标签:随机 节点 扩展 最小 shel 第一个 其他 开始 永久
定义-----递归就是在函数的内部调用自己
递归深度 998
不建议修改递归深度,因为如果998都没有解决,那么这个功能就不适合用递归写
例子:
猜年龄
alex多大,alex比wusir大两岁 40+2+2
wusit多大,wusir比金老板大两岁 40+2
金老板多大了,40了
def age(n)
if n == 3:
return 40
else:
return age(n+1)+2
age(1)
递归求解二分查找算法:
99*99 可以 99*100-99 就是9900 - 99 = 9801
这个属于人类的算法。
计算机的算法是 计算一些比较复杂的问题,所采用的 在空间上,或者时间上
更有优势的方法
空间就是节省内存。时间是执行时间计算速度更快
比如排序50000万个数找到最小的与最大的,一般是快速排序,堆排序,冒泡排序
查找功能使用算法
二分法: 只能查找有序的数字集合的查找问题
l = [2,3,4,5,6,7,8,9,0,11,22,23,24,27,33,37,44,46,55,59,66,67,77,74,88,90,92,98]
def cal(num=66):
length - len(l)
mid = length//2
if num > l[mid]:
l = l[mid:]
def cal(l,num,start,end)
if start < = end
mid = (end - start)//2 +start
if l[mid] > num:
return cal(l,num,start,mid-1)
elif l[mid] < num:
return cal(l,num,mid+1,end)
else:
print("找到了",mid,l[mid])
else:
return " 没找到"
2 模块的意义(摘抄):
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
3 模块的分类:
常用的 和某个操作相关的 根据相关性分为三类:内置模块。扩展模块。自定义模块
内置模块
安装了Python解析器后就一起提供了这些模块,一般是特别常用的
扩展模块
需要自己下载安装的模块
pypi网站:
www.pypi.org
自定义模块
自己写的模块
4 内置模块:
一 collections模块
orderedDict
提供了很多其他的数据结构,比如有序字典orderedDict
d = collections.OrderedDict()
counter
计算某一个字符串出现的次数
defaultdict
from collections import defaultdict
l = [11,22,33,44,55,66,77,88]
my_dict = defaultdict(list)
默认这个字典的value是一个空列表
print(my_dict["a"])
my_dict["b"] = 10
print(my_dict)
如果新创建了key 并指定了值,那么就按照你指定的值赋值,就不是默认列表了
namedtuple
创建一个元祖,但是里面的元素都用一个名字代表。
生成可以使用名字来访问元素内容的tuple
deque
双端队列,可以快速的从另外一侧追加和推出对象
二 时间模块
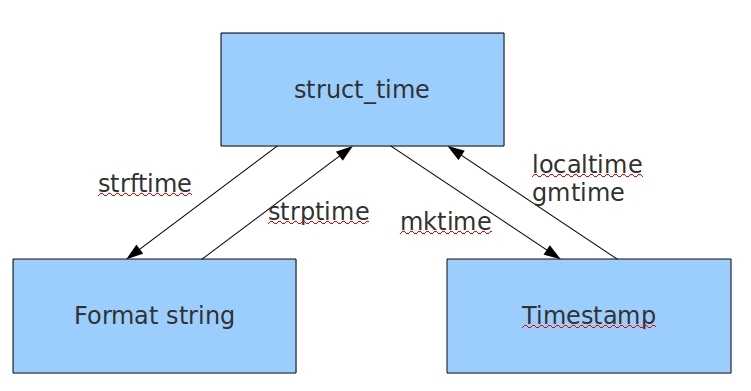
定义:时间模块通常有三种方式来表示时间:时间戳、格式化的时间字符串、元组(struct_time)
1。时间戳时间:表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
print(time.time())
2.格式化时间:
time.strftime("%Y-%m-%d %H:%M:%S")
还有%x %c等常用的格式。
格式化时间字符串(摘抄):
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
3.元组时间(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
print(time.localtime())
t = time.localtime()
格式(摘抄)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
4.时间的转换:
可以接收一个时间戳时间变成本地化的时间
print(time.localtime(1550000000))
格式化时间转字符串时间
stryct_time = time_gmtime(20000000000)
print(time.strftime("%Y-%m-%d %H:%M:%S",stryct_time))
格式化时间转时间戳时间
s = "1988-12-22 9:23:22"
ret = time.strptime(s,"%Y-%m-%d %H:%M:%S",stryct_time")
print(ret)
print(time.rmktime(ret))
练习题:
1 拿到当前时间的月初1号的0点的时间戳时间。
2 计算任意 两个时间点之间经过了多少年月日时分秒
datetime是根据time模块再次封装的模块 更上层
三 random模块
随机小数
random.random() 大于0且小于1之间的小数
random.uniform(1,3) 大于1小于3的小数
练习:
发红包
随机整数
random.randint(0,9) 取一到二
练习:
验证码
s = ""
for i in range(4):
s += rangom.randint(0,9)
print(s)
字母与数字都有:
id = ""
num = random.randint(65,90)
c = chr(num)
num2 = random.randint(0,9)
print(num2)
s = random.choice([c,num2])
print(s)
for i in range(4):
id += s
print(ss)
随机选择一个返回
随机选择多个返回,返回的个数为函数的第二个参数
四 os模块
系统相关模块
文件操作:
删除文件
os.remove()
重命名文件
os.rename("old","new")
目录操作:
os.makedirs("dir1/dir2") 多层递归创建目录
os.removedirs("dir1") 若目录为空则删除,并递归到上一级目录。如果也为空则删除。以此类推
os.mkdir("dir1") 生成单级目录
os.rmdir("dir1") 删除单级空目录 目录不为空则无法删除。
os.listdir("dir1") 列出指定目录下的所有文件和子目录。包括隐藏文件并以列表方式打印
当前工作目录有关操作:
os.getcwd() 获取当前工作目录。即当前python脚本工作的目录路径。
os.chdir("dir1") 改变当前脚本工作目录。相对于shell 的cd ,注意如果改变了路径 open 文件时候会在改变的路径下创建文件。
os.curdir() 返回当前目录:"."
os.pardir() 放回上一级目录:".."
stat 属性操作:
os.stat("dir/file")
st_mode inode保护模式
st_ino inode节点号
st_dev inode驻留设备
st_nlink inode的连接数
st_uid 所有者的用户ID
st_gid 所有者的组ID
st_size 普通文件以字节为单位大小,包含等待某些特殊文件的数据
st_atime 上次访问时间
st_mtime 上次修改元数据时间
st_ctime 上次修改文件内容数据的时间
操作系统差异:
os.sep 输出操作系特定的路径分隔符 win是\\ linux /
os.linesep 输出当前平台使用的行终止符 win是\t\n linux是\n
os.pathsep 输出用于分割文件路径的字符串 win ; linux :
"path1%spath2%s",%os.pathsep
os.name 输出字符串指示当前使用平台, win是 nt linux是posix
操作系统命令执行:
os.system 执行系统的命令,直接显示。
os.system("dir") 执行dir命令
os.popen 执行系统命令,返回返回值。
ret = os.popen("dir").read()
print(ret)
截屏
五 sys模块
Python解析器模块
sys.exit() 解释器退出,程序结束
sys.modules #放了所有在解释器运行过程中导入的模块名称。
sys.path 程序相关的路径。 一个模块能否导入需要看是否在这里sys.path列表里面存放的路径下面
sys.argv 在执行Python脚本的时候,可以传递一些参数进来
if sys.argv[1] == "alex" and sys.argv[2] == "alex3714":
print("可以执行下面的代码")
else:
print("密码错误退出")
sys.exit()
这个只能从命令行中执行并传入参数来使用
六 re正则表达式模块
功能比如简单的校验
正则表达式 字符串匹配相关的操作的时候用到的一种规则
正则表达式的规则
使用python中的re模块去操作正则表达式
在线测试工具
http://tool.chinaz.com/regex
正则表达式:
[] 匹配一个字符位置的字符
[0-9] 匹配0到9的字符
[a-z] 匹配a到z的字母
[A-Za-z] 匹配大小写字母
[0-9a-fA-F] 匹配一个十六进制字符
元字符:
. 匹配任意一个字符
\d 匹配任意一个数字
\w 匹配任意一个数字,字母,下划线
\s 匹配任意一个空白符
\n 匹配换行符
\t 匹配制表符
a\b 匹配单词结尾,这里是结尾是否是a
^a 匹配最开始 这里是匹配是a开头的字符
a$ 匹配结尾 这里是匹配a为结尾的字符
大写的就都是相反的
\W 就是匹配非数字,字母,下划线
[\w\W] 这是一种全组,可以匹配所有
ABC|ABCD 如果两个正则表达式先匹配到ABC那么就不往后匹配了,所以要先把长的写到前面
应该写为ABCD|ABC
[^...] 如果在字符组中加^ 那么就是除了字符组的其他的都匹配[^ABC]
量词
{num} 约束出现几次,只约束紧挨着前面的
[1][3-9][0-9]{9} 就是可以匹配前面[0-9]字符组出现9次
量词跟在一个元字符的后面 约束某个字符的规则能够重复多少次
如果要匹配的字符刚好是和元字符一模一样,那么需要对这个元字符进行转义 \
* 重复零次或多次
+ 重复一次或多次
?重复0次或一次
{n} 匹配n次
{n,} 重复n次或多次
{n,m} 重复n次到m次
贪婪普配
正则表达式中的所有量词,都会尽量多的为你匹配
+表示匹配一次或多次
算法:回朔算法
练习:
匹配整数与小数
\d+(/.\d+)?
惰性匹配
? 如果在量词的后面 ?号就是惰性匹配
\d+?
\d{3,5}? 只匹配3次
?? 只匹配0次或一次 尽量少匹配
{n,}? 匹配n次或多次,尽量只配置n次
.*?x 匹配任意字符碰到一个x就停止
匹配身份证
^[1-9]\d{14}(\d{2}[0-9x])?$
re模块方法:
re.findall() 匹配全部符合条件的值,并全部返回
ret = re.findall("\d+","df12 dsfs23dd sdfs21")
print(ret)
re.search() 找第一个符合条件的。同时返回的值是一个内存地址。需要group()调用
ret = re.search("\d+","df12 dsfs23dd sdfs21")
print(ret.group())
一般是
if ret:
print(ret.group())
re.match 在search基础上,给每一条都加上了^ 匹配开头
ret = re.match("\d+","df12 dsfs23dd sdfs21")
print(ret)
结果是空
re.split 匹配切割
re.sub 把数字替换成字符串 后面指定替换几次
ret = re.sub("\d","g","adfasdf2131sdfsdf",1)
re.subn 吧数字替换成字符串 并返回元祖(替换的结果,替换了多少次)
re.cap 不常用
注意:
findall 的优先级
如果匹配中有分组,那么只返回分组的匹配,所以需要在分组前加?:来取消分组优先级
作业:
字符串计算器,加减乘除小括号,使用正则
提示:先算小括号里面的
然后在算乘除,再算加减
三级菜单 递归 或堆栈
时间模块
红包
标签:随机 节点 扩展 最小 shel 第一个 其他 开始 永久
原文地址:https://www.cnblogs.com/liyunjie/p/9027137.html