[root@bogon tmp]# cat awktest1
one#two#three num
zhangsan nan
lisi nv
wangwu nan
laowang nan
[root@bogon tmp]#
[root@bogon tmp]# awk ‘/^[^$]/‘ awktest1 ^在[]里面表示不匹配之意
one#two#three num
zhangsan nan
lisi nv
wangwu nan
laowang nan
[root@bogon tmp]#
[root@bogon tmp]# awk ‘/^lao/{print $2}‘ awktest1
nan
[root@bogon tmp]#x{m}:x重复m次
x{m,}:x至少重复m次
x{,m}:x至多重复m次
x{m,n}:x至少重复m次,但不超过n次
[root@bogon tmp]# cat awk1
root
rrtt
good
[root@bogon tmp]# awk --posix ‘/o{2}/{print $0}‘ awk1
root
good
[root@bogon tmp]#2、关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试
、<、=、>=、<=
[root@bogon tmp]# awk ‘NR>=2{print $0}‘ awk1 rrtt good [root@bogon tmp]#3、模式匹配正则表达式:用运算符~(匹配)和~!不匹配
[root@localhost ~]# ifconfig enp0s3 | awk -F "[: ]*" ‘$2~/inet$/ {print $3}‘
4、还能匹配类似sed的地址范围[root@bogon tmp]# cat awk1 root rrtt good hello nihao nizaiganma [root@bogon tmp]# [root@bogon tmp]# awk ‘NR==2,NR==4{print $0}‘ awk1 rrtt good hello [root@bogon tmp]# [root@bogon tmp]# awk ‘/^rr/,NR==3{print $0}‘ awk1 rrtt good [root@bogon tmp]#5、BEGIN 语句块, END语句块
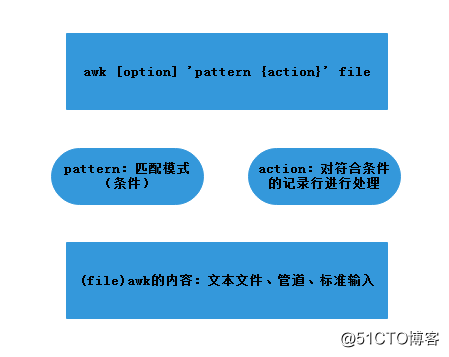
操作(action)
操作由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大括号内,主要部分是:变量或数组赋值、输出命令、内置函数、控制流语句。比如:print函数,’{print $1}’
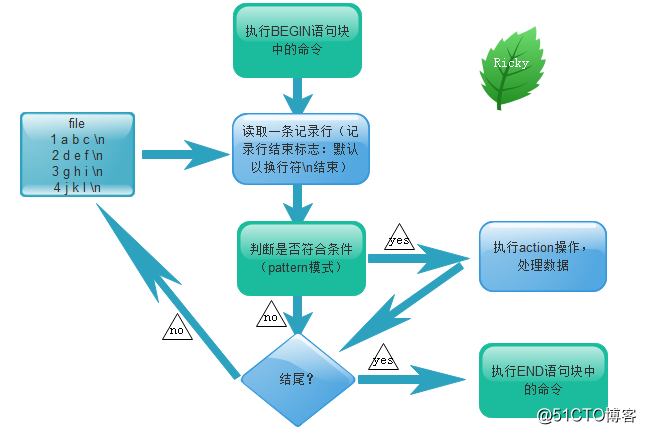
awk命令处理流程图
如果没有定义BEGIN与END语句块,那么就不会执行BEGIN、END语句块。
awk参数
-F re:允许awk更改其字段分隔符
-v var=$v 把v值赋值给var,如果有多个变量要赋值,那么就写多个-v,每个变量赋值对应一个-v
e.g. 要打印文件a的第num行到num+num1行之间的行,
awk -v num=$num -v num1=$num1 ‘NR==num,NR==num+num1{print}‘ a
-f progfile:允许awk调用并执行progfile程序文件,当然progfile必须是一个符合awk语法的程序文件。
-F参数等同于" -v FS=要给FS赋的值 " 【即指定字段分隔符,如-F “:”等于-v FS=:,指定以冒号为分隔符】
--posix或—re-interval:某些正则模式下,需要指定该参数来使用正则(常用的是-F与--posix)
awk内置变量
$n:当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段
$0:这个变量包含执行过程中当前行的文本内容【整行】
NR:表示记录数,在执行过程中对应于当前的行号
FS:字段分隔符(默认是空格)
OFS:输出字段分隔符(默认是空格)
NF($NF ):表示字段数,在执行过程中对应于当前的字段数;print $NF 打印一行中最后一个字段
ORS:输出记录分隔符(默认值是换行符)
RS:记录分隔符(默认是换行符)
ARGC:命令行参数的数目
ARGIND:命令行中当前文件的位置(从0开始算)
ARGV:包含命令行参数的数组
CONVFMT:数字转换格式(默认值为%.6g)
ENVIRON:环境变量关联数组
ERRNO:最后一个系统错误的描述
FIELDWIDTHS:字段宽度列表(用空格键分隔)
FILENAME:当前输入文件的名
FNR:同NR,但相对于当前文件
IGNORECASE:如果为真,则进行忽略大小写的匹配
OFMT:数字的输出格式(默认值是%.6g)
RSTART:有match函数所匹配的字符串的第一个位置
RLENGTH:由match函数所匹配的字符串的长度
SUBSEP:数组下标分隔符(默认值是34)
BEGIN:awk命令执行前执行该操作,可在这定义变量(内置变量)
END:awk命令执行完成后执行该操作,可用来最后输出结果,统计信息,计算空行等。
常用内置变量详解:
NR,NF ,$n,FS,OFS,RS,ORS
实验环境:
[root@bogon tmp]# cat awktest
Hello 1
2
3
I am a teacher 4
I like basketball 5$n 当前记录(行)的第n个字段(位置变量),默认以空格为分隔符,“$0”表示整行
[root@bogon tmp]# awk ‘{print $0}‘ awktest
Hello 1
2
3
I am a teacher 4
I like basketball 5
[root@bogon tmp]#
[root@bogon tmp]# awk ‘{print $1}‘ awktest
Hello
2
3
I
I
[root@bogon tmp]#NR:表示输入记录数(行号)
[root@bogon tmp]# awk ‘{print NR,$0}‘ awktest
1 Hello 1
2 2
3 3
4 I am a teacher 4
5 I like basketball 5
[root@bogon tmp]# awk ‘NR==4{print NR,$0}‘ awktest
4 I am a teacher 4
[root@bogon tmp]#NF:表示每行输入字段数
什么是字段?
例如:第4行“I am a teacher”
默认是以空格为分隔符,“I”第一个字段,“am”第二个字段,依此类推,第4行共4个字段
“$NF”表示行的最后一个字段
[root@bogon tmp]# awk ‘{print NF,$0}‘ awktest
2 Hello 1
1 2
1 3
5 I am a teacher 4
4 I like basketball 5
[root@bogon tmp]# awk ‘{print $NF}‘ awktest
1
2
3
4
5
[root@bogon tmp]#FS或-F:输入字段分隔符,默认为空格
[root@bogon tmp]# awk -F ":" ‘NR==1{print $2}‘ /etc/passwd
x
[root@bogon tmp]# awk ‘BEGIN{FS=":"}NR==1{print $2}‘ /etc/passwd
x
[root@bogon tmp]#OFS :输出字段分隔符,默认为空格
$0默认是不会改变行的结果的,所以想要使用$0输出,又想改变其结果,那么就需要在前面给它个动作;一般很少使用$0输出
[root@bogon tmp]# awk ‘BEGIN {FS=" ";OFS="@"}{print $0}‘ awktest
Hello 1
2
3
I am a teacher 4
I like basketball 5
[root@bogon tmp]# awk ‘BEGIN {FS=" ";OFS="@"}$1=$1{print $0}‘ awktest 给个动作$0,使其改变输出结果
Hello@1
2
3
I@am@a@teacher@4
I@like@basketball@5
[root@bogon tmp]# awk ‘BEGIN {FS=" ";OFS="@"}{print $1,$2,$3}‘ awktest
Hello@1@
2@@
3@@
I@am@a
I@like@basketball
[root@bogon tmp]#
[root@bogon tmp]# awk ‘BEGIN{FS="[:/]";OFS="#"}NR==1{print $1,$NF}‘ /etc/passwd
root#bash
[root@bogon tmp]#RS:输入记录行分隔符,默认为换行符(读入时候的分隔符,意思就是一某个符号作为行的分隔符来划分行,默认是换行符\n)
awk处理对象是记录和域(字段),而不是我们常说的行,读取的文本是一连串的字符记录,默认每条记录的结束标志是换行符“\n”。
[root@bogon tmp]# awk ‘{print NR,$0}‘ awk.txt
1 root:x:0:0:root:/root:/bin/bash\n
2 bin:x:1:1:bin:/bin:/sbin/nologin\n
[root@bogon tmp]# awk ‘BEGIN{RS="/"}{pritn NR,$0}‘ awk.txt 现在把划分行的分隔符改为“/”,存在“/”就是回车换行
awk: BEGIN{RS="/"}{pritn NR,$0}
awk: ^ syntax error
[root@bogon tmp]# awk ‘BEGIN{RS="/"}{print NR,$0}‘ awk.txt
1 root:x:0:0:root:
2 root:
3 bin
4 bash
bin:x:1:1:bin: 因为\n已经不是记录分隔符,所以这行不会被算作记录行
5 bin:
6 sbin
7 nologin
因为\n已经不是记录分隔符,所以这行不会被算作记录行
[root@bogon tmp]#
[root@bogon tmp]# cat ricky
1\n
2\n
3\n
1\n
4\n
5\n
1\n
6\n
7\n
[root@bogon tmp]# awk ‘BEGIN{RS="1"}{print $1,$2,$3}‘ ricky
1作为分隔符,所空行
2 3 \n不再是分隔符,所以2与3之间的\n,成为了一个空格存在
4 5
6 7
[root@bogon tmp]#ORS:输出记录行分隔符,默认为换行符(输出时的分隔符),是RS的逆向操作
把下面的文本变成一行
one\n
two\n
three\n
[root@localhost tmp]# awk ‘BEGIN{ORS=" "}{print $0}‘ awktest2 (把换行符"\n"转变为空格)
one two three [root@localhost tmp]# BEGIN语句块
awk命令执行前执行该操作,可在这定义变量(内置变量)
[root@bogon tmp]# awk ‘BEGIN{FS=":"}NR==1{print $2}‘ /etc/passwd
x
[root@bogon tmp]#END语句块
awk命令执行完成后执行该操作,可用来最后输出结果,统计信息,计算空行等。
例1:
统计文件里面的空行数量
grep实现
[root@bogon tmp]# grep -c "^$" /etc/init.d/sshd (-c计算符合条件的行数)
20
[root@bogon tmp]#awk实现
[root@bogon tmp]# awk ‘/^$/{a++;print a}‘ /etc/init.d/sshd (调试,每次匹配都输出a的值)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[root@bogon tmp]# awk ‘/^$/{a++}END{print a}‘ /etc/init.d/sshd(统计信息,在awk命令结束后输出a的值,“/^$/{a++},条件匹配一次,变量a的值加1”)
20
[root@bogon tmp]#例2:
找出变量环境$PATH中,所有只有三个任意字符的命令,例如tee,并讲他们重定向到command.txt,要求一行显示一个,并在文件尾部统计他们的个数。
[root@bogon tmp]# echo $PATH
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin:/bin:/root/bin
[root@bogon tmp]# echo $PATH | tr ":" "\n"
/usr/local/sbin
/usr/local/bin
/sbin
/bin
/usr/sbin
/usr/bin
/root/bin
/bin
/root/bin
[root@bogon tmp]# find $(echo $PATH | tr ":" "\n") -type f -name "???" 2>/dev/null |awk ‘{a++}{print $0}END{print "result:"a}‘ >>command.txt (?在命令当中数通配符,任意一个字符;
? 通配符用户匹配文件名;而在正则中表示匹配其前字符0次或1次)
[root@bogon tmp]# cat command.txt
/sbin/cbq
/sbin/lvm
/sbin/sln
/sbin/arp
/bin/env
/bin/raw
/bin/cat
/bin/cut
/bin/rpm
/bin/sed
/bin/tar
/bin/pwd
/usr/sbin/lid
/usr/sbin/zic
/usr/bin/lua
/usr/bin/grn
/usr/bin/dir
/usr/bin/who
/usr/bin/tac
/usr/bin/seq
/usr/bin/xxd
/usr/bin/cpp
/usr/bin/cmp
/usr/bin/idn
/usr/bin/fmt
/usr/bin/yum
/usr/bin/pic
/usr/bin/tic
/usr/bin/eqn
/usr/bin/toe
/usr/bin/man
/usr/bin/tee
/usr/bin/ptx
/usr/bin/ldd
/usr/bin/c89
/usr/bin/s2p
/usr/bin/a2p
/usr/bin/sum
/usr/bin/sar
/usr/bin/vim
/usr/bin/top
/usr/bin/tbl
/usr/bin/tty
/usr/bin/c99
/usr/bin/gcc
/usr/bin/rev
/usr/bin/col
/usr/bin/yes
/usr/bin/cal
/bin/env
/bin/raw
/bin/cat
/bin/cut
/bin/rpm
/bin/sed
/bin/tar
/bin/pwd
result:57
[root@bogon tmp]#数组
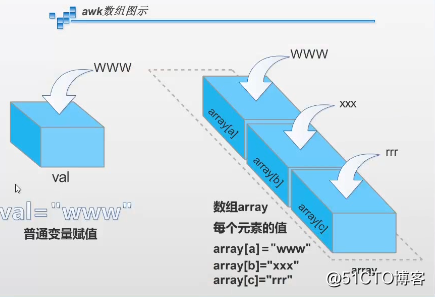
数组的结构
处理以下文件内容,将域名取出并根据域名进行统计数排序处理
http://www.baidu.com/index.html
http://www.baidu.com/1.html
http://post.baidu.com/index.html
http://mp3.baidu.com/index.html
http://www.baidu.com/3.html
http://post.baidu.com/2.html
方案一:
[root@bogon tmp]# awk ‘BEGIN{FS="/"}{print $3}‘ baidu.txt | sort | uniq -c
1 mp3.baidu.com
2 post.baidu.com
3 www.baidu.com
[root@bogon tmp]#方案二:
[root@bogon tmp]# awk ‘BEGIN{FS="/"}{array[$3]++}END{for (key in array)print key,array[key]}‘ baidu.txt
post.baidu.com 2
www.baidu.com 3
mp3.baidu.com 1
[root@bogon tmp]#分析数组
array[$3]++ > array[$3]= array[$3]+1=0+1 (array[$3]初始值为0)
array[www.baidu.com]++ >0+1 1
array[www.baidu.com]++ >1+1 2
array[post.baidu.com]++ >0+1 1
array[mp3.baidu.com(数组名)]++ >0+1 1(数组的值)
array[www.baidu.com]++ >2+1 3
array[post.baidu.com]++ >1+1 2
for key in array (代表数组名)
for key in post.baidu.com www.baidu.com mp3.baidu.com
array[key]
array[post.baidu.com]++ >1+1 2
array[www.baidu.com]++ >2+1 3
array[mp3.baidu.com]++ >0+1 1
总结
记录与字段
模式:正则;模式匹配正则;sed地址范围;关系表达式
操作
参数:--posix或—re-interval
内置变量:FS;OFS;RS;ORS;NF($NF);$n($0)
语句块:BEGIN;END
数组
Linux运维三剑客awk必会知识--模式与操作、内自变量、语句块、数组
原文地址:http://blog.51cto.com/13691477/2115568