标签:hot lin lov for network 映射 can mode word
这篇文章是论文‘Chinese Poetry Generation with Recurrent Neural Network’的阅读笔记,这篇论文2014年发表在EMNLP。
这篇论文提出了一个基于RNN的中国古诗生成模型。
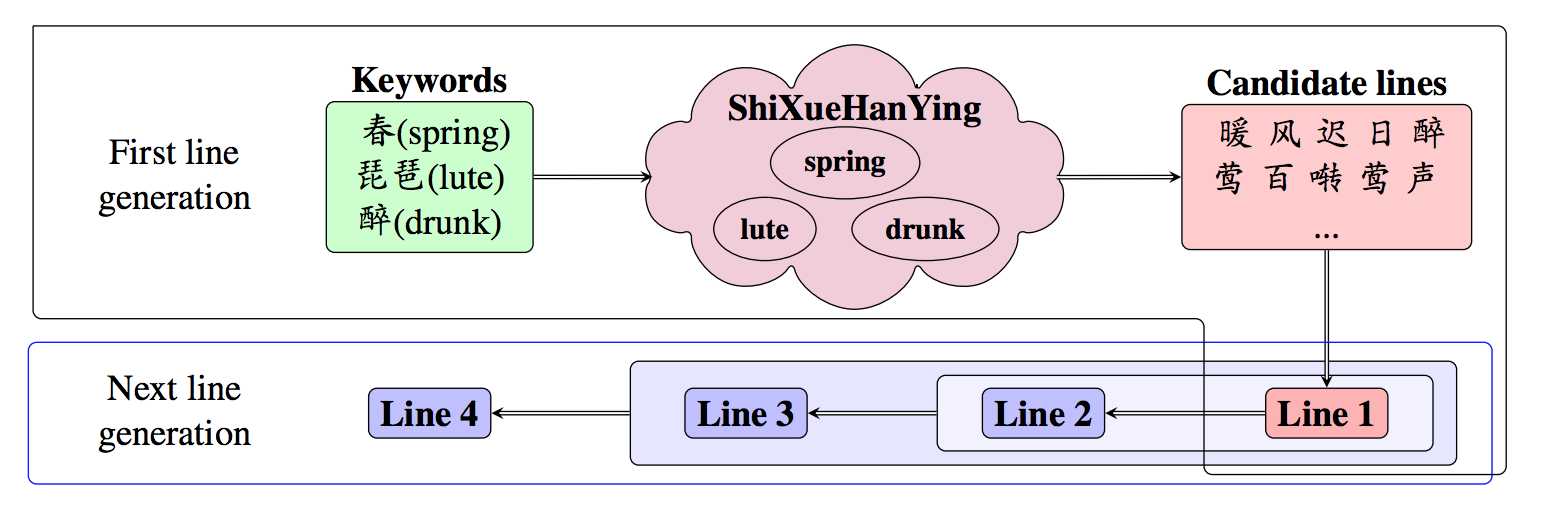
第一句的生成是规则式的。
先自定义几个keywords,然后通过《诗学含英》(这是清朝人编写的)扩展出更多的相关短语。然后生成所有满足格式约束(主要是音调方面的)的句子,接下来用一个语言模型排个序,找到最好的。
原文中有挺重要的一句,但是我没看懂。
In implementation,we employ a character-based recurrent neural network language model (Mikolov et al., 2010) interpolated with a Kneser-Ney trigram and find the n-best candidates with a stack decoder.
一个字一个字的生成。
已经有了前面的1,2,3..i句话,句子\(S_{i+1}\)的条件概率:
\[
P(S_{i+1}|S_{1:i}) = \prod_{j=1}^{m-1}P(W_{j+1}|w_{1:j},S_{1:i})
\]
也就是构成这个句子的每个字的概率乘积。每个字概率依赖于前面的j-1个字以及前面的i句话。
整个模型由三个子模型构成:
1, CSM模型,convolution sentence model
这个模型的任务是把已经生成的句子\(S_i\)映射到一个vector \(v_i\)
\[
v_i = CSM(S_i)
\]
这里采用的是基于CNN的senence model, Kalchbrenner and Blunsom (2013)
2, RCM模型,recurrent context model
这个模型的把CSM对前面i个句子生成的i个向量映射到\(u_{i}^{j}\)
\[
u_i^{j}=RCM(v_{1:i},j)
\]
这是个encode-decode模型,先把前i个句子encode到一个向量,然后再decode到m个向量,每个向量对应一个位置,如果是五言绝句那就是decode出5个向量,分别对应着5个字。然后把这些向量拼接起来。
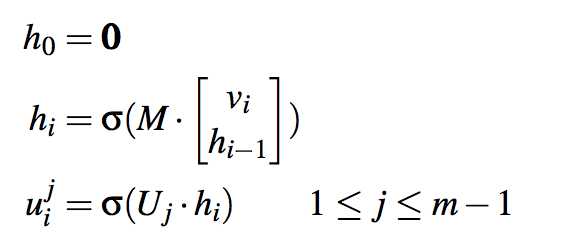
3,RGM模型,recurrent generation model
预测下个输出是字w的概率(w是字典里面的任意一个字),以RCM的输出、前j个字、字本身的信息(这个模型用的是one-hot encoding向量)为输入。
\[
P(w_{j+1}|w_{1:j},S_{1:i}) = RGM(w_{1:j+1},u_i^{j})
\]
这里其实是个语言模型
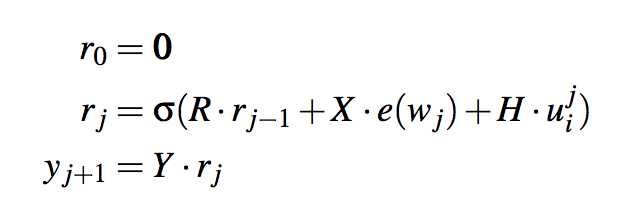
\(e(w_j)\)是字w的one-hot encoding.Y需要注意,“matrix \(Y\subset R^{|V|\times q}\) decodes the hidden representation to weights for all words in the vocabulary”
这篇文章有两个创新点:
欣赏一下整个模型生成的诗歌吧

论文《Chinese Poetry Generation with Recurrent Neural Network》阅读笔记
标签:hot lin lov for network 映射 can mode word
原文地址:https://www.cnblogs.com/naniJser/p/9029619.html