标签:特征 代码 部分 pdf 根据 conv2 code south 向量
在这里,先介绍几个概念,也是图像处理当中的最常见任务.
首先需要了解一下什么是语义分割(semantic segmentation).
语义分割,简单来说就是给定一张图片,对图片中的每一个像素点进行分类
比如说下图,原始图片是一张街景图片,经过语义分割之后的图片就是一个包含若干种颜色的图片,其中每一种颜色都代表一类.
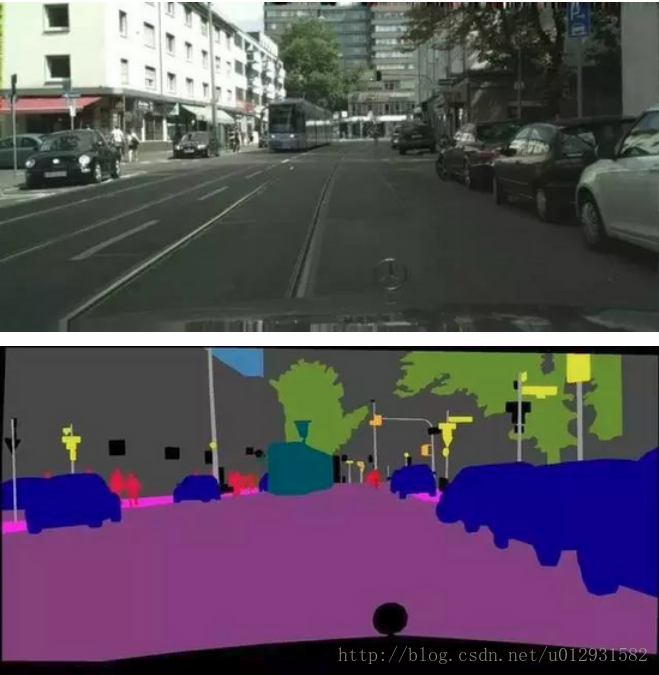
图像语义分割是AI领域中一个重要的分支,是机器视觉技术中关于图像理解的重要一环.
有几个比较容易混淆的概念,分别是目标检测(object detection),目标识别(object recognition),实例分割(instance segmentation),下面来一一介绍.
目标检测,就是在一张图片中找到并用box标注出所有的目标.
注意,目标检测和目标识别不同之处在于,目标检测只有两类,目标和非目标.
如下图所示:

目标识别,就是检测和用box标注出所有的物体,并标注类别.
如下图所示:

实例分割,对图像中的每一个像素点进行分类,同种物体的不同实例也用不同的类标进行标注.
下图展示了语义分割和实例分割之间的区别:
中间是实例分割,右图是语义分割.

PASCAL VOC是一个正在进行的,目标检测,目标识别,语义分割的挑战.
这里是它的主页,这里是leader board,很多公司和团队都参与了这个挑战,很多经典论文都是采用这个挑战的数据集和结果发表论文,包括RCNN,FCN等.
关于这个挑战,有兴趣的同学可以读一下这篇论文
FCN,全卷积神经网络,是目前做语义分割的最常用的网络.
Fully convolutional networks for semantic segmentation 是2015年发表在CVPR上的一片论文,提出了全卷积神经网络的概念,差点得了当前的最佳论文,没有评上的原因好像是有人质疑,全卷积并不是一个新的概念,因为全连接层也可以看作是卷积层,只不过卷积核是原图大小而已.
在一般的卷积神经网络中,一般结构都是前几层是卷积层加池化,最后跟2-3层的全连接层,输出分类结果,如下图所示:
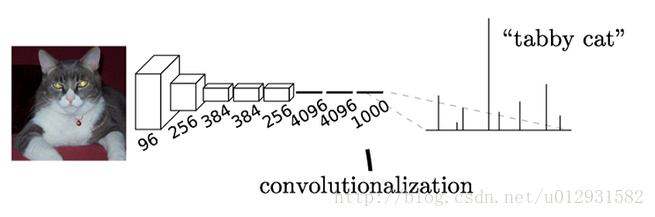
这个结构就是AlexNet的结构,用来进行ImageNet中的图片分类,最后一层是一个输出为1000*1向量的全连接层,因为一共有1000个类,向量中的每一维都代表了当前类的概率,其中tabby cat的概率是最大的.
而在全卷积神经网络中,没有了全连接层,取而代之的是卷积层,如下图所示:
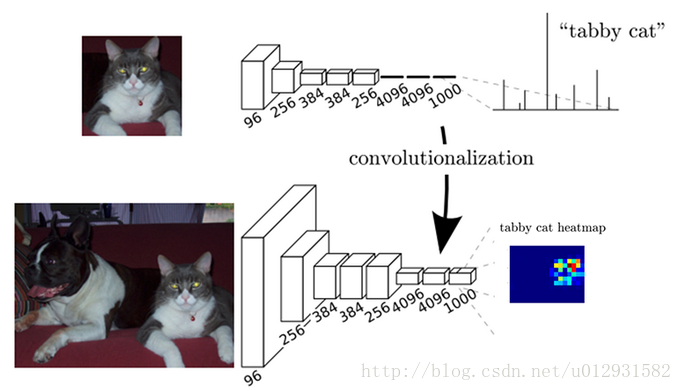
最后一层输出的是1000个二维数组,其中每一个数组可以可视化成为一张图像,图中的每一个像素点的灰度值都是代表当前像素点属于该类的概率,比如在这1000张图像中,取出其中代表tabby cat的概率图,颜色从蓝到红,代表当前点属于该类的概率就越大.
可以看出FCN与CNN之间的区别就是把最后几层的全连接层换成了卷积层,这样做的好处就是能够进行dense prediction.
从而可是实现FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
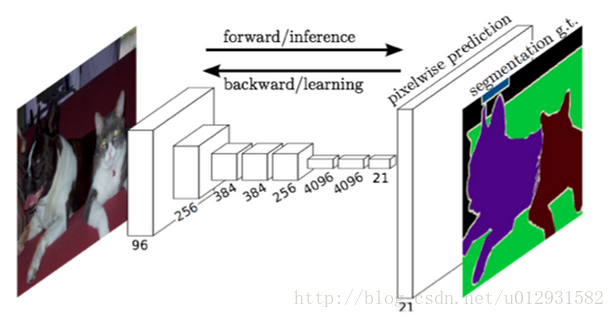
在进行语义分割的时候,需要解决的一个重要问题就是,如何把定位和分类这两个问题结合起来,毕竟语义分割就是进行逐个像素点的分类,就是把where和what两个问题结合在了一起进行解决.
在前面几层卷积层,分辨率比较高,像素点的定位比较准确,后面几层卷积层,分辨率比较低,像素点的分类比较准确,所以为了更加准确的分割,需要把前面高分辨率的特征和后面的低分辨率特征结合起来.
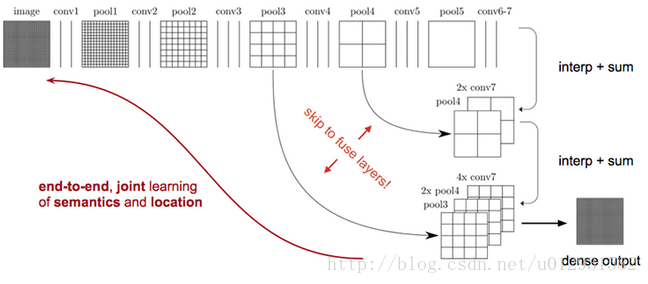
如上图所示,对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时进行32倍的上采样可以得到原图大小,这个时候得到的结果就是叫做FCN-32s.
这个时候可以看出,FCN-32s结果明显非常平滑,不精细. 针对这个问题,作者采用了combining what and where的方法,具体来说,就是在FCN-32s的基础上进行fine tuning,把pool4层和conv7的2倍上采样结果相加之后进行一个16倍的上采样,得到的结果是FCN-16s.
之后在FCN-16s的基础上进行fine tuning,把pool3层和2倍上采样的pool4层和4倍上采样的conv7层加起来,进行一个8倍的上采样,得到的结果就是FCN-8s.
可以看出结果明显是FCN-8s好于16s,好于32s的.

上图从左至右分别是原图,FCN-32s,FCN-16s,FCN-8s.
FCN的优点,能够end-to-end, pixels-to-pixels,而且相比于传统的基于cnn做分割的网络更加高效,因为避免了由于使用像素块而带来的重复存储和计算卷积的问题。
FCN的缺点也很明显,首先是训练比较麻烦,需要训练三次才能够得到FCN-8s,而且得到的结果还是不精细,对图像的细节不够敏感,这是因为在进行decode,也就是恢复原图像大小的过程时,输入上采样层的label
map太稀疏,而且上采样过程就是一个简单的deconvolution.
其次是对各个像素进行分类,没有考虑到像素之间的关系.忽略了在通常的基于像素分类的分割方法中使用的空间规整步骤,缺乏空间一致性.
U-net 是基于FCN的一个语义分割网络,适合用来做医学图像的分割.
下面是U-net 的结构图:
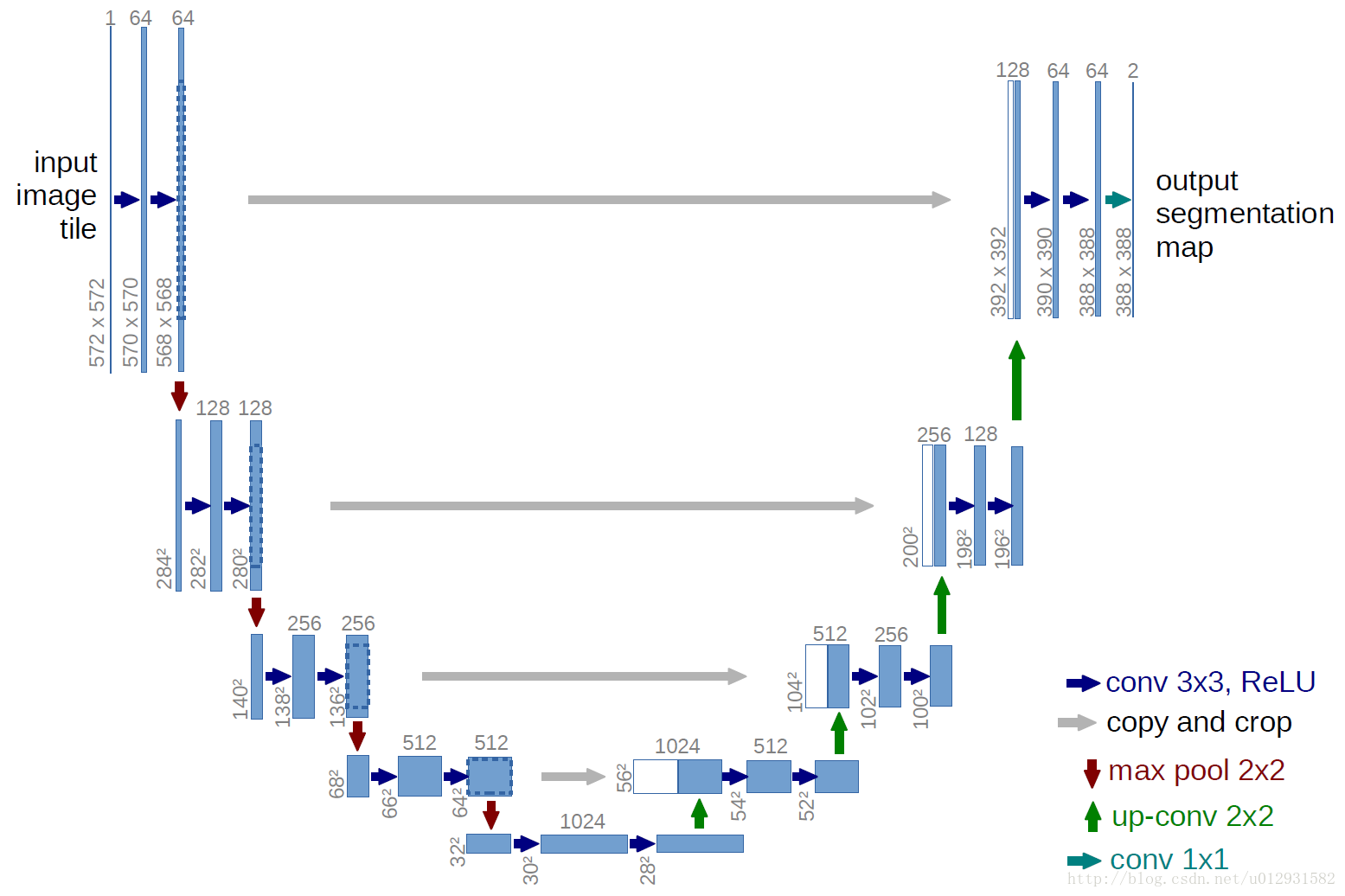
结构比较清晰,也很优雅,成一个U状.
和FCN相比,结构上比较大的改动在上采样阶段,上采样层也包括了很多层的特征.
还有一个比FCN好的地方在于,Unet只需要一次训练,FCN需要三次训练.
我实现了unet的网络结构,代码在: https://github.com/zhixuhao/unet,
是用keras实现的,关于数据集和训练测试,可以参考我这一篇博文: http://blog.csdn.net/u012931582/article/details/70215756
SegNet 是一个encoder-decoder结构的卷积神经网络.
这里是官方网站:http://mi.eng.cam.ac.uk/projects/segnet/
SegNet 的结构如下所示:
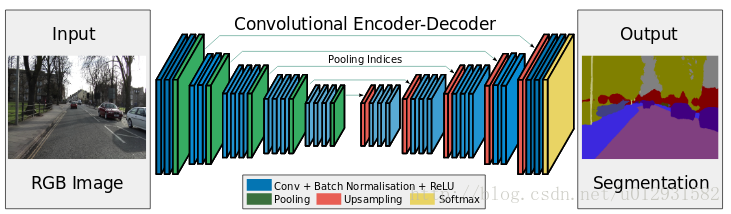
可以看出,整个结构就是一个encoder和一个decoder.前面的encoder就是采用的vgg-16的网络结构,而decoder和encoder基本上就是对称的结构.
SegNet和FCN最大的不同就在于decoder的upsampling方法,上图结构中,注意,前面encoder每一个pooling层都把pooling indices保存,并且传递到后面对称的upsampling层. 进行upsampling的过程具体如下:
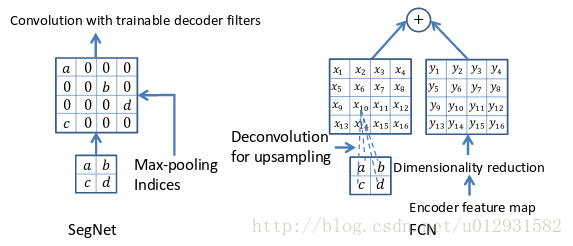
左边是SegNet的upsampling过程,就是把feature map的值 abcd, 通过之前保存的max-pooling的坐标映射到新的feature map中,其他的位置置零.
右边是FCN的upsampling过程,就是把feature map, abcd进行一个反卷积,得到的新的feature map和之前对应的encoder feature map 相加.
文章中说,他们用了CamVid 这个数据集进行了一下,这个数据集主要是街景图片,总共有11个类,367张训练图片,233张测试图片,是一个比较小的数据集.
下图是分割结果的对比:
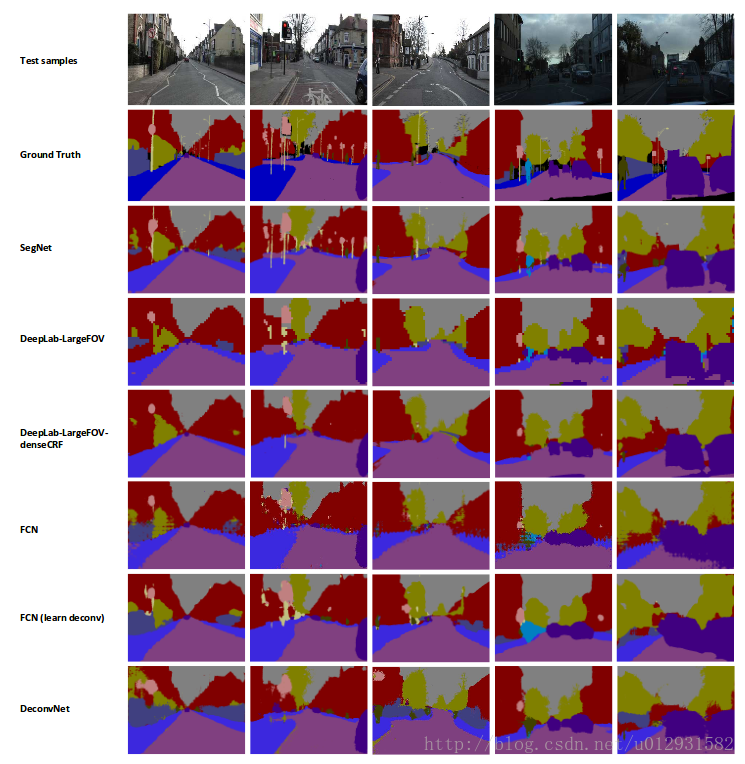
DeconvNet 是一个convolution-deconvolution结构的神经网络,和SegNet非常相似
是一篇2015年ICCV上的文章: Learning Deconvolution Network for Semantic Segmentation
下面是它的结构图:
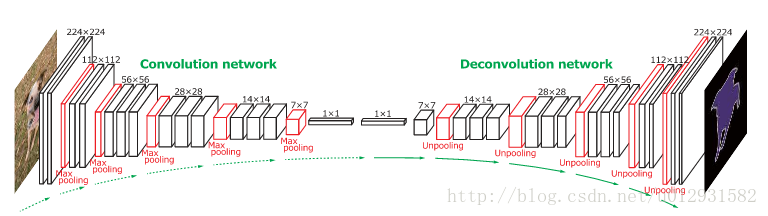
前面的convolution network 和SegNet的encoder部分是一样的,都是采用了VGG16的结构,只不过DeconvNet后面添加了两个全连接层.
在进行upsampling的时候,SegNet和DeconvNet基本上是一致的,都是进行了unpooling,就是需要根据之前pooling时的位置把feature map的值映射到新的feature map上,unpooling 之后需要接一个反卷积层.
可以看出,这些网络的结构都是非常相似的,都是基于encoder-decoder结构的,只不过说法不同,前面是一些卷积层,加上池化层,后面的decoder其实就是进行upsampling,这些网络的最主要区别就是upsampling的不同.
FCN进行upsampling的方法就是对feature map进行反卷积,然后和高分辨率层的feature map相加.
Unet进行upsampling的方法和FCN一样.
DeconvNet进行upsampling的方法就是进行unpooling,就是需要根据之前pooling时的位置把feature map的值映射到新的feature map上,unpooling 之后需要接一个反卷积层.
SegNet进行upsampling的方法和DeconvNet一样.
标签:特征 代码 部分 pdf 根据 conv2 code south 向量
原文地址:https://www.cnblogs.com/bonelee/p/9031754.html