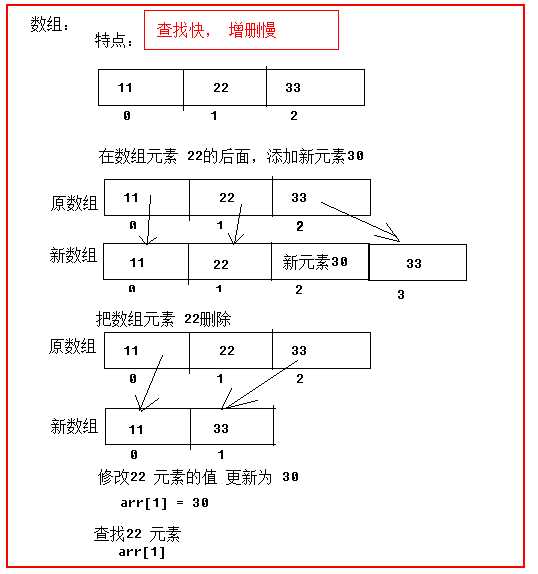
查找元素快:通过索引,可以快速访问指定位置的元素
增删元素慢:
指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。如下图
指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。
多个节点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。
查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
增删元素快:
增加元素:操作如左图,只需要修改连接下个元素的地址即可。
删除元素:操作如右图,只需要修改连接下个元素的地址即可。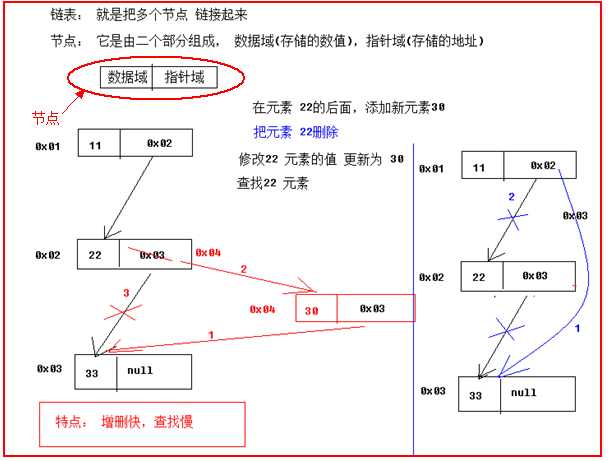
ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。下面是LinkedList的常用方法
public static void main(String[] args) { //add(); get(); } /* * void addFirst(E e)将指定元素插入此列表的开头 * coid addLast(E e)将指定元素插入此列表的结尾 * * */ public static void add() { LinkedList<String> list=new LinkedList<String>(); list.addLast("程、陈冠希"); list.add("吴彦祖"); list.addFirst("梁朝伟"); System.out.println(list); } /* * E getFirst() 返回此列表的第一个元素 * E getLast()返回此列表的最后一个元素 * java.util.NoSuchElementException * * */ public static void get() { LinkedList<String> list=new LinkedList<String>(); list.addLast("程、陈冠希"); list.add("吴彦祖"); list.addFirst("梁朝伟"); String f=list.getFirst(); String l=list.getLast(); System.out.println(f+l); } }
Vector集合数据存储的结构是数组结构,为JDK中最早提供的集合。Vector中提供了一个独特的取出方式,就是枚举Enumeration,它其实就是早期的迭代器。此接口Enumeration的功能与 Iterator 接口的功能是类似的。Vector集合已被ArrayList替代。
Vector集合与ArrayList集合使用的对比:

List和Set十Collection的两个子接口,前面我们知道List中可以存放重复元素。而Set接口里边的集合存储的是不重复的元素。通过查阅Set集合的API知道Set集合判断元素是否重复是通过equals方法来判断的。
查阅HashSet集合的API介绍:此类实现Set接口,由哈希表支持(实际上是一个 HashMap集合)。HashSet集合不能保证的迭代顺序与元素存储顺序相同。HashSet集合,采用哈希表结构存储数据,保证元素唯一性的方式依赖于:hashCode()与equals()方法。
什么是哈希表呢?
哈希表底层使用的也是数组机制,数组中也存放对象,而这些对象往数组中存放时的位置比较特殊,当需要把这些对象给数组中存放时,那么会根据这些对象的特有数据结合相应的算法,计算出这个对象在数组中的位置,然后把这个对象存放在数组中。而这样的数组就称为哈希数组,即就是哈希表。
当向哈希表中存放元素时,需要根据元素的特有数据结合相应的算法,这个算法其实就是Object类中的hashCode方法。由于任何对象都是Object类的子类,所以任何对象有拥有这个方法。即就是在给哈希表中存放对象时,会调用对象的hashCode方法,算出对象在表中的存放位置,这里需要注意,如果两个对象hashCode方法算出结果一样,这样现象称为哈希冲突,这时会调用对象的equals方法,比较这两个对象是不是同一个对象,如果equals方法返回的是true,那么就不会把第二个对象存放在哈希表中,如果返回的是false,就会把这个值存放在哈希表中。
import java.util.HashSet; /* * 1.计算存储对象的哈希值,然后比较集合中有没有相同的哈希值 * 2.如果有相同的哈希值,再调用equals方法,"aab".equals("aab"),如果相同 * 返回true,判定这是个重复元素,丢掉 * 3.如果哈希值相同,则调用equals方法,如果euqals返回false,存入Set * * */ public class HashSetDemo { public static void main(String[] args) { method(); } public static void method() { HashSet<Person> hs=new HashSet<Person>(); Person p1=new Person("a",12); Person p2=new Person("b",11); Person p3=new Person("b",11); Person p4=new Person("d",12); System.out.println(p1.hashCode()); System.out.println(p2.hashCode()); System.out.println(p3.hashCode()); hs.add(p1); hs.add(p2); hs.add(p3); hs.add(p4); System.out.println(hs); } public static void hash() { HashSet<String> hs=new HashSet<String>(); hs.add("aab"); hs.add("aab"); hs.add("bbc"); hs.add("bbc"); System.out.println(hs); } }
给HashSet中存储JavaAPI中提供的类型元素时,不需要重写元素的hashCode和equals方法,因为这两个方法,在JavaAPI的每个类中已经重写完毕,如String类、Integer类等。
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一。
在HashSet下面有一个子类LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。它和HashSet的区别就是LinkedHashSet集合保证元素的存入和取出的顺序。
标签:integer 依次 class 实现 长度 fbo except shm dHash
原文地址:https://www.cnblogs.com/boringLee/p/9018941.html