标签:sample 数值 thml 个数 jobs auc 设定 account 现在
https://blog.csdn.net/han_xiaoyang/article/details/52665396
转:
原文地址:Complete Guide to Parameter Tuning in XGBoost by Aarshay Jain
原文翻译与校对:@MOLLY && 寒小阳 (hanxiaoyang.ml@gmail.com)
时间:2016年9月。
出处:http://blog.csdn.net/han_xiaoyang/article/details/52665396
声明:版权所有,转载请联系作者并注明出
如果你的预测模型表现得有些不尽如人意,那就用XGBoost吧。XGBoost算法现在已经成为很多数据工程师的重要武器。它是一种十分精致的算法,可以处理各种不规则的数据。
构造一个使用XGBoost的模型十分简单。但是,提高这个模型的表现就有些困难(至少我觉得十分纠结)。这个算法使用了好几个参数。所以为了提高模型的表现,参数的调整十分必要。在解决实际问题的时候,有些问题是很难回答的——你需要调整哪些参数?这些参数要调到什么值,才能达到理想的输出?
这篇文章最适合刚刚接触XGBoost的人阅读。在这篇文章中,我们会学到参数调优的技巧,以及XGboost相关的一些有用的知识。以及,我们会用Python在一个数据集上实践一下这个算法。
XGBoost(eXtreme Gradient Boosting)是Gradient Boosting算法的一个优化的版本。因为我在前一篇文章,基于Python的Gradient Boosting算法参数调整完全指南,里面已经涵盖了Gradient Boosting算法的很多细节了。我强烈建议大家在读本篇文章之前,把那篇文章好好读一遍。它会帮助你对Boosting算法有一个宏观的理解,同时也会对GBM的参数调整有更好的体会。
特别鸣谢:我个人十分感谢Mr Sudalai Rajkumar (aka SRK)大神的支持,目前他在AV Rank中位列第二。如果没有他的帮助,就没有这篇文章。在他的帮助下,我们才能给无数的数据科学家指点迷津。给他一个大大的赞!
1、XGBoost的优势
2、理解XGBoost的参数
3、调参示例
XGBoost算法可以给预测模型带来能力的提升。当我对它的表现有更多了解的时候,当我对它的高准确率背后的原理有更多了解的时候,我发现它具有很多优势:
相信你已经对XGBoost强大的功能有了点概念。注意这是我自己总结出来的几点,你如果有更多的想法,尽管在下面评论指出,我会更新这个列表的!
你的胃口被我吊起来了吗?棒棒哒!如果你想更深入了解相关信息,可以参考下面这些文章:
XGBoost Guide - Introduce to Boosted Trees
Words from the Auther of XGBoost [Viedo]
XGBoost的作者把所有的参数分成了三类:
在这里我会类比GBM来讲解,所以作为一种基础知识,强烈推荐先阅读这篇文章。
这些参数用来控制XGBoost的宏观功能。
还有两个参数,XGBoost会自动设置,目前你不用管它。接下来咱们一起看booster参数。
尽管有两种booster可供选择,我这里只介绍tree booster,因为它的表现远远胜过linear booster,所以linear booster很少用到。
这个参数用来控制理想的优化目标和每一步结果的度量方法。
如果你之前用的是Scikit-learn,你可能不太熟悉这些参数。但是有个好消息,python的XGBoost模块有一个sklearn包,XGBClassifier。这个包中的参数是按sklearn风格命名的。会改变的函数名是:
1、eta -> learning_rate
2、lambda -> reg_lambda
3、alpha -> reg_alpha
你肯定在疑惑为啥咱们没有介绍和GBM中的n_estimators类似的参数。XGBClassifier中确实有一个类似的参数,但是,是在标准XGBoost实现中调用拟合函数时,把它作为num_boosting_rounds参数传入。
XGBoost Guide 的一些部分是我强烈推荐大家阅读的,通过它可以对代码和参数有一个更好的了解:
XGBoost Parameters (official guide)
XGBoost Demo Codes (xgboost GitHub repository)
Python API Reference (official guide)
我们从Data Hackathon 3.x AV版的hackathon中获得数据集,和GBM 介绍文章中是一样的。更多的细节可以参考competition page
数据集可以从这里下载。我已经对这些数据进行了一些处理:
City变量,因为类别太多,所以删掉了一些类别。DOB变量换算成年龄,并删除了一些数据。EMI_Loan_Submitted_Missing 变量。如果EMI_Loan_Submitted变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的EMI_Loan_Submitted变量。EmployerName变量,因为类别太多,所以删掉了一些类别。Existing_EMI变量只有111个值缺失,所以缺失值补充为中位数0。Interest_Rate_Missing 变量。如果Interest_Rate变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的Interest_Rate变量。Lead_Creation_Date,从直觉上这个特征就对最终结果没什么帮助。Loan_Amount_Applied, Loan_Tenure_Applied 两个变量的缺项用中位数补足。Loan_Amount_Submitted_Missing 变量。如果Loan_Amount_Submitted变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的Loan_Amount_Submitted变量。Loan_Tenure_Submitted_Missing 变量。如果 Loan_Tenure_Submitted 变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的 Loan_Tenure_Submitted 变量。LoggedIn, Salary_Account 两个变量Processing_Fee_Missing 变量。如果 Processing_Fee 变量的数据缺失,则这个参数的值为1。否则为0。删除了原先的 Processing_Fee 变量。Source前两位不变,其它分成不同的类别。如果你有原始数据,可以从资源库里面下载data_preparation的Ipython notebook 文件,然后自己过一遍这些步骤。
首先,import必要的库,然后加载数据。
#Import libraries:
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn import cross_validation, metrics #Additional scklearn functions
from sklearn.grid_search import GridSearchCV #Perforing grid search
import matplotlib.pylab as plt
%matplotlib inline
from matplotlib.pylab import rcParams
rcParams[‘figure.figsize‘] = 12, 4
train = pd.read_csv(‘train_modified.csv‘)
target = ‘Disbursed‘
IDcol = ‘ID‘注意我import了两种XGBoost:
在向下进行之前,我们先定义一个函数,它可以帮助我们建立XGBoost models 并进行交叉验证。好消息是你可以直接用下面的函数,以后再自己的models中也可以使用它。
def modelfit(alg, dtrain, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
if useTrainCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()[‘n_estimators‘], nfold=cv_folds,
metrics=‘auc‘, early_stopping_rounds=early_stopping_rounds, show_progress=False)
alg.set_params(n_estimators=cvresult.shape[0])
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain[‘Disbursed‘],eval_metric=‘auc‘)
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#Print model report:
print "\nModel Report"
print "Accuracy : %.4g" % metrics.accuracy_score(dtrain[‘Disbursed‘].values, dtrain_predictions)
print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain[‘Disbursed‘], dtrain_predprob)
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind=‘bar‘, title=‘Feature Importances‘)
plt.ylabel(‘Feature Importance Score‘)这个函数和GBM中使用的有些许不同。不过本文章的重点是讲解重要的概念,而不是写代码。如果哪里有不理解的地方,请在下面评论,不要有压力。注意xgboost的sklearn包没有“feature_importance”这个量度,但是get_fscore()函数有相同的功能。
我们会使用和GBM中相似的方法。需要进行如下步骤:
选择较高的学习速率(learning rate)。一般情况下,学习速率的值为0.1。但是,对于不同的问题,理想的学习速率有时候会在0.05到0.3之间波动。选择对应于此学习速率的理想决策树数量。XGBoost有一个很有用的函数“cv”,这个函数可以在每一次迭代中使用交叉验证,并返回理想的决策树数量。
对于给定的学习速率和决策树数量,进行决策树特定参数调优(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。在确定一棵树的过程中,我们可以选择不同的参数,待会儿我会举例说明。
xgboost的正则化参数的调优。(lambda, alpha)。这些参数可以降低模型的复杂度,从而提高模型的表现。
降低学习速率,确定理想参数。
咱们一起详细地一步步进行这些操作。
为了确定boosting参数,我们要先给其它参数一个初始值。咱们先按如下方法取值:
1、max_depth = 5 :这个参数的取值最好在3-10之间。我选的起始值为5,但是你也可以选择其它的值。起始值在4-6之间都是不错的选择。
2、min_child_weight = 1:在这里选了一个比较小的值,因为这是一个极不平衡的分类问题。因此,某些叶子节点下的值会比较小。
3、gamma = 0: 起始值也可以选其它比较小的值,在0.1到0.2之间就可以。这个参数后继也是要调整的。
4、subsample, colsample_bytree = 0.8: 这个是最常见的初始值了。典型值的范围在0.5-0.9之间。
5、scale_pos_weight = 1: 这个值是因为类别十分不平衡。
注意哦,上面这些参数的值只是一个初始的估计值,后继需要调优。这里把学习速率就设成默认的0.1。然后用xgboost中的cv函数来确定最佳的决策树数量。前文中的函数可以完成这个工作。
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target,IDcol]]
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= ‘binary:logistic‘,
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb1, train, predictors)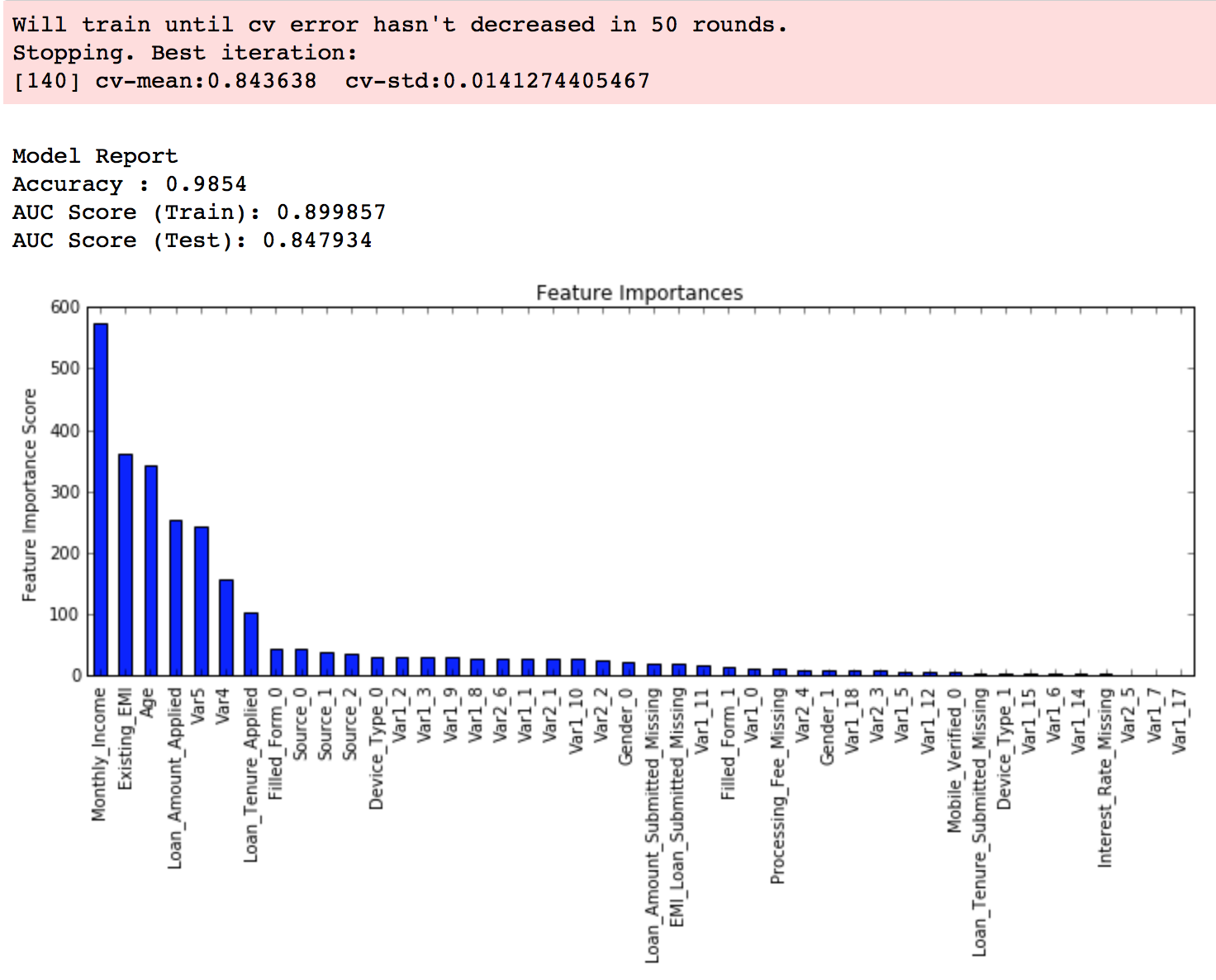
从输出结果可以看出,在学习速率为0.1时,理想的决策树数目是140。这个数字对你而言可能比较高,当然这也取决于你的系统的性能。
注意:在AUC(test)这里你可以看到测试集的AUC值。但是如果你在自己的系统上运行这些命令,并不会出现这个值。因为数据并不公开。这里提供的值仅供参考。生成这个值的代码部分已经被删掉了。
我们先对这两个参数调优,是因为它们对最终结果有很大的影响。首先,我们先大范围地粗调参数,然后再小范围地微调。
注意:在这一节我会进行高负荷的栅格搜索(grid search),这个过程大约需要15-30分钟甚至更久,具体取决于你系统的性能。你也可以根据自己系统的性能选择不同的值。
param_test1 = {
‘max_depth‘:range(3,10,2),
‘min_child_weight‘:range(1,6,2)
}
gsearch1 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=140, max_depth=5,
min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= ‘binary:logistic‘, nthread=4, scale_pos_weight=1, seed=27),
param_grid = param_test1, scoring=‘roc_auc‘,n_jobs=4,iid=False, cv=5)
gsearch1.fit(train[predictors],train[target])
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
至此,我们对于数值进行了较大跨度的12中不同的排列组合,可以看出理想的max_depth值为5,理想的min_child_weight值为5。在这个值附近我们可以再进一步调整,来找出理想值。我们把上下范围各拓展1,因为之前我们进行组合的时候,参数调整的步长是2。
param_test2 = {
‘max_depth‘:[4,5,6],
‘min_child_weight‘:[4,5,6]
}
gsearch2 = GridSearchCV(estimator = XGBClassifier( learning_rate=0.1, n_estimators=140, max_depth=5,
min_child_weight=2, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= ‘binary:logistic‘, nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test2, scoring=‘roc_auc‘,n_jobs=4,iid=False, cv=5)
gsearch2.fit(train[predictors],train[target])
gsearch2.grid_scores_, gsearch2.best_params_, gsearch2.best_score_
至此,我们得到max_depth的理想取值为4,min_child_weight的理想取值为6。同时,我们还能看到cv的得分有了小小一点提高。需要注意的一点是,随着模型表现的提升,进一步提升的难度是指数级上升的,尤其是你的表现已经接近完美的时候。当然啦,你会发现,虽然min_child_weight的理想取值是6,但是我们还没尝试过大于6的取值。像下面这样,就可以尝试其它值。
param_test2b = {
‘min_child_weight‘:[6,8,10,12]
}
gsearch2b = GridSearchCV(estimator = XGBClassifier( learning_rate=0.1, n_estimators=140, max_depth=4,
min_child_weight=2, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= ‘binary:logistic‘, nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test2b, scoring=‘roc_auc‘,n_jobs=4,iid=False, cv=5)
gsearch2b.fit(train[predictors],train[target])
modelfit(gsearch3.best_estimator_, train, predictors)
gsearch2b.grid_scores_, gsearch2b.best_params_, gsearch2b.best_score_
我们可以看出,6确确实实是理想的取值了。
在已经调整好其它参数的基础上,我们可以进行gamma参数的调优了。Gamma参数取值范围可以很大,我这里把取值范围设置为5了。你其实也可以取更精确的gamma值。
param_test3 = {
‘gamma‘:[i/10.0 for i in range(0,5)]
}
gsearch3 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=140, max_depth=4, min_child_weight=6, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= ‘binary:logistic‘, nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test3, scoring=‘roc_auc‘,n_jobs=4,iid=False, cv=5)
gsearch3.fit(train[predictors],train[target])
gsearch3.grid_scores_, gsearch3.best_params_, gsearch3.best_score_从这里可以看出来,我们在第一步调参时设置的初始gamma值就是比较合适的。也就是说,理想的gamma值为0。在这个过程开始之前,最好重新调整boosting回合,因为参数都有变化。 
从这里,可以看出,得分提高了。所以,最终得到的参数是:
xgb2 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=4,
min_child_weight=6,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= ‘binary:logistic‘,
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb2, train, predictors)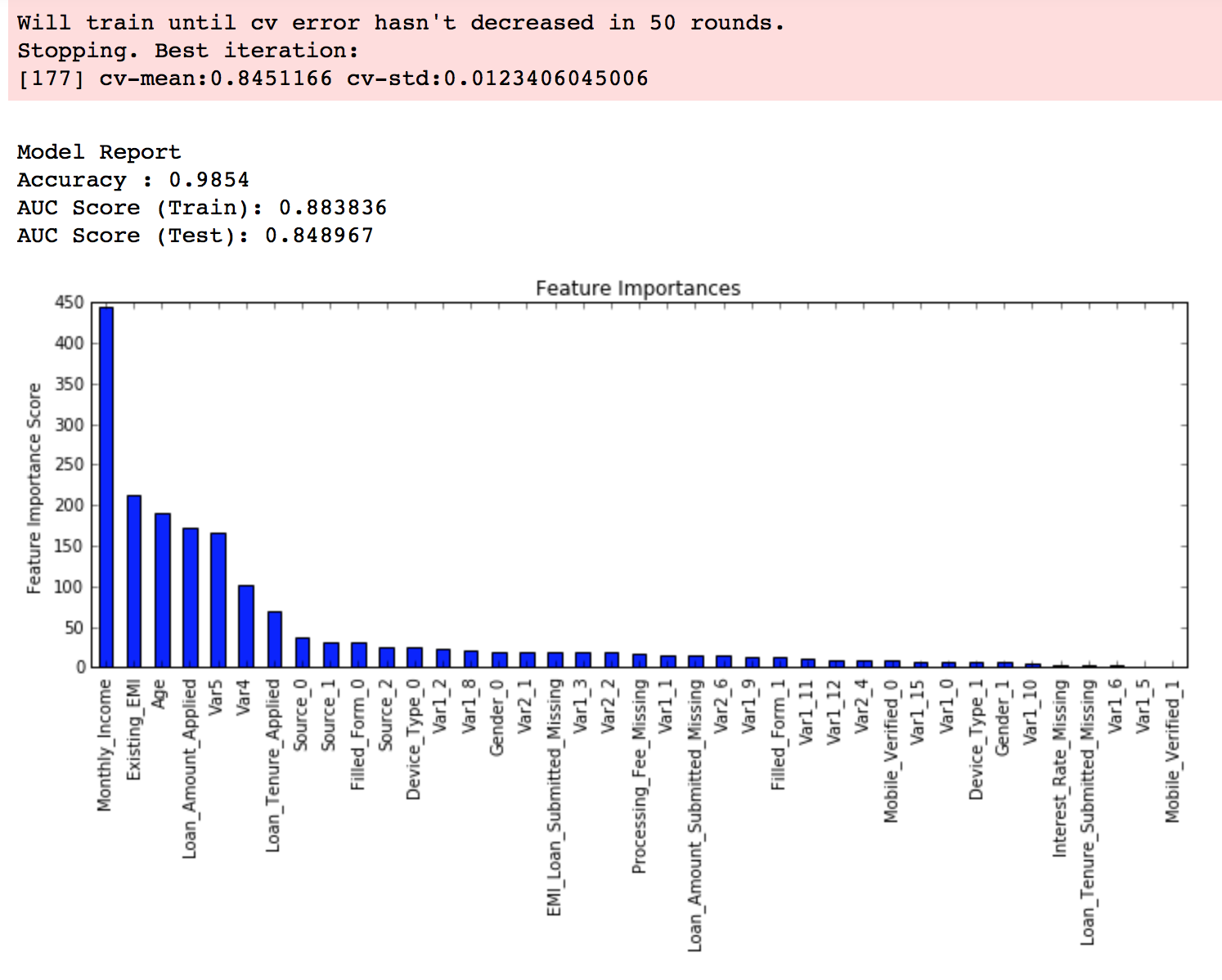
下一步是尝试不同的subsample 和 colsample_bytree 参数。我们分两个阶段来进行这个步骤。这两个步骤都取0.6,0.7,0.8,0.9作为起始值。
param_test4 = {
‘subsample‘:[i/10.0 for i in range(6,10)],
‘colsample_bytree‘:[i/10.0 for i in range(6,10)]
}
gsearch4 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=3, min_child_weight=4, gamma=0.1, subsample=0.8, colsample_bytree=0.8, objective= ‘binary:logistic‘, nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test4, scoring=‘roc_auc‘,n_jobs=4,iid=False, cv=5)
gsearch4.fit(train[predictors],train[target])
gsearch4.grid_scores_, gsearch4.best_params_, gsearch4.best_score_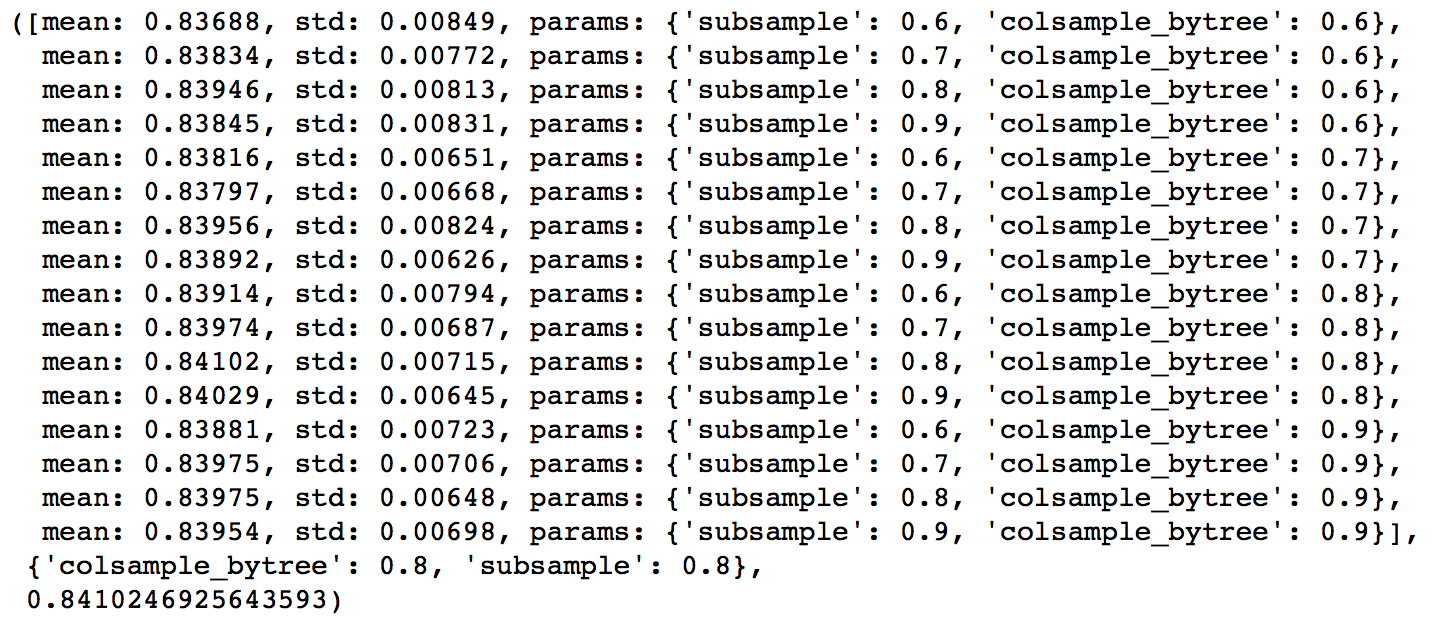
从这里可以看出来,subsample 和 colsample_bytree 参数的理想取值都是0.8。现在,我们以0.05为步长,在这个值附近尝试取值。
param_test5 = {
‘subsample‘:[i/100.0 for i in range(75,90,5)],
‘colsample_bytree‘:[i/100.0 for i in range(75,90,5)]
}
gsearch5 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=4, min_child_weight=6, gamma=0, subsample=0.8, colsample_bytree=0.8, objective= ‘binary:logistic‘, nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test5, scoring=‘roc_auc‘,n_jobs=4,iid=False, cv=5)
gsearch5.fit(train[predictors],train[target])
我们得到的理想取值还是原来的值。因此,最终的理想取值是:
下一步是应用正则化来降低过拟合。由于gamma函数提供了一种更加有效地降低过拟合的方法,大部分人很少会用到这个参数。但是我们在这里也可以尝试用一下这个参数。我会在这里调整’reg_alpha’参数,然后’reg_lambda’参数留给你来完成。
param_test6 = {
‘reg_alpha‘:[1e-5, 1e-2, 0.1, 1, 100]
}
gsearch6 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=4, min_child_weight=6, gamma=0.1, subsample=0.8, colsample_bytree=0.8, objective= ‘binary:logistic‘, nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test6, scoring=‘roc_auc‘,n_jobs=4,iid=False, cv=5)
gsearch6.fit(train[predictors],train[target])
gsearch6.grid_scores_, gsearch6.best_params_, gsearch6.best_score_
我们可以看到,相比之前的结果,CV的得分甚至还降低了。但是我们之前使用的取值是十分粗糙的,我们在这里选取一个比较靠近理想值(0.01)的取值,来看看是否有更好的表现。
param_test7 = {
‘reg_alpha‘:[0, 0.001, 0.005, 0.01, 0.05]
}
gsearch7 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=4, min_child_weight=6, gamma=0.1, subsample=0.8, colsample_bytree=0.8, objective= ‘binary:logistic‘, nthread=4, scale_pos_weight=1,seed=27), param_grid = param_test7, scoring=‘roc_auc‘,n_jobs=4,iid=False, cv=5)
gsearch7.fit(train[predictors],train[target])
gsearch7.grid_scores_, gsearch7.best_params_, gsearch7.best_score_
可以看到,CV的得分提高了。现在,我们在模型中来使用正则化参数,来看看这个参数的影响。
xgb3 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=4,
min_child_weight=6,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.005,
objective= ‘binary:logistic‘,
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb3, train, predictors)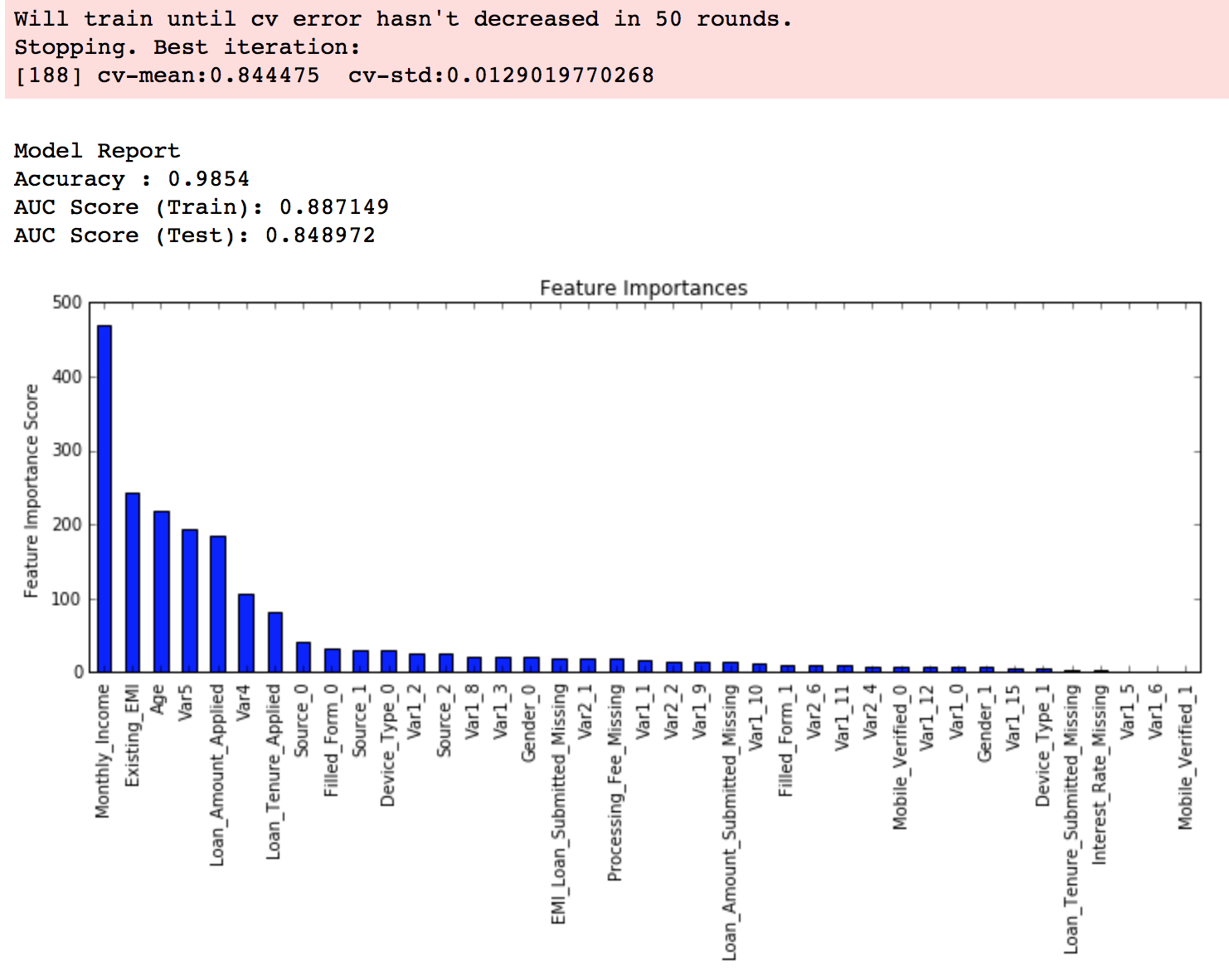
然后我们发现性能有了小幅度提高。
最后,我们使用较低的学习速率,以及使用更多的决策树。我们可以用XGBoost中的CV函数来进行这一步工作。
xgb4 = XGBClassifier(
learning_rate =0.01,
n_estimators=5000,
max_depth=4,
min_child_weight=6,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.005,
objective= ‘binary:logistic‘,
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb4, train, predictors)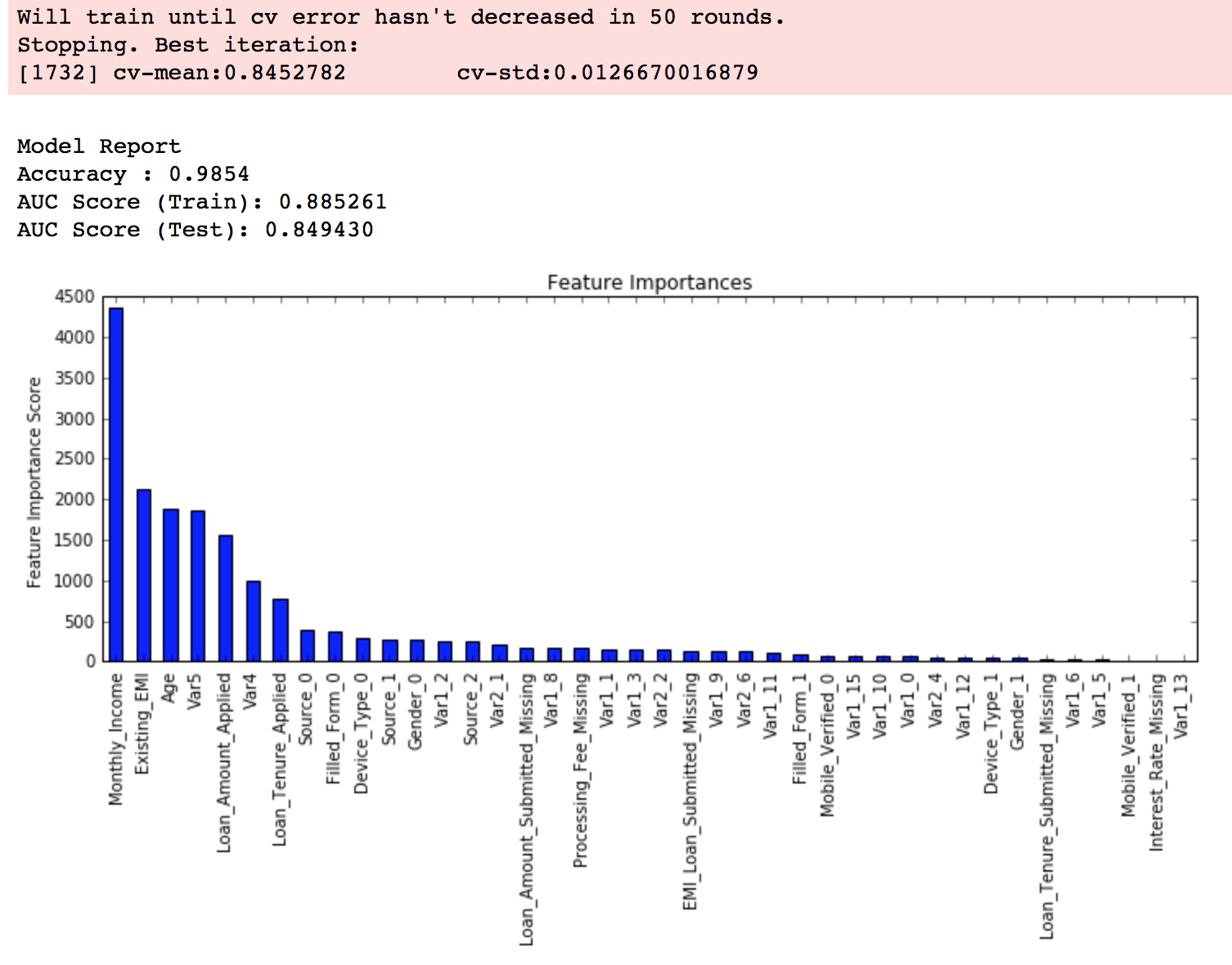
至此,你可以看到模型的表现有了大幅提升,调整每个参数带来的影响也更加清楚了。
在文章的末尾,我想分享两个重要的思想:
1、仅仅靠参数的调整和模型的小幅优化,想要让模型的表现有个大幅度提升是不可能的。GBM的最高得分是0.8487,XGBoost的最高得分是0.8494。确实是有一定的提升,但是没有达到质的飞跃。
2、要想让模型的表现有一个质的飞跃,需要依靠其他的手段,诸如,特征工程(feature egineering) ,模型组合(ensemble of model),以及堆叠(stacking)等。
你可以从 这里 下载iPython notebook文件,里面包含了文章中提到的所有代码。如果你使用R语言,请阅读这篇文章。
这篇文章主要讲了如何提升XGBoost模型的表现。首先,我们介绍了相比于GBM,为何XGBoost可以取得这么好的表现。紧接着,我们介绍了每个参数的细节。我们定义了一个可以重复使用的构造模型的函数。
最后,我们讨论了使用XGBoost解决问题的一般方法,在AV Data Hackathon 3.x problem数据上实践了这些方法。
希望看过这篇文章之后,你能有所收获,下次使用XGBoost解决问题的时候可以更有信心哦~
机器学习系列(12)_XGBoost参数调优完全指南(附Python代码)
标签:sample 数值 thml 个数 jobs auc 设定 account 现在
原文地址:https://www.cnblogs.com/fujian-code/p/9021342.html