标签:DBeaver 乱码
之前存在,在DBeaver中添加汉字注释后,选择另存为后,注释的汉字出现乱码问题?
解决方法:在环境变量中添加JAVA_TOOL_OPTIONS选项,添加参数-Dfile.encoding=UTF-8 -Duser.language=en -Duser.country=US,这样JDK的提示就是英文的,系统输出的中文也能正常显示了,适用于Java/Scala程序,Python也有类似的环境变量PYTHONIOENCODING.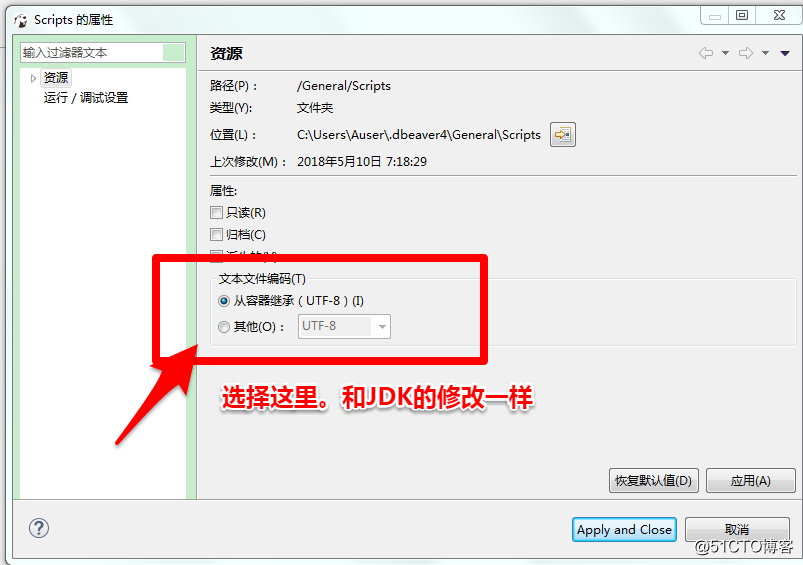
配合这里的修改后,基本不会再有乱码出现了。
下面说下为什么会出现乱码问题?
首先,乱码问题,不是无法解决的 问题。大家不要恐慌。乱码问题是因为字符集不同而产生的。
更专业点来说就是:计算机编码(字符集)。计算机编码是计算机代表字母和数字的方式(计算机不认识我们的文字语言。只认识0和1两个字符。这里就需要计算机编码转化为0和1。)这样我们就不会为使用计算机而学习计算机底层的生涩的低级语言(如汇编),只需要熟悉简单的键盘输入,计算机自己就完成了信息从输入到输出,把结果呈现给我们。
常见的编码方式有:ASCII编码,GB2312编码(简体中文),GBK,BIG5编码(繁体中文),ANSI编码,unicode,utf-8编码等
我们来谈下,这些的由来。最早。计算机就美国那几个大学在用。美国人输入键盘上的字符就足够了。所以诞生了ASCII编码,而且那时候的磁盘很小。而ASCII编码只占用一个字节(8个二进制位)。后来,美国人要让全世界都用计算机。可是,每个国家都有自己的文字。总不能全世界都用英语把。那样计算机的门槛那样高,你让不会英语的人事,怎么办?就有了后来的GBK,UTF-8等计算机编码。他们的产生,是的计算机可以把全世界绝大多数的语言文字都收录进去。才有了今天,中国人可以在计算机上输入中文。德国人可以输入德文。韩国人可以使用韩文操作计算机。当然,这得益于硬盘存储空间的增大。现在的这些计算机编码占2个字节(16个二进制位)。
现在,说说为什么会产生乱码?
由于计算机编码(字符集)的增多,大家可供选择的字符集就增多。所有造成了。各种软件和系统对计算机编码(字符集)的默认选择就不同。这是乱码的本源。
因为不同的发音在不同的语言中有截然不同的效果。同样适用于不同的字符在不同的计算机编码(字符集)下产生效果不一样。
打个比方:英文的who 是谁的意思。中文的hu 是窗户的户。还有就是上海的简称(沪)。这个例子就说明白了。不同字符在不同字符集中的效果了吧。
标签:DBeaver 乱码
原文地址:http://blog.51cto.com/12042068/2115021