标签:text elf 名称 img scrapy yield http 技术 list

先上图:
scrapy框架爬取某表情网站表情图【源码+GIF表情包下载】
python源代码

import scrapy
import os,sys
import requests
import re
class scrapyone(scrapy.Spider):
name = "stackone"
start_urls = ["http://qq.yh31.com/ql/bd/"]
def parse(self,response):
hrf=response.xpath(‘//*[@id="main_bblm"]/div[2]/dl/dd/li‘)
for li in hrf:
item={}
href=li.xpath(‘a/@href‘).extract()
hreftext=li.xpath(‘a/text()‘).extract()
full_url = ‘http://qq.yh31.com‘+ ‘‘.join(list(href))
hreftext=‘‘.join(list(hreftext))
#文件夹名称
if hreftext==‘>更多>‘:
continue
path = ‘C:\GIF‘
if not os.path.exists(path):
os.makedirs(path)
item[‘dirname‘]=hreftext
yield scrapy.Request(url=full_url,meta={‘key‘:item},callback = self.parse1)
def parse1(self,response):
ite={}
full_url=[]
url1 = response.xpath(‘//*[@id="pe100_page_infolist"]/a[2]/@href‘).extract()
url2 = response.xpath(‘//*[@id="pe100_page_infolist"]/a[2]/@href‘).re(‘\d+‘)
url1 = ‘‘.join(url1)
url1 = url1.split(‘_‘)
url2 = ‘‘.join(url2)
ite[‘dirn‘]=response.meta[‘key‘][‘dirname‘]
for i in range(1,int(url2)+1):
full_url=‘http://qq.yh31.com‘+url1[0]+‘_‘+str(i)+‘.html‘
#print(full_url)
yield scrapy.Request(url=full_url,meta={‘key1‘:ite},callback = self.parse2)
def parse2(self,response):
p1=response.meta[‘key1‘][‘dirn‘]
resp = response.xpath(‘//*[@id="main_bblm"]/div[1]/li/dt/a‘)
path = ‘C:\GIF\\‘+‘‘.join(p1)
if not os.path.exists(path):
os.makedirs(path)
for lst in resp:
alt = lst.xpath(‘img/@alt‘).extract()
src = lst.xpath(‘img/@src‘).extract()
src = ‘http://qq.yh31.com‘+ ‘‘.join(list(src))
alt = ‘‘.join(list(alt))
html=requests.get(src)
with open(path+‘\\‘+alt+‘.gif‘, ‘wb‘) as file:
file.write(html.content)
脚本执行方式:cmd-->切换到脚本所在目录-->scrapy runspider xxxx.py
执行后会自动根据GIF分类在c:\gif文件夹下建立相应文件夹存储gif图片
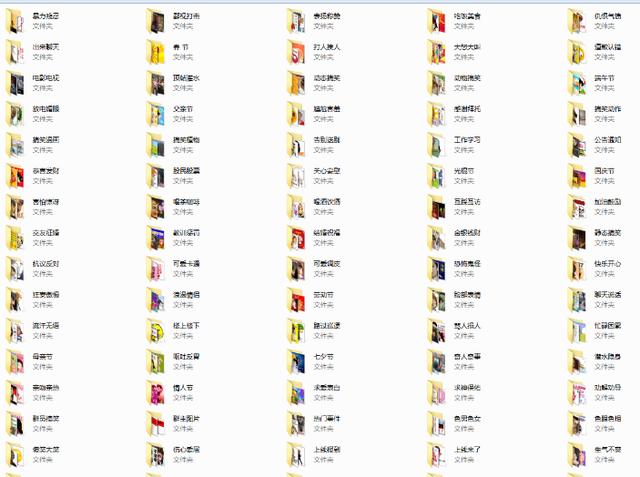
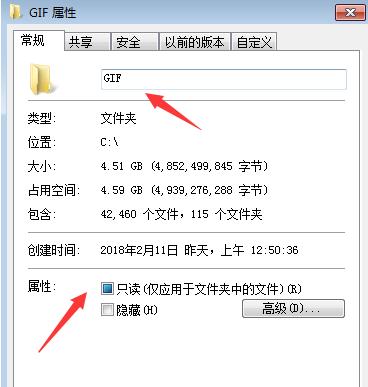

标签:text elf 名称 img scrapy yield http 技术 list
原文地址:https://www.cnblogs.com/xinshiye/p/9037844.html