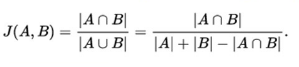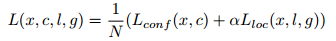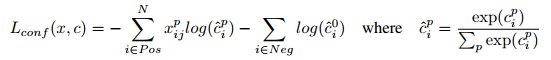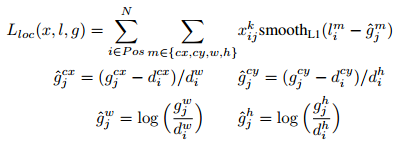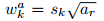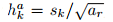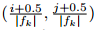标签:需要 MF 分割 中心 art 常见 处理 问题 nbsp
from:https://blog.csdn.net/u013989576/article/details/73439202
目前,常见的目标检测算法,如Faster R-CNN,存在着速度慢的缺点。该论文提出的SSD方法,不仅提高了速度,而且提高了准确度。

该论文的主要贡献:
1. 提出了SSD目标检测方法,在速度上,比之前最快的YOLO还要快,在检测精度上,可以和Faster RCNN相媲美
2. SSD的核心是在特征图上采用卷积核来预测一系列default bounding boxes的类别分数、偏移量
3. 为了提高检测准确率,在不同尺度的特征图上进行预测,此外,还得到具有不同aspect ratio的结果
4. 这些改进设计,实现了end-to-end训练,并且,即使图像的分辨率比较低,也能保证检测的精度
5. 在不同的数据集,如:PASCAL VOC、MS COCO、ILSVRC,对该方法的检测速度、检测精度进行了测试,并且与其他的方法进行了对比。
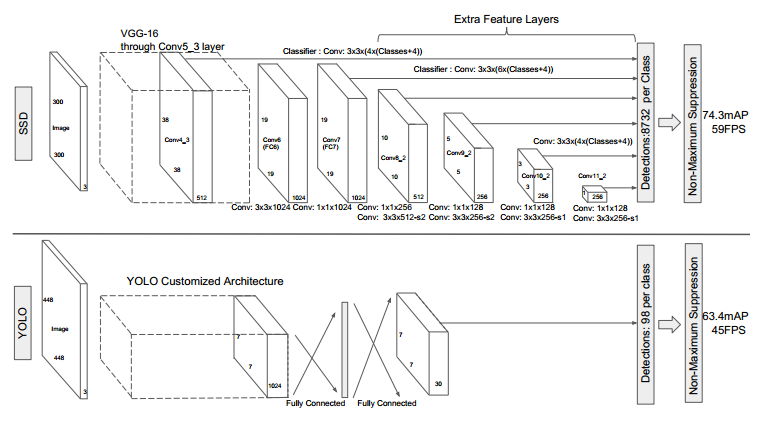
SSD模型结构:
刚开始的层使用图像分类模型中的层,称为base network,在此基础上,添加一些辅助结构:
1. Mult-scale feature map for detection
在base network后,添加一些卷积层,这些层的大小逐渐减小,可以进行多尺度预测
2. Convolutional predictors for detection
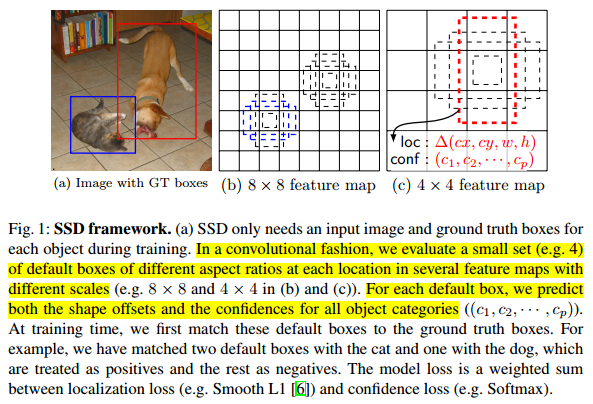
每一个新添加的层,可以使用一系列的卷积核进行预测。对于一个大小为m*n、p通道的特征层,使用3*3的卷积核进行预测,在某个位置上预测出一个值,该值可以是某一类别的得分,也可以是相对于default bounding boxes的偏移量,并且在图像的每个位置都将产生一个值,如图2所示。
3. Default boxes and aspect ratio
在特征图的每个位置预测K个box。对于每个box,预测C个类别得分,以及相对于default bounding box的4个偏移值,这样需要(C+4)*k个预测器,在m*n的特征图上将产生(C+4)*k*m*n个预测值。这里,default bounding box类似于FasterRCNN中anchors,如图1所示。
个人感觉SSD模型与Faster RCNN中的RPN很类似。SSD中的dafault bounding box类似于RPN中的anchor,但是,SSD在不同的特征层中考虑不同的尺度,RPN在一个特征层考虑不同的尺度。
SSD模型训练:
1. Matching strategy
将每个groundtruth box与具有最大jaccard overlap的defalult box进行匹配, 这样保证每个groundtruth都有对应的default box;并且,将每个defalut box与任意ground truth配对,只要两者的jaccard overlap大于某一阈值,本文取0.5,这样的话,一个groundtruth box可能对应多个default box。
jaccard overlap的计算:
2. Training objective
Let 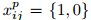
损失函数的计算类似于Fast RCNN中的损失函数,总的损失函数是localization loss (loc) 和 confidence loss (conf) 的加权和,如下:
confidence loss:
localization loss (loc) :
其中,(gcx, gcy, gw, gh)表示groundtruth box,(dcx, dcy, dw, dh)表示default box,(lcx, lcy, lw, lh)表示预测的box相对于default box的偏移量。
3. Choosing scales and aspect ratios for default boxes
为了处理不同尺度的物体,一些文章,如:Overfeat,处理不同大小的图像,然后将结果综合。实际上,采用同一个网络,不同层上的feature map,也能达到同样的效果。图像分割算法FCN表明,采用低层的特征图可以提高分割效果,因为低层保留的图像细节信息比较多。因此,该论文采用lower feature map、upper feature map进行预测。
一般来说,CNN的不同层有着不同的感受野。然而,在SSD结构中,default box不需要和每一层的感受野相对应,特定的特征图负责处理图像中特定尺度的物体。在每个特征图上,default box的尺度计算如下:
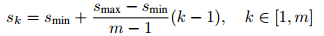
其中,smin = 0.2,smax = 0.9
default box的aspect ratios 有:{1, 2, 3,1/2,1/3},对于 aspect ratio = 1,额外增加一个default box,该box的尺度为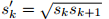
每一个default box,宽度、高度、中心点计算如下:
4. Hard negative mining
经过matching后,很多default box是负样本,这将导致正样本、负样本不均衡,训练难以收敛。因此,该论文将负样本根据置信度进行排序,选取最高的那几个,并且保证负样本、正样本的比例为3:1。
5. Data augmentation
为了使得模型对目标的尺度、大小更加鲁棒,该论文对训练图像做了data augmentation。每一张训练图像,由以下方法随机产生:
1)使用原始图像
2)采样一个path,与目标的最小jaccard overlap为0.1、0.3、0.5、0.7、0.9 (这个具体怎么做呢???)
3)随机采样一个path
采样得到的path,其大小为原始图像的[0.1, 1],aspect ratio在1/2与2之间。当groundtruth box的中心在采样的path中时,保留重叠部分。经过上述采样之后,将每个采样的pathresize到固定大小,并以0.5的概率对其水平翻转。
参考博客:http://blog.csdn.net/smf0504/article/details/52745070
标签:需要 MF 分割 中心 art 常见 处理 问题 nbsp
原文地址:https://www.cnblogs.com/bonelee/p/9033952.html