标签:acea info lan pen 文字 均值 时空 lag pac
一、随机数Random
1.Math.Random
返回带正号的 double 值,该值大于等于 0.0 且小于 1.0。不包含1.0。[0,1);
public static void main(String[] args) { //生成伪随机数 System.out.println(Math.random()); }
运行结果为: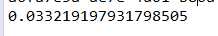
2.Random类
此类的实例用于生成伪随机数流。
| 构造方法摘要 | |
|---|---|
Random() 创建一个新的随机数生成器。 |
|
Random(long seed)
使用单个 long 种子创建一个新的随机数生成器。 |
|
什么是伪随机数呢?我们来看一个例子

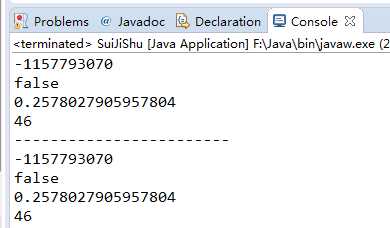
r1和r2生成的随机数竟然是一样的!这是为什么呢?
这就是伪字的真谛,即通过相同的种子生成的随机数是一样的
| 方法摘要 | |
|---|---|
protected int |
next(int bits) 生成下一个伪随机数。 |
boolean |
nextBoolean()
返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 boolean 值。 |
void |
nextBytes(byte[] bytes)
生成随机字节并将其置于用户提供的 byte 数组中。 |
double |
nextDouble()
返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0
之间均匀分布的 double 值。 |
float |
nextFloat()
返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0
之间均匀分布的 float 值。 |
double |
nextGaussian()
返回下一个伪随机数,它是取自此随机数生成器序列的、呈高斯(“正态”)分布的 double 值,其平均值是
0.0,标准差是 1.0。 |
int |
nextInt()
返回下一个伪随机数,它是此随机数生成器的序列中均匀分布的 int 值。 |
int |
nextInt(int n)
返回一个伪随机数,它是取自此随机数生成器序列的、在 0(包括)和指定值(不包括)之间均匀分布的 int
值。 |
long |
nextLong()
返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 long 值。 |
void |
setSeed(long seed)
使用单个 long 种子设置此随机数生成器的种子。 |
3.ThreadLocalRandom类
是java7新增类,random类的子类,在多线程并发情况下相对于random可以减少多线程资源竞争,保证了线程安全问题。
ThreadLocalRandom不是直接用new实例化,而是第一次使用其静态方法current()。


4.UUID类
通用唯一识别: 在一台机器上生成的数字,它保证对在同一时空中 的所有机器都是唯一的。
* UUID是一个128位长的数字,一般用16进制表示。算法的核心思想是结合机器的网卡, 当地时间、一个随机数来生成UUID。
案例:生成验证码
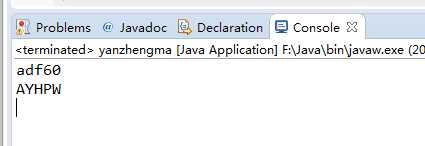
import java.util.Random; import java.util.UUID; public class yanzhengma { public static void main(String[] args) { //生成一个5位数的随机数 //截取UUID生成字符串的前五位 String Num=UUID.randomUUID().toString().substring(0, 5); System.out.println(Num); //第二种方式 String str="ABCDEFGHYJKLMNOPQISTUVWXYZ"; str+=str.toLowerCase(); str+="0123456789"; //将大小写字母和数字拼接起来 StringBuilder sb=new StringBuilder(5); for(int i=0;i<5;i++) { //每次随机在这个拼接好的字符串中随机取出一个字符 char ch=str.charAt(new Random().nextInt(str.length()));//index必须在[0,str.lenth()]之间 //用StringBuilder进行拼接 sb.append(ch); } System.out.println(sb); } }
二、正则表达式
* 主要用于(匹配判断,分割操作,替换操作),最多的是匹配判断




来看一个案例:
判断一个字符串全部由数字组成
public class Regex { public static void main(String[] args) { String input="1235sa65"; boolean ok=isNumber(input); System.out.println(ok); } //判断一个字符串全部由数字组成 private static boolean isNumber(String str) { char[] arr=str.toCharArray(); for(char c:arr) { if(c<‘0‘||c>‘9‘) { return false; } } return true; } }
是不是有些麻烦?
下边用正则表达式
public class Regex { public static void main(String[] args) { String input="1235sa65"; System.out.println("123sa456".matches("\\d*")); } }
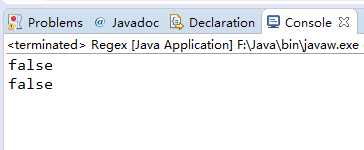 两个的结果是一样的,用正则表达式简化了代码,更优化了。
两个的结果是一样的,用正则表达式简化了代码,更优化了。
下边我们看看Pattern类中的方法
| 方法摘要 | |
|---|---|
static Pattern |
compile(String regex) 将给定的正则表达式编译到模式中。 |
static Pattern |
compile(String regex,
int flags) 将给定的正则表达式编译到具有给定标志的模式中。 |
int |
flags()
返回此模式的匹配标志。 |
Matcher |
matcher(CharSequence input)
创建匹配给定输入与此模式的匹配器。 |
static boolean |
matches(String regex, CharSequence input)
编译给定正则表达式并尝试将给定输入与其匹配。 |
String |
pattern()
返回在其中编译过此模式的正则表达式。 |
static String |
quote(String s)
返回指定 String 的字面值模式 String。 |
String[] |
split(CharSequence input)
围绕此模式的匹配拆分给定输入序列。 |
String[] |
split(CharSequence input,
int limit) 围绕此模式的匹配拆分给定输入序列。 |
String |
toString()
返回此模式的字符串表示形式。 |
常用matches和split还有toString还有一个replace和replaceAll
一个案例来搞懂,判断手机号码
1:要求为11位数字
2:第1位为1,第2位为3、4、5、7、8中的一个,后面9位为0到9之间的任意数字。
 结果为:true
结果为:true
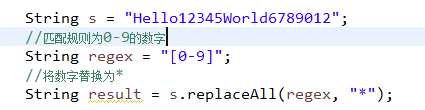
再来一个替换的案例
把文字中的数字替换成*
标签:acea info lan pen 文字 均值 时空 lag pac
原文地址:https://www.cnblogs.com/LuckyGJX/p/9031418.html