标签:blog http io os 使用 ar strong 文件 数据
1:备份常用工具:
mysqldump, xtrabackup
mysqldump: 原生数据导出工具,以sql的形式导出保存
xtrabackup: percona团队提供的备份工具,基于文件系统的备份
2:备份全库:
mysqldump -h10.6.29.1 -uroot -p --all-databases > 20140925_all_db_10.6.29.1.sql
mysqldump是直接屏幕输出,所以重定向后即可得到对应的备份文件。 存在问题: 1:会锁全库,影响业务 2:有可能缺失常规表以外的内容,如存储过程 3:未记录binlog同步点,不能用于主从同步以及利用binlog增量恢复 4:对于数据集较大的表,可能会吃掉server端大量内存
mysqldump -h10.6.29.1 -uroot -p --all-databases --master-data=2 --routines --events --quick --single-transaction > 10.6.29.129.sql
--master-data=2 表示需要记录导出数据当时主库的binlog位置 --routines 表示导出存储过程(可视实际库表决定是否使用) --events 表示导出事件(可根据实际库表决定是否使用) --quick 表示让服务端不将结果集一次发送,而是分批发送,可减轻压力 另外,加上--master-data后默认是锁库的,可确保数据一致性,即导出数据和binlog位置的一致。 --single-transaction 取消锁库并利用Innodb事务特性确保数据一致,但对MyISAM引擎不能确保一致性(即备份期间的写入,仍有可能被导出到备份文件中)
3:备份部分库
mysqldump -h10.6.29.129 -uroot -p --master-data=2 --routines –events --quick --single-transaction --databases db1 db2 db3 > 20140925_all_db_10.6.29.1.sql (将需要导出的库名,依次填写在databases参数后) 备份指定database的部分表—— mysqldump -h10.6.29.129 -uroot –p --master-data=2 --routines –events --quick --single-transaction mydb table1 table2 >20140925_all_db_10.6.29.129.sql
(先写明指定的database,然后紧跟需要备份的表名)
4:数据恢复
Mysql -h10.6.29.129 -uroot -p < 20140925_all_db_10.6.29.129.sql (简单易行,但要确保导入的库表,不会同时有业务在写入)
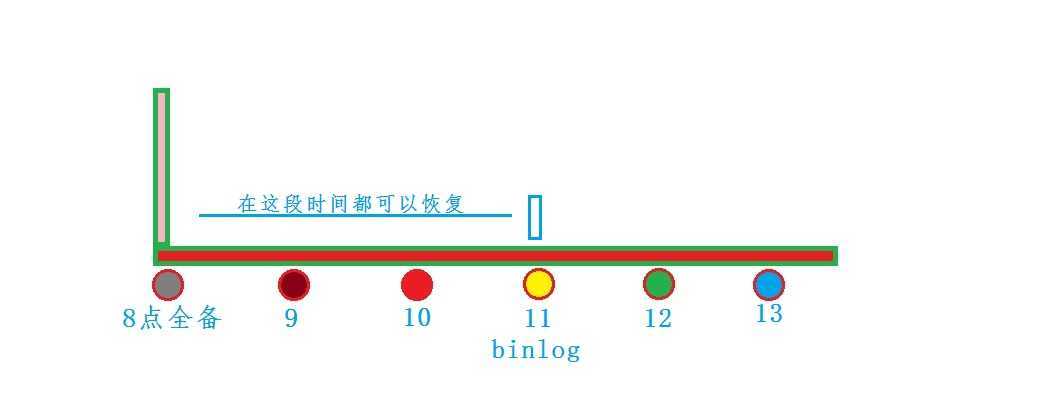
5:mysqlbinlog对日志进行解析
mysqlbinlog mysql.000002 > binlog_new.000002
mysqlbinlog mysql.000002 --start-position=549212174 --stop-datetime=‘2014-9-10 10:00‘ > binlog_new.000002.sql
--start-position 表示从binlog的那个位置开始解析,而这个起始点可以通过备份时的master-data参数得到 --stop-datetime 表示只解析到哪个时间点的语句为止,可用于回档到某个指定时间点 --start-datetime 从那个时间点开始,但通常还是尽量使用start-position,更为准确 --verbose, -v 使用方式:-vv, -vvv,常用于ROW模式的详细输出
mysqlbinlog mysql.000005 > 5.sql mysqlbinlog mysql.000005 -vv > 5-vv.sql
6:恢复单个表
1:拥有对应单表备份文件,直接导入 2:使用mysqlbinlog解析binlog文件,再从得到的完整文件中获取对应表的语句,redo应用到数据库
如何过滤仅得到想要的语句? 由于binlog里得到的语句数量通常相当庞大,可以借助最简单的grep的方式。 grep -B3 -w tbl1 binlog.xxx.sql | egrep -v ‘^--$‘ > tbl1.sql
标签:blog http io os 使用 ar strong 文件 数据
原文地址:http://www.cnblogs.com/xiaoit/p/3993989.html