标签:大于 ati stat 本地 1年 字母 不同 出现 ...
# pypi 可以查询python的模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
通过tuple表示一个二维坐标
# from collections import namedtuple # Point = namedtuple(‘Point‘, [‘x‘, ‘y‘]) # # p = (1,2) # p = Point(1,2) # print(p.x) # print(p.y)
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:

# from collections import deque # q = deque([1,2,3]) # print(type(q)) # print(dir(q)) ‘‘‘ ‘append‘, ‘appendleft‘, ‘clear‘, ‘copy‘, ‘count‘, ‘extend‘, ‘extendleft‘, ‘index‘, ‘insert‘, ‘maxlen‘, ‘pop‘, ‘popleft‘, ‘remove‘, ‘reverse‘, ‘rotate‘ ‘‘‘ ‘‘‘ def append(self, *args, **kwargs): # real signature unknown """ Add an element to the right side of the deque. """ pass def appendleft(self, *args, **kwargs): # real signature unknown """ Add an element to the left side of the deque. """ pass def clear(self, *args, **kwargs): # real signature unknown """ Remove all elements from the deque. """ pass def copy(self, *args, **kwargs): # real signature unknown """ Return a shallow copy of a deque. """ pass def count(self, value): # real signature unknown; restored from __doc__ """ D.count(value) -> integer -- return number of occurrences of value """ return 0 def extend(self, *args, **kwargs): # real signature unknown """ Extend the right side of the deque with elements from the iterable """ pass def extendleft(self, *args, **kwargs): # real signature unknown """ Extend the left side of the deque with elements from the iterable """ pass def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__ """ D.index(value, [start, [stop]]) -> integer -- return first index of value. Raises ValueError if the value is not present. """ return 0 def insert(self, index, p_object): # real signature unknown; restored from __doc__ """ D.insert(index, object) -- insert object before index """ pass def pop(self, *args, **kwargs): # real signature unknown """ Remove and return the rightmost element. """ pass def popleft(self, *args, **kwargs): # real signature unknown """ Remove and return the leftmost element. """ pass def remove(self, value): # real signature unknown; restored from __doc__ """ D.remove(value) -- remove first occurrence of value. """ pass def reverse(self): # real signature unknown; restored from __doc__ """ D.reverse() -- reverse *IN PLACE* """ pass def rotate(self, *args, **kwargs): # real signature unknown """ Rotate the deque n steps to the right (default n=1). If n is negative, rotates left. """ pass ‘‘‘ # q.append(1) # q.insert(2, 2) # print(q)
# 使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
# 如果要保持Key的顺序,可以用OrderedDict:
# 使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型
表示时间的三种方式
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。
(2)格式化的时间字符串(Format String): ‘1999-12-06’
(3)元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
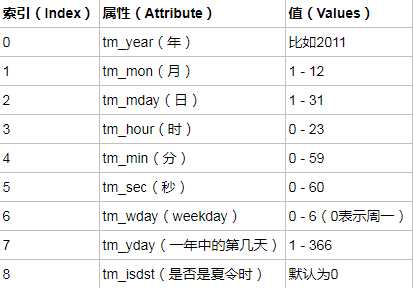
python表示时间的几种格式
#时间戳 >>>time.time() 1500875844.800804 #时间字符串 >>>time.strftime("%Y-%m-%d %X") ‘2018-05-4 13:54:37‘ >>>time.strftime("%Y-%m-%d %H-%M-%S") ‘2018-05-4 13-55-04‘ #时间元组:localtime将一个时间戳转换为当前时区的struct_time time.localtime() time.struct_time(tm_year=2018, tm_mon=5, tm_mday=4, tm_hour=13, tm_min=59, tm_sec=37, tm_wday=0, tm_yday=205, tm_isdst=0)
时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
三种格式间的转换
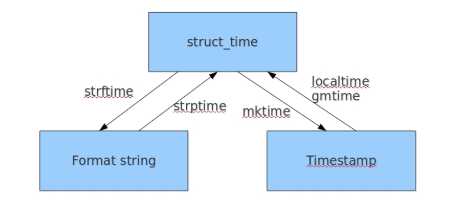
#时间戳-->结构化时间 #time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 #time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#结构化时间-->字符串时间 #time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则现实当前时间 >>>time.strftime("%Y-%m-%d %X") ‘2017-07-24 14:55:36‘ >>>time.strftime("%Y-%m-%d",time.localtime(1500000000)) ‘2017-07-14‘ #字符串时间-->结构化时间 #time.strptime(时间字符串,字符串对应格式) >>>time.strptime("2017-03-16","%Y-%m-%d") time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) >>>time.strptime("07/24/2017","%m/%d/%Y") time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
#结构化时间 --> %a %b %d %H:%M:%S %Y串 #time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串 >>>time.asctime(time.localtime(1500000000)) ‘Fri Jul 14 10:40:00 2017‘ >>>time.asctime() ‘Mon Jul 24 15:18:33 2017‘ #时间戳 --> %a %d %d %H:%M:%S %Y串 #time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串 >>>time.ctime() ‘Mon Jul 24 15:19:07 2017‘ >>>time.ctime(1500000000) ‘Fri Jul 14 10:40:00 2017‘
import time true_time=time.mktime(time.strptime(‘2017-09-11 08:30:00‘,‘%Y-%m-%d %H:%M:%S‘)) time_now=time.mktime(time.strptime(‘2017-09-12 11:00:00‘,‘%Y-%m-%d %H:%M:%S‘)) dif_time=time_now-true_time struct_time=time.gmtime(dif_time) print(‘过去了%d年%d月%d天%d小时%d分钟%d秒‘%(struct_time.tm_year-1970,struct_time.tm_mon-1, struct_time.tm_mday-1,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec))
>>> import random #随机小数 >>> random.random() # 大于0且小于1之间的小数 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #恒富:发红包 #随机整数 >>> random.randint(1,5) # 大于等于1且小于等于5之间的整数 >>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 >>> random.choice([1,‘23‘,[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 >>> random.sample([1,‘23‘,[4,5]],2) # #列表元素任意2个组合 [[4, 5], ‘23‘] #打乱列表顺序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打乱次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
import random def v_code(): code = ‘‘ for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,90)) add=random.choice([num,alf]) code="".join([code,str(add)]) return code print(v_code())
# googole面试题
# 6位数字+字母的随机数
# 核心思想是通过ascii表转换数字为字母
# random.choice() 随机选择一个元素返回
# chr转换数字为ascii表对应的字母
identify_code = ‘‘ for i in range(6): num = random.randint(65, 90) alpha1 = chr(num) num = random.randint(97, 122) alpha2 = chr(num) num = random.randint(0, 9) random_num = random.choice([alpha1, alpha2, num]) identify_code += str(random_num) print(identify_code)
os模块是与操作系统交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: (‘.‘) os.pardir 获取当前目录的父目录字符串名:(‘..‘) os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat(‘path/filename‘) 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.environ 获取系统环境变量 os.path os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。 即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
注意:os.stat(‘path/filename‘) 获取文件/目录信息 的结构说明
stat 结构: st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
sys模块是与python解释器交互的一个接口
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
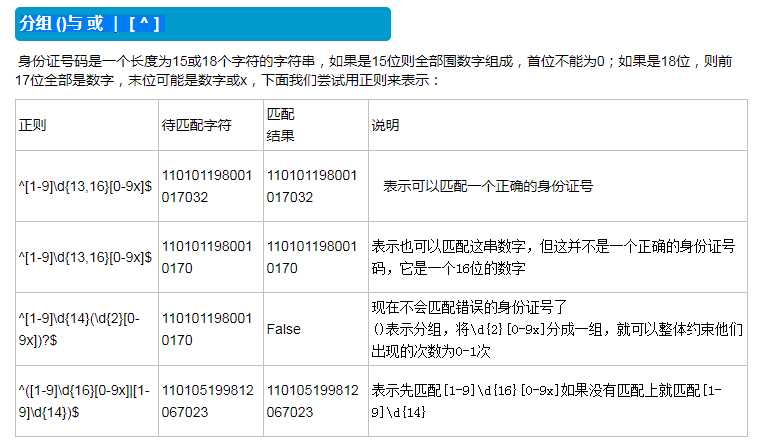
正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
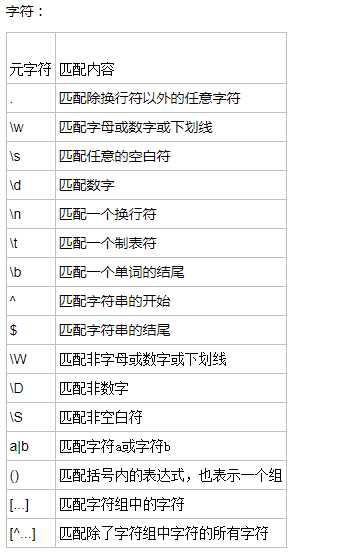


注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
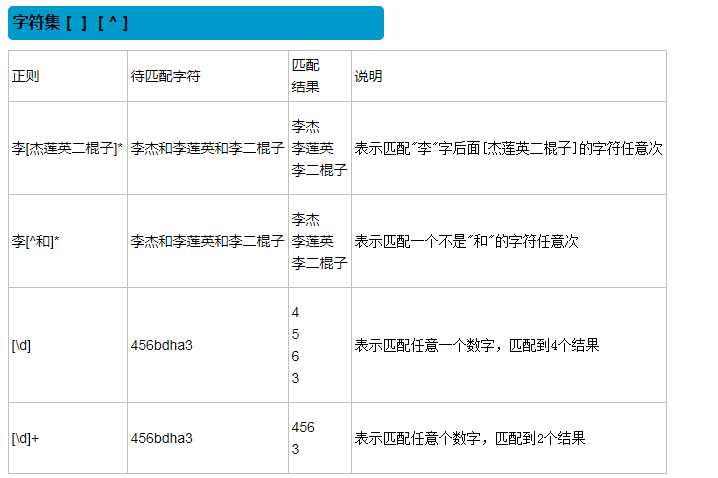
在正则表达式中,有很多有特殊意义的是元字符,比如\d和\s等,如果要在正则中匹配正常的"\d"而不是"数字"就需要对"\"进行转义,变成‘\\‘。

贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
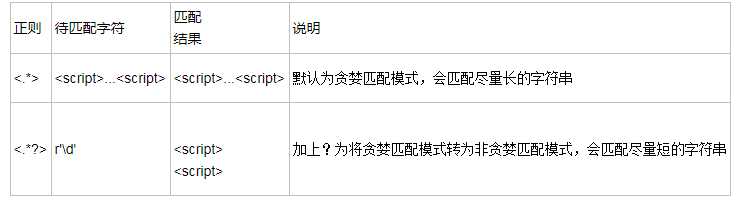
几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复 +? 重复1次或更多次,但尽可能少重复 ?? 重复0次或1次,但尽可能少重复 {n,m}? 重复n到m次,但尽可能少重复 {n,}? 重复n次以上,但尽可能少重复
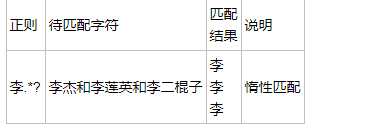
.*?的用法
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
import re ret = re.findall(‘a‘, ‘eva egon yuan‘) # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : [‘a‘, ‘a‘] ret = re.search(‘a‘, ‘eva egon yuan‘).group() print(ret) #结果 : ‘a‘ # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 ret = re.match(‘a‘, ‘abc‘).group() # 同search,不过尽在字符串开始处进行匹配 print(ret) #结果 : ‘a‘ ret = re.split(‘[ab]‘, ‘abcd‘) # 先按‘a‘分割得到‘‘和‘bcd‘,在对‘‘和‘bcd‘分别按‘b‘分割 print(ret) # [‘‘, ‘‘, ‘cd‘] ret = re.sub(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘, 1)#将数字替换成‘H‘,参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘)#将数字替换成‘H‘,返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile(‘\d{3}‘) #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search(‘abc123eeee‘) #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer(‘\d‘, ‘ds3sy4784a‘) #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
1 findall的优先级查询:
import re ret = re.findall(‘www.(baidu|oldboy).com‘, ‘www.oldboy.com‘) print(ret) # [‘oldboy‘] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall(‘www.(?:baidu|oldboy).com‘, ‘www.oldboy.com‘) print(ret) # [‘www.oldboy.com‘]
2 split的优先级查询
ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : [‘eva‘, ‘egon‘, ‘yuan‘] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #结果 : [‘eva‘, ‘3‘, ‘egon‘, ‘4‘, ‘yuan‘] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
import re ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group(‘名字‘)拿到对应的值 print(ret.group(‘tag_name‘)) #结果 :h1 print(ret.group()) #结果 :<h1>hello</h1> ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print(ret.group(1)) print(ret.group()) #结果 :<h1>hello</h1>
import re ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #[‘1‘, ‘2‘, ‘60‘, ‘40‘, ‘35‘, ‘5‘, ‘4‘, ‘3‘] ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #[‘1‘, ‘-2‘, ‘60‘, ‘‘, ‘5‘, ‘-4‘, ‘3‘] ret.remove("") print(ret) #[‘1‘, ‘-2‘, ‘60‘, ‘5‘, ‘-4‘, ‘3‘]
1、 匹配一段文本中的每行的邮箱 http://blog.csdn.net/make164492212/article/details/51656638 2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’; 分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、 一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,} 4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d* 5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$ 6、 匹配出所有整数
import requests import re import json def getPage(url): response=requests.get(url) return response.text def parsePage(s): com=re.compile(‘<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>‘ ‘.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>‘,re.S) ret=com.finditer(s) for i in ret: yield { "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url=‘https://movie.douban.com/top250?start=%s&filter=‘%num response_html=getPage(url) ret=parsePage(response_html) print(ret) f=open("move_info7","a",encoding="utf8") for obj in ret: print(obj) data=json.dumps(obj,ensure_ascii=False) f.write(data+"\n") if __name__ == ‘__main__‘: count=0 for i in range(10): main(count) count+=25
import re import json from urllib.request import urlopen def getPage(url): response = urlopen(url) return response.read().decode(‘utf-8‘) def parsePage(s): com = re.compile( ‘<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>‘ ‘.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>‘, re.S) ret = com.finditer(s) for i in ret: yield { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } def main(num): url = ‘https://movie.douban.com/top250?start=%s&filter=‘ % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("move_info7", "a", encoding="utf8") for obj in ret: print(obj) data = str(obj) f.write(data + "\n") count = 0 for i in range(10): main(count) count += 25
flags有很多可选值: re.I(IGNORECASE)忽略大小写,括号内是完整的写法 re.M(MULTILINE)多行模式,改变^和$的行为 re.S(DOTALL)点可以匹配任意字符,包括换行符 re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用 re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
实现能计算类似 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式的计算器程序
标签:大于 ati stat 本地 1年 字母 不同 出现 ...
原文地址:https://www.cnblogs.com/zh-lei/p/9026411.html
