标签:strong get VRM title city 状态 login 拒绝 source
在接口测试中或者说在网络爬虫中,urllib2库是必须要掌握的一个库,当然还有优秀的requests库,今天重点来说urllib2库在接口测试中的应用。
urllib2定义了很多的函数和类,这些函数和类能够帮助我们在复杂情况下获取URLS的内容。这些情况包含了对headers的添加,cookie的处理,代理,
超时,鉴权等的处理。如果想详细的了解urllib2库,建议到官方查看,官方地址:https://docs.python.org/2/library/urllib2.html。查看urllib2库的详细
的帮助文档,见执行的代码:
#!/usr/bin/env python #-*-coding:utf-8-*- import urllib2 print type(help(urllib2))
首先我们来看一个完整的请求和响应内容,然后通过urllib2的库来实现这样的一个过程,我们访问http://m.cyw.com/切换城市,见抓取的信息,见截图:
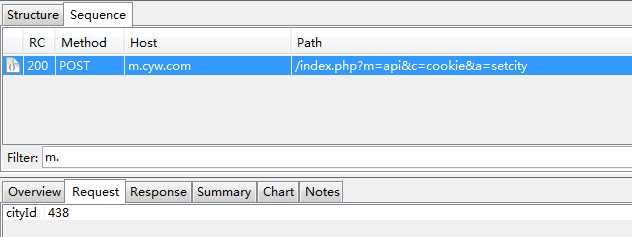
见客户端发送请求后,服务端响应回复的内容截图:
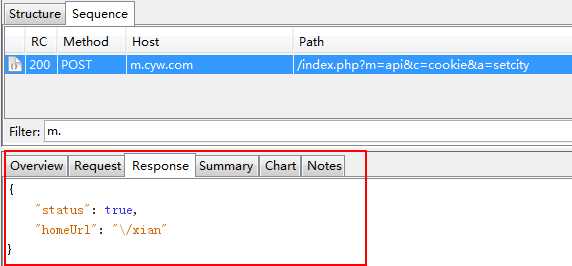
在如上的截图中,我们知道了请求的URL,方法以及请求的参数,下来我们使用urllib2的库来实现一个完整的请求过程和响应内容,见实现的代码:
# !/usr/bin/env python # -*-coding:utf-8-*- import urllib2 import urllib def selCity(): ‘‘‘使用urllib2实现一个城市选择的完整请求和响应内容‘‘‘ data = urllib.urlencode({‘cityId‘: ‘438‘}) r = urllib2.urlopen( url=‘http://m.cyw.com/index.php?m=api&c=cookie&a=setcity‘, data=data) print u‘http的状态码:‘, r.getcode() print u‘响应内容:‘, r.read() 调用如上的函数后,见执行的结果: http的状态码: 200 响应内容: {"status":true,"homeUrl":"\/xian"} 在接口的测试中,客户端向服务端发起请求的时候,需要添加header这样服务端,否则服务端会拒绝客户端的请求,那么在urllib2库中,如何添加header了,见如下的案例代码: # !/usr/bin/env python # -*-coding:utf-8-*- import urllib2 import urllib def login(): ‘‘‘通过一个接口来测试请求头headers的处理‘‘‘ headers= { ‘Content-Type‘: ‘application/json; charset=UTF-8‘, ‘Parkingwang-Client-Source‘: ‘ParkingWangAPIClientWeb‘} data=urllib.urlencode( {"username": "autoapi", "password": "8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92", "role": 2} ) request=urllib2.Request(url=‘https://ecapi.parkingwang.com/v4/login‘, data=data, headers=headers) r=urllib2.urlopen(request) print r.getcode() print r.read() login()
发送一个request的请求,然后请求资源,在该实例中,如果没有headers,发送请求,会显示404的错误信息,见不带header发送请求后服务端的响应内容:
# !/usr/bin/env python # -*-coding:utf-8-*- import urllib2 import urllib def login(): ‘‘‘通过一个接口来测试请求头headers的处理‘‘‘ data=urllib.urlencode( {"username": "autoapi", "password": "8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92", "role": 2}) r=urllib2.urlopen(url=‘https://ecapi.parkingwang.com/v4/login‘, data=data) print r.getcode login()
见执行函数后的错误信息,显示为:
File "C:\Python27\lib\urllib2.py", line 556, in http_error_default
raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)
urllib2.HTTPError: HTTP Error 404: Not Found
下来来看urllib2的库对cookie的处理,对cookie的处理分为二种方式,一种是自动处理cookie,会使用到cookielib,另外一种是自己设置添加cookie,
我们先看自动处理cookie的一种方式,我们模拟请求百度,然后循环看百度的cookie,见实现的代码:
# !/usr/bin/env python # -*-coding:utf-8-*- import urllib2 import urllib def baidu(): ‘‘‘通过一个例子来看cookie的处理‘‘‘ import cookielib # 对cookie进行管理 cookie = cookielib.CookieJar() # 对cookie进行自动管理 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) r = opener.open(‘http://www.baidu.com‘) print r.getcode() for item in cookie: print item
调用函数后,见执行后打印的内容:
200
<Cookie BAIDUID=8C777D00B26945AAC27AA4952BC00CE4:FG=1 for .baidu.com/>
<Cookie BIDUPSID=8C777D00B26945AAC27AA4952BC00CE4 for .baidu.com/>
<Cookie H_PS_PSSID=1460_21087 for .baidu.com/>
<Cookie PSTM=1519292146 for .baidu.com/>
<Cookie BDSVRTM=0 for www.baidu.com/>
<Cookie BD_HOME=0 for www.baidu.com/>
下面我们来看自己设置添加cookie的方式,我们知道在登录一个系统成功后,再去请求系统中的信息,如果不带cookie系统会拒绝客户端的请求,
理由很简单就是服务端要确保访问系统的用户是经过登录系统成功后才可以具备权限访问,这样也是安全角度的考虑,见如下通过自己设置添加cookie
实现的方式,见实现的代码:
# !/usr/bin/env python # -*-coding:utf-8-*- import urllib2 import urllib def cookie(): ‘‘‘通过自己设置添加cookie‘‘‘ opener=urllib2.build_opener() opener.addheaders.append((‘Cookie‘,‘_gitlab_session=ec998d5f778e2929e5235d24250e94cd;
session=.eJwdzkFrwkAQhuG_UubsQaOnQC8SXSzMBGWSMHMRGtPujsklVmJW_O_d9vDBd3ngfcL5a-xuHvKf8d4
t4BwukD_h7RNyoHhYY3GdJDs-tKnWyrJRd3xgs8tKh0t1tZWOTNkb8iWg9b0OJ4_Z3v4-udqjVRmlCScXt6FkH4j
blZhMYocJ48mkkZlcNYt9z8R-kJgst1EZl8jbQMXHQLbvpcGoJrPydUNFmxp2ydVBGN_htYD7rRv_-2EFr1_dGUj
6.DVcwRw.mOjs2qGQ5W4mOHn4yiB3pkqMi0A‘)) request=urllib2.Request(‘http://117.39.63.66:20080/depot/parks?start=0&length=10&draw=1‘) r=opener.open(request) print r.getcode() print r.headers print r.read()
下来来看超时的处理,在实际的请求中,由于网络等因素,导致请求失败,会报socket.timeout: timed out的错误,如果出现这样的错误说明请求超时,
我们需要在请求的时候对处理做处理,先来模拟超时的请求,如模拟超时的代码:
# !/usr/bin/env python # -*-coding:utf-8-*- import urllib2 import urllib def timeout(): ‘‘‘通过一个例子来看超时‘‘‘ r=urllib2.urlopen(‘http://www.baidu.com‘,timeout=0.01) print r.getcode() print r.read() timeout()
见执行后打印的错误信息:
File "C:\Python27\lib\socket.py", line 480, in readline
data = self._sock.recv(self._rbufsize)
socket.timeout: timed out
下来我们对该错误进行处理,在请求的时候处理下超时的情况,见处理后的代码:
# !/usr/bin/env python # -*-coding:utf-8-*- import urllib2 import urllib def timeout(): ‘‘‘通过一个例子来看超时‘‘‘ r=urllib2.urlopen(‘http://www.baidu.com‘,timeout=2) print r.getcode() print r.read() timeout()
标签:strong get VRM title city 状态 login 拒绝 source
原文地址:https://www.cnblogs.com/jason89/p/9033922.html