标签:int factor family shuff 传统 border class ble ati
MobileNet引入了传统网络中原先采用的group思想,即限制滤波器的卷积计算只针对特定的group中的输入,从而大大降低了卷积计算量,提升了移动端前向计算的速度。
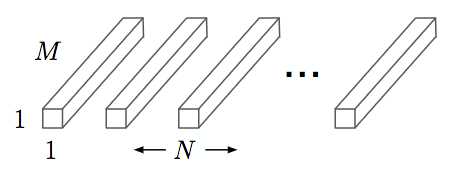
MobileNet借鉴factorized convolution的思想,将普通卷积操作分为两部分:
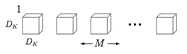
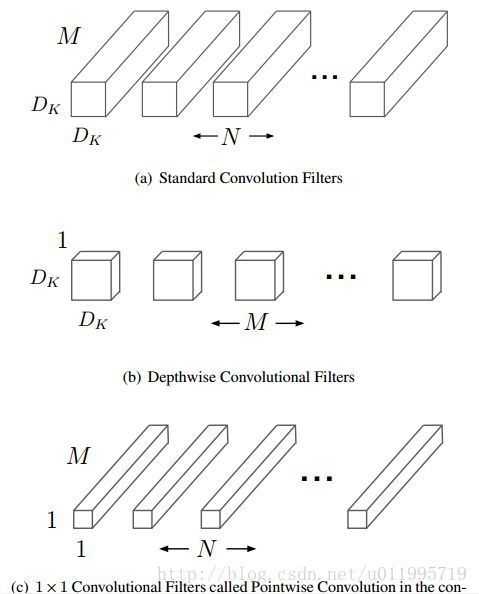
+Depthwise convolution的计算复杂度为 DKDKMDFDF,其中DF是卷积层输出的特征图的大小。
+Pointwise Convolution的计算复杂度为 MNDFDF
+上面两步合称depthwise separable convolution
+标准卷积操作的计算复杂度为DKDKMNDFDF
因此,通过将标准卷积分解成两层卷积操作,可以计算出理论上的计算效率提升比例:
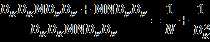
对于3x3尺寸的卷积核来说,depthwise separable convolution在理论上能带来约8~9倍的效率提升。
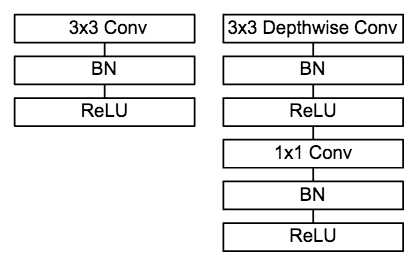
MobileNet的卷积单元如上图所示,每个卷积操作后都接着一个BN操作和ReLU操作。在MobileNet中,由于3x3卷积核只应用在depthwise convolution中,因此95%的计算量都集中在pointwise convolution 中的1x1卷积中。而对于caffe等采用矩阵运算GEMM实现卷积的深度学习框架,1x1卷积无需进行im2col操作,因此可以直接利用矩阵运算加速库进行快速计算,从而提升了计算效率。
标签:int factor family shuff 传统 border class ble ati
原文地址:https://www.cnblogs.com/CodingML-1122/p/9043078.html