标签:nts enc www. ber 关键词 src 学院 分类 文本聚类
全文检索概述
数据形式
结构化数据 有固定格式或者固定长度的数据 如通常关系型数据库文件 检索方式:结构化查询语句SQL语句
非结构化数据 没有固定结构的数据,各种文档、图片、视频/音频等都属于非结构化数据。 查询方式:遍历, 全文检索
半结构化数据 半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。因此,它也被称为自描述的结构。
全文检索过程
1.索引数据
三要点 1.document需要检索的数据 2.analyzer 分词技术 3.创建索引
2.查询数据
四要点 1.keywords关键词 2.analyzer 3.search 4.获取结果
lucene数学模型
1.文档、域、词元
文档是Lucene索引和搜索的原子单位,文档为包含一个或多个域的容器,而域则依次包含“真正的”被搜索的内容,域值通过分词技术处理,得到多个词元。
例如 小说为一个文档;小说信息包含多个域,如作者,简介,最后更新时间等;对标题这一个域采用分词技术,又可以得到一个或多个词元。
2. 词元权重计算
Term Frequency(tf)即此Term在文档中出现的次数,tf越大,该词元越重要。
Document Frequency(df)即多少文档包含此Term,df越大,该词元越不重要
Wt,d= TFt,d * log(n/DTt)
Wt,d = the weith of the term in document d
TFt,d = frequency of term in document d
n= total number of documents
DFt= the number of document that contain term t
把文档表示成权重的向量(空间向量模型) n个维度,每个维度代表一个词元 如下图:
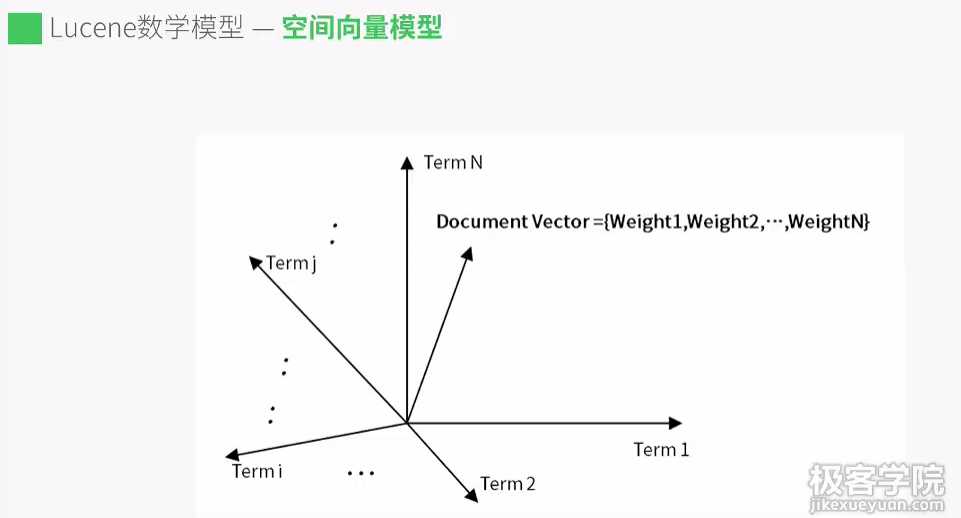
将一个文档的词元映射成n个空间向量
把所有的文档标识成n维空间向量模型,如何根据空间向量模型检索数据呢?
3.索引的检索
将搜索词分成多个词元 计算权重 把搜索词表示在n维空间向量模型中 ,然后用它与文档之间的夹角表示他们的相似度。
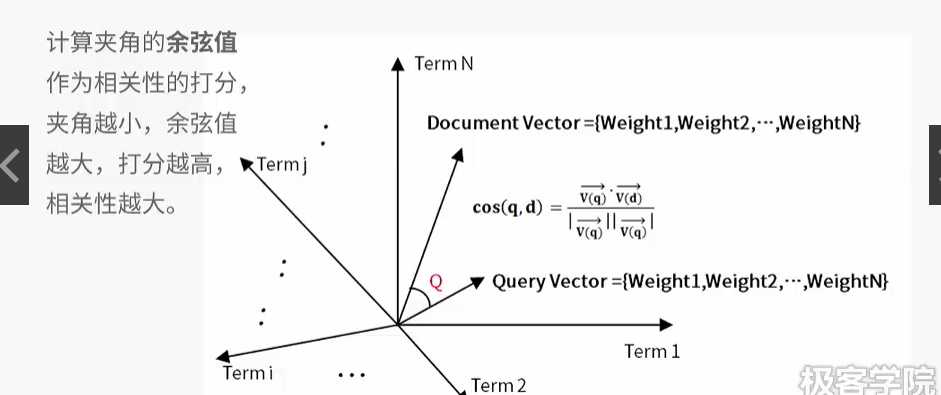
利用夹角余弦值进行相关性打分,加较小余弦值大,分数高,相似度高
(这样的空间向量模型不仅仅可以做全文检索,还有语句情感分析[没有理解噢],数据挖掘领域文本聚类和文本分类算法)
lucene如何保存空间向量信息呢?在计算机中以什么形式存在呢?
Lucene文件结构
1.层次结构
索引(index):一个索引放在一个文件夹中
段(segement):一个索引可以有很多段,段和段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段。
文档(Document):文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档
域(field):一个文档包含不同类型的信息,可以拆分开索引
词(Term):词是索引的最小单位,是经过词法分析和语言处理后的数据
一个索引可以分为多个段,一个段中可以包含多个文档,每个文档有不同的域,域可以通过分词技术得到词元。
2.正向信息
按照层次保存了索引一直到词的包含关系 :索引-> 段->文档->域->词
索引包含那些段,哪个段包含哪些文档,每篇文档包含哪些域,哪个域包含哪些词。
3.反向信息
保存了词典的倒排表映射:词->文档

segement文件中包含正向和反向信息
极客学院视频教程:http://www.jikexueyuan.com/course/937_1.html?ss=1
标签:nts enc www. ber 关键词 src 学院 分类 文本聚类
原文地址:https://www.cnblogs.com/fmys/p/8948276.html